Japan
サイト内の現在位置を表示しています。
社会インフラの最適運用を支援する論理思考AI
人とともに未来を創る最新のAI技術NECで取り組んでいるプラント運転支援技術について紹介します。本技術は、プラントの運用手順書や設計情報を知識として用いてプラントの挙動を定性的に推論する論理推論と、プラントシミュレータを環境として用いた強化学習とを組み合わせた技術で、複雑なプラントの最適操作を現実的な時間で学習することが可能となります。本稿では、技術の概略と化学プラントシミュレータを用いた実証結果について紹介します。
1. はじめに
化学プラントや発電プラントといった社会インフラの運転は多くの部分が自動化されているものの、スタートアップ、外乱発生時の対応、スペック変更、シャットダウンといった非定常時においては、人手による操作が必要となっています。こうした操作は、複雑さや社会的影響の大きさから、経験豊富な熟練運転員に依存していることが多いのですが、熟練運転員の引退に伴う人材不足を補う観点でAIによる運転支援が求められています。
2. AI適用の課題
運転手順を学習するAIとして、強化学習が近年盛んに研究開発されています。これはシミュレーション環境でさまざまな操作を試行錯誤的に行いながらデータを集め、運転状態の良さを示す報酬関数を最大化するように最適な操作を学習する手法です。しかし、大規模なプラントを対象とする強化学習を考えた場合、プラントには多くの制御点があり、それぞれ制御量として連続値を与える必要があるため、学習の際の探索範囲が膨大となり現実的な時間で学習を完了させることが困難となる課題があります。また、一般的な強化学習では、なぜその操作をするのかの理由は出力しません。そうしたブラックボックス型のAIでは化学プラントや発電プラントといった社会的影響の大きな施設の運転では事業者の説明責任を果たすことができず、実用化の大きな障害となっています。
3. 論理思考AIによるプラント運転支援
前述した課題を解決するため、NECでは論理のアプローチとデータのアプローチを融合させた論理思考AIを開発しました。図1が論理思考AIの概要図です。論理思考AIでは2階層で運用手順の導出を行います。まず、論理推論によって運用手順のマニュアルやプラントの設計、配管情報をもとに、運用手順候補の絞り込みを行います。次に、絞り込まれた手順に従って詳細な操作量を強化学習とプラントシミュレータを用いて決定します。論理推論による絞り込みを行うことで強化学習での探索範囲を限定することができ、現実的な時間で最適な手順を学習することが可能となります。論理推論はマニュアルや設計情報といった運転員が理解できる情報を知識として利用するため、運転員に対して、なぜその操作をするのかの根拠を提示することができ、運転員が納得してAIが提示した運用手順を実行することが可能となります。以下、論理思考AIの要素技術を紹介します。
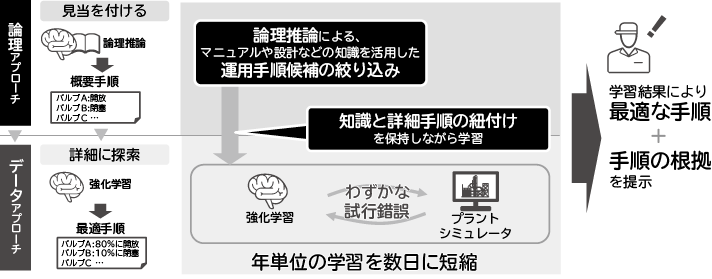
3.1 論理推論
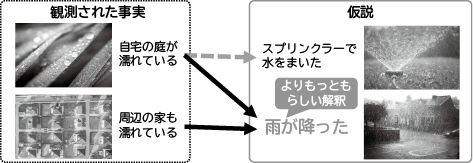
本技術で用いる論理推論とは、観測された事実と知識を照らし合わせ、説明として最も妥当な仮説を推論する技術です。図2の例は、「よく晴れた朝、庭の芝が濡れていたとき、それだけ見ると早朝にスプリンクラーが動いて水をまいたからと思うかもしれません。しかし、周りの家を見回してみると、同じように濡れています。それならば、スプリンクラーで濡れたというより、雨が降って濡れたという方が妥当と考えられます。」といった仮説の推論を表しています。このように、論理推論では得られる事実からもっともらしい結論、解釈を推論することができます。これは、経験豊かな人が、知識を活用して素早く現状起きていることの可能性を推理することと同様のことを機械で行っているとも言えます。
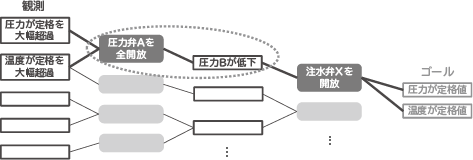
プラント運転の場合も同様の推論を行います(図3)。運用手順候補を絞り込むということは、今観測できている状態から、温度、圧力が定格値であるというゴール状態に到達する手順の組み合わせを発見することになります。マニュアルに一連の手順として定義されているものもありますが、状況によっては複数の手順を組み合わせないと解決できないこともあります。論理推論では、例えば、圧力弁Aを開放すると圧力Bが低下するという、操作と状態変化の組を知識(点線で囲った部分)として多数保持しており、それらをつないでゴール状態に到達する組み合わせを探索します。
このように論理推論ではプラントの挙動を定性的に扱い、運用手順を推論します。しかし、これだけでは操作量を定量的に決定することはできません。例えば、圧力弁を開放すると良いことは分かっても、何%開放すれば良いかは分かりません。そこで論理思考AIでは強化学習と組み合わせることで定量的な操作を決定します。
3.2 強化学習
強化学習は、ある環境内におけるエージェントが、現在の状態を観測し、取るべき行動を決定する関数(方策関数)を学習する機械学習手法です(図4)。エージェントは試行錯誤的に行動をし、経験を蓄積し、行動の結果得られる報酬の累積値が最大になるように方策関数を学習します。環境としてシミュレータを利用することで、実プラントでは試すことが難しいさまざまな状態での最適操作を学習することができます。強化学習では試行錯誤により最適な行動を学習するため、行動の次元(操作点の数)が増えると探索する範囲が爆発的に増えることになり、高い報酬を得られるまでに必要な学習時間が非常に長くなります。論理思考AIでは、論理推論により取りうる行動を制約することで探索範囲を絞り、現実的な時間での学習を可能としました。

4. 化学プラントシミュレータでの実証
論理思考AIの有効性を検証するため、ベンチマーク用の化学プラントシミュレータを用いた実証実験1)を行いました。
4.1 対象プラントシミュレータ
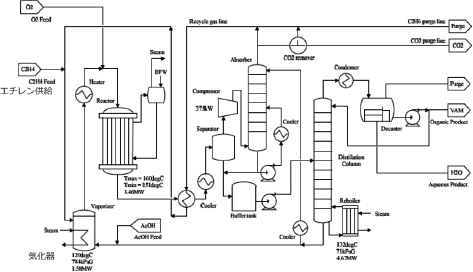
対象として用いたプラントシミュレータは、酢酸ビニルモノマー(VAM)製造プラントシミュレータです。このシミュレータは化学プラントの運転最適化を目的としたベンチマークシミュレータで、プロセスシステム工学第143委員会で構築、配布しています2)3)。本プラントでは、エチレンガス、酢酸、酸素を入力として、VAMと水を生成する合成反応を行い、VAMの分離を行います。プラントの規模としては、センサーが107個、PID制御器が45個、バルブが31個あり、原料の混合、反応、分離、リサイクルなどのプラント全体の挙動をカバーしたシミュレータです(図5)。
4.2 検証タスク
本シミュレータには人為的に外乱や故障を発生させる機能が実装されており、今回の実証では原料のエチレンガスの供給圧力が変化する外乱を発生させ、適切な対処操作を導出することができるかを検証しました。エチレンの供給圧力が変化すると原料を混ぜ合わせる気化器の圧力が変化し、適正な反応条件を満たせなくなり、結果として製品(VAM)のスペックを満たせず、生産ロスが生じます。そのため、気化器の圧力をなるべく早く定格の状態に戻すことで生産ロスを回避することが必要となります。
この対処操作を一般的な強化学習手法であるProximal Policy Optimization(PPO)法4)によって学習させた場合、操作対象のバルブが31個もあるため、試行錯誤に膨大なシミュレーションが必要となり、学習が完了しませんでした。
4.3 論理思考AIによる対処操作導出
論理思考AIでは、まず論理推論によって操作対象となるバルブの特定が行われます。論理推論の知識として、シミュレータに同梱されていた操作マニュアルや配管図を使いました。今回の場合は、エチレン供給部と気化器との間にあるバルブを操作することで気化器の圧力を調整できることが推論により特定されます。
次に、対象バルブをどのように操作すれば良いかを強化学習により導出します。事前に、強化学習エージェントをエチレン供給圧力をさまざまに変化させたシミュレーションを使って学習させておきます。論理推論によって調整すべきバルブが1つに特定されているため、少ない探索(シミュレーション回数)で学習を完了させることができました。この例では、PPO法を用いて数時間程度の学習で十分に最適な操作を学習することができました。
評価時には、強化学習エージェントに現在のセンサー情報を状態として与えることで、最適な行動(バルブ操作値)を導出することができます(図6)。
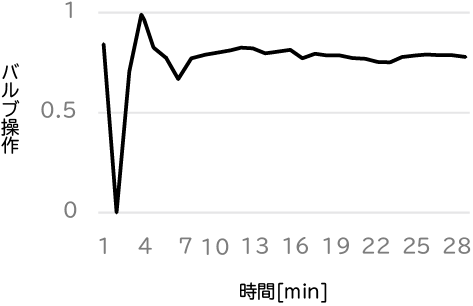
このようにして導出された操作を対象プラントで実行したときの気化器圧力の変化は、図7のようになりました。論理思考AIによる対処操作を実行した場合は、速やかに気化器圧力が定格値に復帰していることが分かります。一方で、人手による操作を行わず、PID制御に任せた運転を行った場合は、点線のような圧力変化となりました。徐々に定格状態に復帰するものの復帰までに多くの時間がかかり、この間生産ロスが発生することにつながります。

5. おわりに
本稿では、論理推論と強化学習を組み合わせた論理思考AIによるプラント運転支援について紹介しました。論理推論を利用することで、プラントの運用マニュアルや配管情報を知識として組み込み、強化学習単独よりも高速に最適操作を学習することが可能となります。また、化学プラントシミュレータを用いた実証実験により本技術の有効性を確認しました。今後は実際のプラントを対象とした実証を行い、実用化に向けた技術開発を進める予定です。
参考文献
- 1)S. Kubosawa et al. :Synthesizing Chemical Plant Operation Procedures using Knowledge, Dynamic Simulation and Deep Reinforcement Learning,Proceedings of the SICE Annual Conference 2018
- 2)Y. Machida et al. :Vinyl Acetate Monomer (VAM) Plant Model: A New Benchmark Problem for Control and Operation Study,Dynamics and Control of Process Systems, including Biosystems (DYCOPS-CAB2016)
- 3)
- 4)J. Schulman et al.:Proximal Policy Optimization Algorithms, arXiv preprint arXiv:1707.06347,2017
 株式会社オメガシミュレーション
株式会社オメガシミュレーション執筆者プロフィール
大西 貴士
セキュリティ研究所
主任
セキュリティ研究所
主任
窪澤 駿平
セキュリティ研究所
主任
セキュリティ研究所
主任
定政 邦彦
セキュリティ研究所
主任研究員
セキュリティ研究所
主任研究員
副島 賢司
セキュリティ研究所
研究部長
セキュリティ研究所
研究部長