Japan
サイト内の現在位置を表示しています。
きめ細かなマーケティングの実現に向けた顧客プロフィール推定技術
顧客一人ひとりの趣味や嗜好を踏まえたマーケティングを実現するために、個々の商品に顧客視点での特徴(商品DNA)を付与する方法が普及していますが、手間が掛かるという問題があります。顧客プロフィール推定技術は、NEC独自の関係マイニングに基づき、一部のアンケート回答結果から全顧客のプロフィール(職業、趣味、年収など)を推定する際に、手間なく高精度に予測します。この推定技術で顧客プロフィールを充実させることで、仕入や陳列、新商品企画や販促などで、従来見逃していた“個”の真のニーズを素早く発見し、具体的な施策立案を可能とします。
1. はじめに
消費者ニーズの違いをきめ細かに捉えたマーケティング(マイクロマーケティング)の実現には、AI・機械学習を用いたビッグデータの活用が効果的と言われています。
1.1 不十分な顧客の詳細プロフィール
しかしながら、データが大量にあっても、機械学習を活用するにはデータの“特徴”が不十分であるケースが多くあります。特徴とは、顧客データを例にとると、年齢や性別、趣味やライフスタイルといったプロフィール情報です。多くの企業は、顧客の年齢や性別といった基本プロフィールを収集していますが、趣味やライフスタイルといった詳細なプロフィールは収集していません。
基本プロフィールから「40代女性」というルールを得ても、なかなか効果的な打ち手につながりません。もし「旅行好きの女性」まで具体化できれば、プロモーションの手段やチャネルが明確化され、効果が期待できます。そのためには、顧客の詳細プロフィールまで知る必要があります。
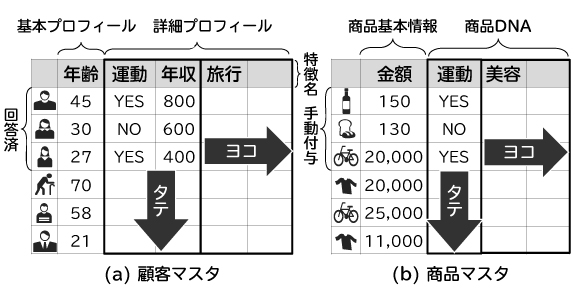
顧客プロフィールの推定は、より一般にはマスタデータ(業務要素の基本データ)の充実化であり、充実させる方向でタテ(行)方向とヨコ(列)方向に分かれます(図1)。タテ方向では、例えば、プロモーション上重要な顧客の特徴(運動、年収、旅行など)を決めて一部の顧客からアンケートをとり、その回答を用いて残りの顧客のプロフィールを推定します。回帰・判別といった教師付き学習(図2)を用いることが多いです。一方、ヨコ方向では、事前に顧客の特徴を想定せず、新しい特徴を発見します(図1 ヨコ)。これには、クラスタリングといった教師なし学習を用いることが多いです。本稿では、タテに注目します。
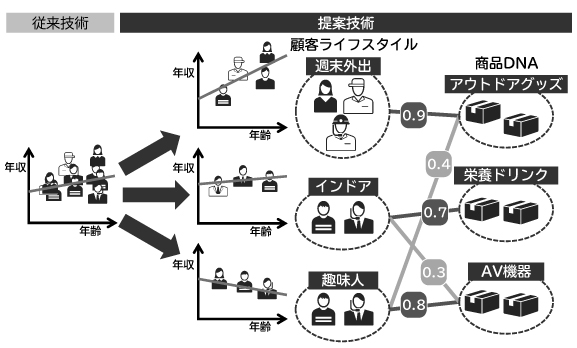
1.2 顧客視点での商品の特徴(商品DNA)
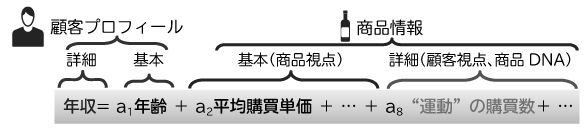
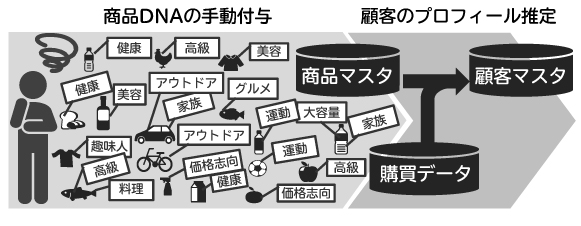
顧客プロフィールを推定するには、その顧客が買った商品が参考になるでしょう。しかし、顧客マスタ同様、商品マスタにも金額や商品分類といった基本情報しかなく、顧客の嗜好やライフスタイルを推測できる情報はありません。そのため先進的な小売企業では、人が顧客視点での商品情報(商品DNA)を各商品に付与し、これと購買データから顧客の詳細プロフィールを推定しています(図2、図3)。
2. 課題
しかしながら、従来の商品DNAを用いる方法は、第一に、作業工数が多いという課題があります。例えば、コンビニやスーパーが扱う商品数は数万以上あるため、人が商品DNAを付与するとなると数カ月も要してしまいます*。第二に、付与する商品DNAの内容が付与する作業者の主観に依ってしまいます。例えば、人工甘味料入りの低カロリー食品を、健康的な商品と見なす人もいれば、不健康な商品と見なす人もいます。
3. 顧客プロフィール推定
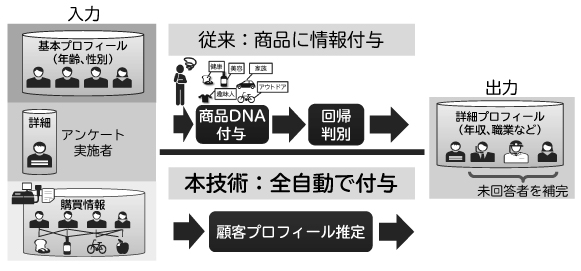
これらの課題に対して、我々は人手で商品に特徴(商品DNA)を付与することなく、自動で顧客プロフィールを推定することのできるAI技術を開発しました(図4)。本技術は、人の代わりにAIが顧客の特徴と商品DNAを購買データから抽出し、これを“仮説”として顧客の詳細プロフィールを推定します。
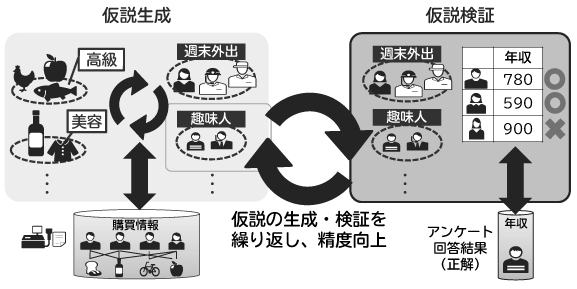
3.1 “仮説”の生成と検証
顧客の詳細プロフィール推定は、購買データからの仮説生成(顧客グループ、商品DNAの抽出)フェーズと、その仮説を一部の正解データ(アンケートで得られた一部顧客の詳細プロフィール)で検証する仮説検証フェーズからなります。これらの学習を交互に繰り返すことで、本技術はプロフィールの推定精度を向上させていきます(図5)。
3.2 購買データからの“仮説”の生成
仮説の生成フェーズでは、購買データを用いて、同じ購買パターンを持つ顧客や、似た買われ方をする商品をグルーピングし、顧客の特徴や商品DNAを抽出します。購買の有無だけでなく、購買数や購買時間、購買価格なども考慮することで、新商品への反応度や値下げへの反応度といった、より内面的な特徴も反映させることができます。
3.3 正解データを用いた“仮説”の検証
仮説の検証フェーズでは、仮説として得られた顧客グループごとに、予測すべき顧客属性に関する教師付き学習(回帰・判別)のモデルを生成します。そして、正解データ(アンケートで得られた詳細プロフィール)が得られている顧客に関して、プロフィール推定精度が高くなるように、各顧客の顧客グループへの割り当てを修正します。この修正によって、次の仮説生成フェーズでは、より精度を高めることのできるような仮説が生成されるようになります(図6)。
このように、仮説の生成と検証を何度も繰り返すことにより、高い精度で顧客の詳細プロフィールを推定します。
3.4 商品DNAの付与支援
ここまでは、アンケートによって一部の顧客に詳細プロフィールが与えられている場合に、他の顧客のプロフィールを推定するケースを考えました。この技術を応用し、一部の商品について商品DNAが手動付与されている場合に、他の商品にも付与することが可能です(図1(b)タテ)。
なお、商品の商品DNAを、一部の商品から補完する方法としてRolling Ballがあります。この方法では、ある商品の商品DNAを、その商品を買った顧客が別に買っている商品から補います。しかし、この方法では多くの人が買う商品(例えば、卵や牛乳)の影響が大きくなりすぎるため、マイナーな特徴、すなわち、よりパーソナルな特徴が無視される傾向にあります。この問題を低減させるためには、影響の大きな商品を取り除くなどの工夫が必要ですが、場当たり的な対応であり、抜本的な対策とはなりません。本技術では、購買関係が仮説としての特徴を作りつつ、正解の与えられた商品DNAからモデルを作るため、この問題は生じません。
本技術を公開データに適用したところ、専門家の分析と比較して1/20の作業時間で、かつ6%上回る精度で分析できました。
4. 小売業、マーケティングでの活用
4.1 データ可視化による業務活用
顧客の詳細プロフィールや商品DNAなどが得られると、今までとは違う観点で、データを可視化、あるいは機械学習でのルール抽出を行うことができます。ここでは、小売業でのマーケティング活用例を挙げます。
4.2 小売業での活用
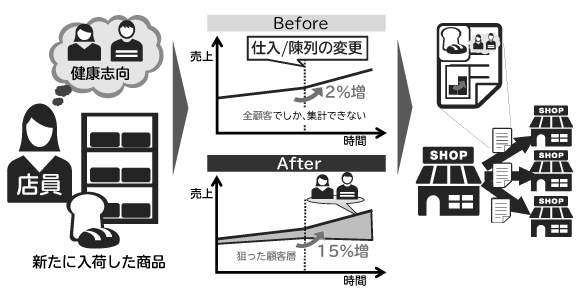
品揃えなどのインストアマーチャンダイジングでは、現場の店員の工夫を促す施策が重要です。例えば、店員が新たな商品を入荷して陳列を行う際、優秀な店員は「健康志向の多忙な社会人」といった顧客像を想定し、工夫して陳列するでしょう(図7)。しかし、仮にその施策が的確であっても、詳細プロフィールがない場合には、どの層が反応したかが分かりません。対応するプロフィールがあれば、仮説した施策が正しかったことを検証できます。更に、購買データから客観的に効果を計測できるため、現場の優れた施策をレポートとして他店舗と共有することが可能です。このような仮説・検証は、新商品開発などでも活用することができます。
4.3 プロモーション施策への活用
通信やクレジットカードなどの契約における解約の予兆分析でも、ライフスタイル情報を推定しながら予測することで予測精度を向上させることができます。また、得られるライフスタイル情報によって、施策を具体化することができます。この予測分析では、顧客の詳細プロフィールの代わりに、顧客が解約するか否かを予測対象とします。予測の精度を高めるには、やはり年齢や性別だけでは足りないため、各顧客の入出金先口座を入力します。例えば、旅行会社などの旅行好きの人が利用する複数の口座が、共通の特徴を持つとしてグループ化され、同様に顧客もグループ化されます。
その旅行好きといったグループにおいて、特定の時期の解約率が高いと分かった場合、この顧客層への解約防止施策として、旅行会社とのキャンペーン立案などを企画することができます。このように顧客の詳細プロフィールを推定することで、より具体的な施策を設計・企画できるようになります。
4.4 送客への活用
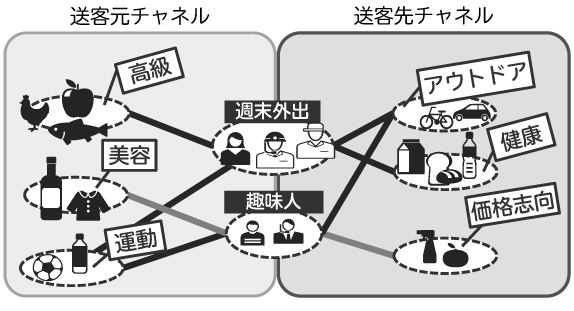
通常の購買分析では、ある販売チャネルで一度も購買したことのない顧客については、購買分析をすることができません。しかしながら、本技術では顧客IDを紐付けることのできる複数のチャネルであれば、既に利用しているチャネルでの商品の購買データを用いて、顧客をグルーピングすることができ、新たなチャネルの商品であっても適切な商品を薦めることができます。
例えば、コンビニは利用しているものの、まだ百貨店は利用していない顧客に対して百貨店の利用を促す際に、その顧客に最適な百貨店の商品をお薦めする形で、百貨店の利用を促すことができます。このように複数のチャネルでの購買を分析し、チャネル間での送客を実現する分析を多関係分析と呼びます(図8)。
5. 関係マイニング技術
5.1 業務データに特化した機械学習
本稿で顧客プロフィール推定として紹介した技術を、我々はより一般に関係マイニングと呼んでいます。“関係”とは、述語論理と集合論を合わせたデータモデルである関係データモデルを意味します。テキストや音楽に特化した機械学習があるように、業務の情報の形である関係データモデルに特化した機械学習となります。
業務の情報の形とは、例えばスタースキーマです。スタースキーマとは、複数のディメンション表と1つのファクト表とからなるスキーマで、一般の業務の見える化のためにBIツールを用いる際には、この形にデータを加工します。ディメンション表は、商品や顧客といった業務要素(マスタ)と対応し、ファクト表は購買データといった業務実績に対応します。
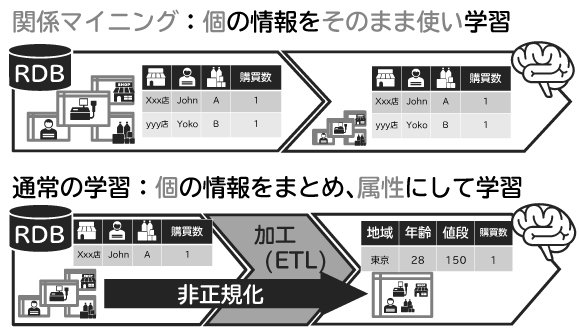
5.2 個の情報をそのまま使う機械学習
一方、多くの機械学習では、データを関係データモデルではなく1つの非正規化された表として扱います。業務が関係データモデルで表されていても、店舗IDや商品IDなどのキーで結合して実績を集計し、値域や値段といった店舗や商品の特徴として予測します。その際、属性の設計手法がさまざまあり、この加工作業のことをETL(Extract, Transform and Load)と呼びます。
関係マイニングでは、通常の機械学習と異なり、各表のID、すなわち個の情報をそのまま残します。そして、個々の商品や店舗ごとに、その背後にある隠れた情報を推定しながら予測を行います(図9)。このように業務データが持っている情報構造をそのまま学習に用いるため、送客やコンテキスト(場所、時間)依存な販促などが可能となります。
6. まとめ
趣味や嗜好、年収といった顧客の詳細プロフィールを推定するための技術を紹介しました。従来、このような顧客の特徴を推定するには、顧客視点から見た商品の特徴(商品DNA)を人手で付与する必要がありました。しかし、購買データから商品と顧客の特徴に関する仮説を生成し、アンケート回答という正解データから詳細プロフィールを推定することで、商品DNAの付与作業が不要となります。
こうして趣味や嗜好、年収といった情報を保有することで、顧客に対して適切なプロモーションや、新商品開発などを行うことができます。
執筆者プロフィール
中台 慎二
データサイエンス研究所
主任研究員
データサイエンス研究所
主任研究員
小山田 昌史
データサイエンス研究所
データサイエンス研究所