CLUSTERPRO X HA/ApplicationMonitor for RAC - 特長/機能
特長
1. インスタンスの障害監視
- インスタンスに接続し、データベースの参照/更新を行うことで、インスタンスの障害を監視することができます。
2. 特定の表の障害監視
- 障害監視の対象となる表名を指定することで、特定の表で発生するインスタンスの障害を監視することができます。
3. リスナの障害監視
- リスナ名を指定することで、特定のリスナの障害を監視することができます。
4. データベース領域不足の監視
- Oracle表領域を監視することで、データベースの領域不足を事前に検出することができます。
5. ローカルディスク容量不足の監視
- Oracleが使用するローカルディスク領域を監視することで、ローカルディスクの容量不足を事前に検出することができます。
6. Oracle Clusterwareの監視
- Oracle Clusterwareの障害を監視することができます。
7. 障害時アクション
- 障害検出時、全てのノードで定義済みアクション(システムステートダンプの採取、リスナの再起動など)を自動的に実行することができます。
8. 障害発生ノードに対する動作設定
- 障害発生ノードに対する”停止”、”停止しない”、”生存ノード数が1のとき停止しない”の3種類の設定ができ、システムとしての運用方針を選択することができます。また、複数ノード障害時の停止順序を選択できます。
9. 一時的な中断/再開
- 業務を継続させたままの状態でインスタンス、リスナ、データベースの領域不足の監視を一時的に中断/再開することができます。
機能
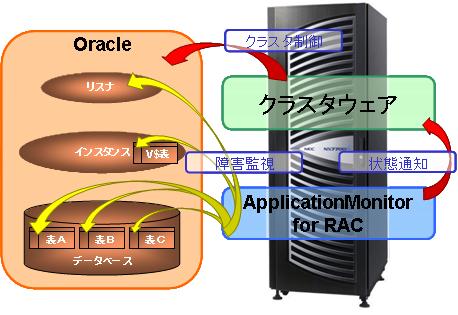
インスタンス、リスナの障害監視
![]()
- 一定時間ごとにデータベースの参照/更新などの処理を行い、Oracleバックグラウンドプロセス単位で監視することでインスタンス障害を検出します。*1
- インスタンス監視の対象となる表名を指定することにより、特定の表で発生する障害を監視します。
- 一定時間ごとにリスナの障害を監視します。
- リスナ再起動による障害復旧後の短時間で再度障害状態となるような状況を繰り返す、リスナが不安定な状態を障害として検出することが可能です。*2
- *1R5.1より提供しています。それ以前(R4.x)の監視に比べ、より詳細な障害判断ができ、RAC環境での障害ノードを特定する確度が向上しています。
- *2R5.3より提供しています。
データベース領域不足の監視
![]()
- 表領域を監視することにより、サービス停止につながる重大な問題を未然に防ぐことができます。*1
- *1ローカル管理による一時表領域の監視には使用できません。
ローカルディスク容量不足の監視
![]()
- Oracleが使用するローカルディスク領域を監視します。これにより、ディスク容量不足により発生する可能性のある Oracleハングアップの予兆を事前に検知することができます。
CRS/Oracle Clusterwareの障害監視
![]()
- Oracle RAC 10g Release2以降のCluster Ready Services(CRS)の障害を監視することができます。一定時間ごとに指定されたコマンドにより、CRSの状態を監視します。障害検出時、指定された回数のリトライを試みますが、指定回数内に状態が回復しない場合、指定されたコマンドを実行します。*1
- Oracle Clusterwareの障害を監視することができます。*2 *3
- *1Oracle RAC 10g Release1のCRSを監視することはできません。
- *2R5.2より提供しています。
- *3Oracle Clusterware/Oracle Restart環境で使用可能です。
クラスタウェア連携
![]()
- クラスタウェアと連携することにより、インスタンス、リスナ障害発生時にインスタンス、リスナの再起動やフェイルオーバができるため、システムの可用性が向上します。
- 障害種別(DOWN/STALL)によるクラスタウェア連携動作の切り分けを行うことが可能です。*1
- *1R5.3より提供しています。
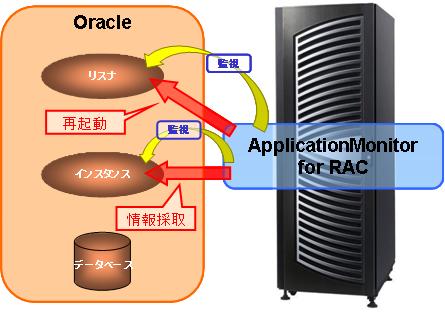
障害情報の採取
![]()
- 設定により、インスタンス、リスナ障害検出時に定義済みアクション(システムステートダンプの採取、リスナの再起動、障害解析情報の採取)を自動的に実行することができます。
- 障害検出時の定義済みアクション(障害解析情報の採取)は、シェルスクリプトにより実現されているため、容易にシステム毎のカスタマイズを行うことができます。また、インスタンスの状態を引数として渡すことにより、障害の内容により処理を切り替えることができます。
Oracle Clusterwareによるインスタンス/リスナ再起動処理の待ち合わせ
![]()
- 設定により、障害検出後の動作として、Oracle Clusterwareによるインスタンス/リスナの再起動処理の状況を待ち合わせるかどうかの選択が可能です。*1 *2
- *1R5.2より提供しています。
- *2Oracle Clusterware/Oracle Restart環境で使用可能です。
無応答障害の誤認識の防止
![]()
- ノード間通信により、クラスタ全体を1つのシステムとして監視を行うことで、あるノードで障害が発生した場合、他ノードでの再構成による無応答障害の誤認識を防止します。また、複数ノードで障害が発生した場合、優先順位設定による停止ノードの選択を行います。
監視の中断による運用性/保守性の向上
![]()
- 業務を継続させたままの状態でインスタンス、リスナの監視を一時的に中断/再開することができるため、システムの保守性/運用性が向上します。
Oracle DBA監査機能への対応
![]()
- 監視のために使用するOracle接続ユーザを指定できます。これにより、ApplicationMonitor for RACでの監視のための接続を監査対象から除外することができます。