Japan
サイト内の現在位置を表示しています。
ブログ
OSS貢献活動Kubernetes フェイルオーバーの改善: Non-Graceful Node Shutdown (Open Source Summit Japan 2023)
2023年12月14日公開
こんにちは、NEC 毛利 唯子です。
2023年12月5日(火)~6日(水)に開催された  Open Source Summit Japan 2023 において、「Kubernetes Failover Improvement: Non-Graceful Node Shutdown」と題した発表を行いました。本記事では、この発表内容を基に、Kubernetes フェイルオーバーの改善について紹介します。
Open Source Summit Japan 2023 において、「Kubernetes Failover Improvement: Non-Graceful Node Shutdown」と題した発表を行いました。本記事では、この発表内容を基に、Kubernetes フェイルオーバーの改善について紹介します。

私は 2019年から Kubernetes コミュニティに参加し、主に sig-storage と sig-testing に開発貢献しています。NECでは、Kubernetes と Kubernetes をベースにした製品 "OpenShift" をお客様に提供しています。開発貢献では、Kubernetes のバグを見つけて修正したり、お客様が必要する機能を Kubernetes コミュニティに提案して共同実装したりする、取り組みを行っています。
Kubernetesとは
Kubernetes は、コンテナ化されたアプリケーションのデプロイ、スケーリング、管理を自動化するためのオープンソース ソフトウェアです。アプリケーション コンテナは、密接に結合した他のコンテナとPodと呼ばれるグループを構成します。Pod は、Node と呼ばれる仮想マシンや物理マシン上に構成された Node 上で実行されます。複数の Node は、Kubernetes クラスタを構成します。
Kubernetes には多くの機能がありますが、最も魅力的な機能の1つは自己修復です。なんらかの障害が発生したコンテナを正常な Node 上で再起動します。
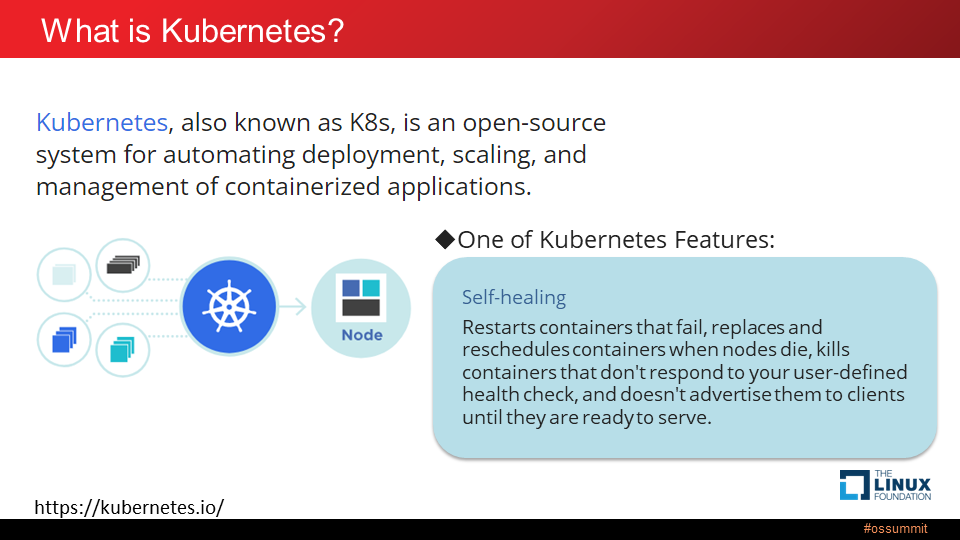
図を Kubernetes.io から引用
次に、説明に関係する Kubernetes の用語を紹介します。
・Pod (ポッド): 1つ以上のアプリケーション コンテナ (以下、コンテナ) と、それらのコンテナのいくつかの共有リソースのグループです
・StatefulSet (ステートフル セット): データ ストアなどのステートフル アプリケーションを管理するために使用されるオブジェクトです
・Node (ノード): Kubernetes のワーカー マシンであり、クラスタに応じて仮想マシンまたは物理マシンのいずれかになります
・Taint (テイント): Taint は Node の属性です。Taint により、Node への Pod のスケジューリングを制御することが可能になります
・PV (Persistent Volume, 永続ボリューム): PV は、クラスタ内のストレージの一部で、PVを使うPodとは独立したライフサイクルを持っています
Kubernetes フェイルオーバーの問題
次に、Kubernetes のフェイルオーバーの問題について説明します。
Kubernetes クラスタの Node のひとつがハードウェア故障等によりダウンした際、通常、Kubernetes コントローラはその障害 Node 上の Pod 群を他の Node 上で再作成します。この時、障害Node上の Pod は無期限に "Terminating" (終了中) ステータスとなります。しかし、StatefulSet の場合、障害 Node 上で“Terminating" ステータスのままの Pod が残り続けると、他の Node 上で新しく Pod 群が再作成されません。
また、永続化ボリュームを持つ Pod の場合、これまで (Kubernetes ver1.23 以前) の実装では 、障害 Node 上で古い Pod の 永続化ボリュームがデタッチされず、アタッチされたままになっていました。これにより、他のノード上に Pod が再作成された場合でも、PV をアタッチできなくなってしまいます。このように、StatefulSet では、Pod の自己修復がうまく働かない課題がありました。
たとえば、図のような、node1 上の StatefulSet1 の一部に、pod1 があり、それに、PV1 にマウントされているケースで説明します。

ハードウェア障害により node1 がダウンした場合、通常、2つの動作を期待します。
1つは、node1 上の pod1 が正常な node2 上に新規作成されることです。もう1つは、PV1 が node1 からデタッチされ、node2 にアタッチされることです。
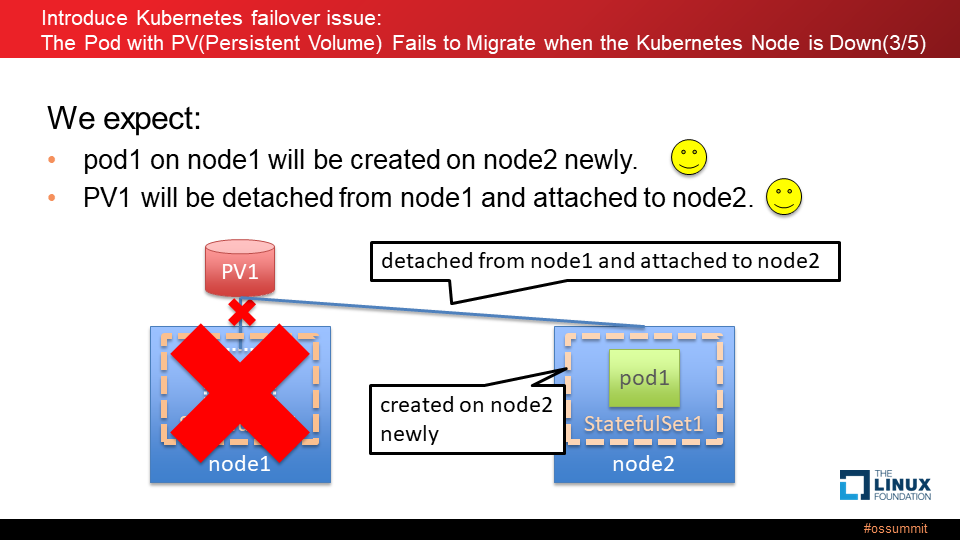
しかし、実際には、ダウンした node1 の pod1 は 正常な node2 に新規作成されず、期待する動作になりません。その理由は、node1 で障害が発生してダウンした時、node1 上で動くエージェント (kubelet) も停止し、コントローラが node1 上の pod1 を削除することができず node1 のステータスが無期限に "Terminating" (終了中) になってしまうのですが、「クラスタ内で実行されている特定の ID を持つ最大1つの Pod がいつでも存在することを保証する」という StatefulSet の特性により、"Terminating" の Pod が完全に削除されるまでは新しい Pod が作られないためです。
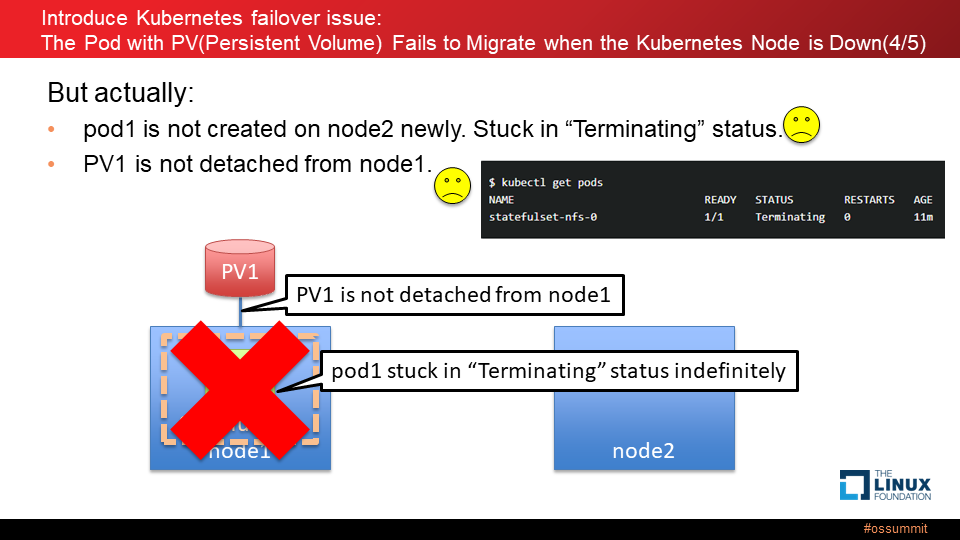
また、kubelet が停止しているため pv1 が node1 からデタッチされない事象も発生します。その結果、他の Node 上に Pod が再作成されたとしても、その Node に pv1 をアタッチできません。
Kubernetes フェイルオーバー問題の解決策: “non-graceful node shutdown"
Kubernetes フェイルオーバーの問題を解決するために、Kubernetes コミュニティでは、"non-graceful node shutdown" 機能を開発しました。
この機能を使用すると、元の Node が予期せずシャットダウンした場合、またはハードウェア障害や OS が応答しないなどの回復不能な状態になった場合に、ステートフル ワークロードを別の Node で再起動できます。この機能は Kubernetes v1.24 でアルファ版としてリリースされ、現在は v1.28 で安定版としてリリースされています。
次に、Node の "non-graceful node shutdown" 機能の使い方を紹介します。管理者または監視システムが、node1 の電源がオフになっているなど、その障害 Node がクラスタから分離されていることを確認してから、node1 に "out-of-service" (サービス停止中) の Taint を追加します。

そのテイントに設定できる値は、"NoExecute" または "NoSchedule" のどちらかです:
・node.kubernetes.io/out-of-service=nodeshutdown: "NoExecute"
・node.kubernetes.io/out-of-service=nodeshutdown:" NoSchedule"

次に、Kubernetes コントローラは、"out-of-service" の Taint が付与された Node 上の全ての Pod を強制的に削除し、またその Node にアタッチされていた全ての PV も強制的にデタッチします。これによって、StatefulSet であっても既存の Kubernetes の自己修復の仕組みが機能するようになり、壊れた Node 上の Pod が他の稼働 Node 上に新たに作成され、PV がその Node にアタッチされます。
壊れた Node が復帰したとしても、その Node に Taint が付与されている間は、その Node 上に新しい Pod はスケジュールされません。Pod をその Node にスケジュールするためには管理者ユーザが手動で Taint を削除する必要があります。
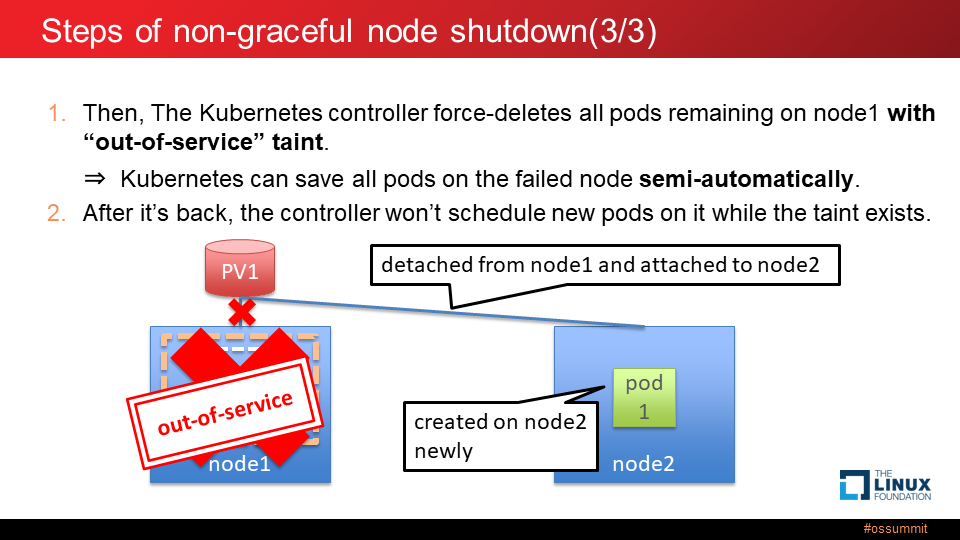
以上が、Kubernetes フェイルオーバー問題の解決策 "non-graceful node shutdown" 機能の紹介でした。
大規模環境でのフェイルオーバーの自動化
"non-graceful node shutdown" 機能によって、Kubernetes フェイルオーバーが可能になりましたが、Node 障害を検知し、その都度、手動で障害 Node に Taint を付与する必要があります。Node を何百台、何千台と運用しているような、大規模な本番環境では非常に手間がかかります。
そこで、Node 障害を検知し、障害 Node に Taint を付与する処理を自動化する「Node Health Check operator」と「Self Node Remediation operator」を紹介します。どちらも medik8s という OSS プロジェクトで開発されている Kubernetes オペレータ (以下、オペレータ) です。

Node Health Check operator は Node 障害を検知するオペレータ、Self Node Remediation operator は障害 Node を修復するオペレータとなります。あらかじめ Node 障害(例えば「1分以上 Node との通信ができない」など)を定義しておくと、Node に障害が起こった場合、Self Node Remediation operatorが障害 Node に Taint を付与します。これがトリガーとなり、"non-graceful node shutdown" 機能によって障害 Node 上の Pod が他の稼働 Node 上に新たに作成されます。
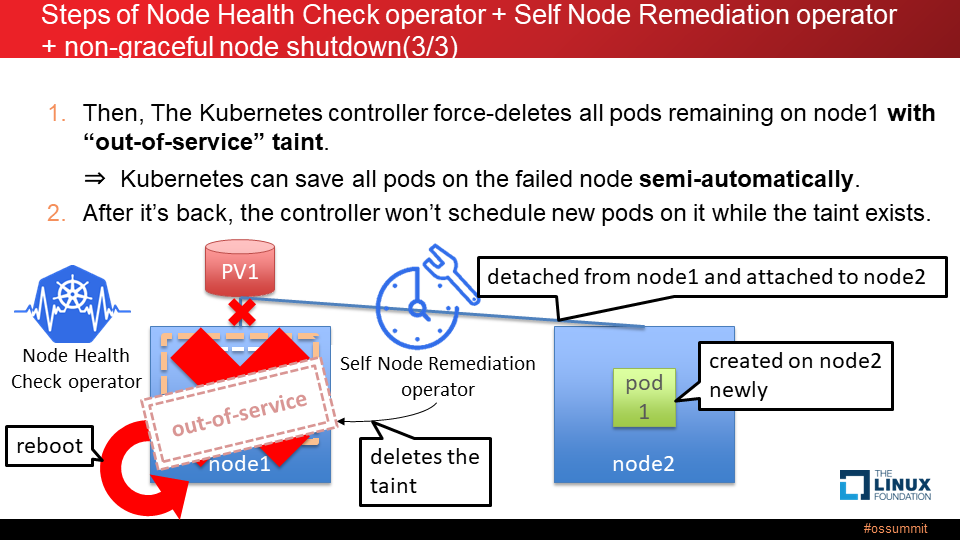
このように、「Node Health Check operator」と「Self Node Remediation operator」を使うことで、障害 Node に対して自動的に Taint が付与されるため、Taint を手動で付与する必要がなくなり、数百台、数千台の Node が稼働する大規模環境においても、フェイルオーバーの自動化が可能になります。
最後に
今回、Kubernetes フェイルオーバーの改善という、多くの Kubernetes 利用者が恩恵を得られる機能を、Kubernetes コミュニティメンバと共同開発して、リリースできました。今後も、お客様の課題解決と Kubernetes コミュニティの発展のために、開発貢献の活動を継続していきます。
執筆者
毛利 唯子 (Yuiko Mori)
日本電気 (NEC Corporation)
Kubernetes 活用の中で、特に案件適用する際に顕在化した要追加機能や品質の向上を主なターゲットとしています。特定の領域に絞らない活動ですが、現在はストレージの領域に開発参加しています。過去には、OpenStack コミュニティにて ironic-inspector プロジェクトのコア開発者として活動していました。(2023年12月時点の情報)
