Japan
サイト内の現在位置を表示しています。
クエリを考慮した新規手法により関連する企業データを減らしLLM APIの使用コストを最適化
Vol.75 No.2 2024年3月 ビジネスの常識を変える生成AI特集 ~社会実装に向けた取り組みと、それを支える生成AI技術~ PDFで閲覧する
PDFで閲覧するユーザークエリに対し、より正確な回答を大規模言語モデル (LLM)に生成させるために企業所有のデータをコンテキストとして使用すると、LLM APIの使用コストは急激に上昇します。本稿では、こうしたコストを削減するために開発したLeanContextを紹介します。このシステムは、関連する企業データのコンテキストから、クエリを考慮し、コンパクトでAIモデルと親和性の高い要約を生成します。これはクエリを考慮せずに、人間に優しい要約を生成する従来のツールとは異なります。最初に、検索拡張生成 (RAG)を使用して、重要でクエリに関連した企業データを含む、クエリを考慮した企業データのコンテキストを生成します。次に、強化学習を用いてコンテキストを更に縮小します。同時に、ユーザークエリと縮小コンテキストからなるプロンプトにより、元の企業データコンテキストを使用したプロンプトと同程度に正確な応答をLLMから引き出せるようにします。この縮小コンテキストは、クエリに依存するだけでなく、サイズの変更が可能です。実験の結果から、LeanContextは、(a)LLM応答の精度を維持しながらLLM API使用コストを(RAGとの比較で)37%~68%削減でき、(b)この最先端の要約ツールでRAGコンテキストを縮小すると応答の精度を26%~38%向上できることが明らかになりました。
1. はじめに
大規模言語モデル(Large Language Model、以下、LLM)は、人間のような言語を生成するために広範囲のテキストデータに基づいて訓練された先進的なAIモデルであり、自然言語処理によるタスクを大幅に強化します。著明な例であるOpenAIのGPT-41)は、ユーザーに優しいアプリケーションプログラミングインタフェース(API)を特長としており、これがコンテキスト対応チャットボットやリアルタイム言語翻訳、効率的なテキスト要約といった分野での幅広い使用を促しています。これにより、さまざまな業界においてユーザーエクスペリエンスの向上が図られています。
GPT-4のようなLLMは、企業が所有するデータに関する情報についてのクエリに答えることができません。というのも、LLMがこうしたデータで訓練されていないからです。しかし、LLMに企業の所有データを認識させると、業界に特有の用語やプロセス、コンテキストを使用した回答を生成することができます。これにより、企業はより正確で関連性の高い回答を得られるようになります。
LLMに企業データを認識させるためのよく知られた2つの方法は、ファインチューニングと検索拡張生成 (RAG)2)です。ファインチューニングは、LLMのモデルの重みを変更して、モデルをドメイン固有の微妙な違いに適応させます。それとは対照的に、RAGは事前学習済みのモデル(修正はまったく加えない)と、企業データから関連情報(コンテキスト)を選び出すリトリーバーの組み合わせを利用して、この外部知識をLLMへのプロンプトに組み込みます。本研究では、LLMに企業データを認識させるためにRAGアプローチを使用しています。
LLM APIの使用コストは、特にLLMへのプロンプトに企業情報を組み込む場合、非常に迅速に増加する可能性があります。コストは、プロンプトとLLMの応答に含まれるトークン数に依存します。GPT-3 LLMではトークンは約4文字3)ですが、LLMや言語によってこの数字は異なります。
LLM API使用の高コストを示す具体例として、週に2回、15,000人の訪問者がそれぞれ3つのリクエストを送るサービスを考えてみます。(典型的な)プロンプト1つ当たりでは、約1,800のプロンプトトークンと80の出力トークンがあるとします4)。この場合、GPT-4 APIの使用コストは月額21,200ドルになります(価格は、プロンプトに対して0.03ドル/1Kトークン、生成された出力に対して0.06ドル/1Kトークンとします)。
本稿では、企業データの使用がより有用な回答を生成できるシナリオにおいて、LLM APIの使用コストの削減に注目します。そして、優れたコスト効率でクエリアウェアに企業データのコンテキスト検索を可能にする新しいシステム「LeanContext」を提案します。これにより検索されるコンテキストはコンパクトになり、回答のためのクエリとの関連性が高まります。実験の結果は、 (a)LeanContextなら、応答の高い精度を維持しながらLLM API使用コストを削減(RAGコンテキストと比較して37%~68%)できること、及び(b)前述したよく知られる要約ツールでRAGコンテキストを縮小するケースと比べて、LeanContextは応答の精度を26%~38%向上させることを示しています。
2. 検索拡張生成
図1は、従来のRAG方式を示しています。これは、企業データの取り込み、及びクエリ/応答という、並行して動作可能な2つの異なるパートで構成されます。

企業データの取り込み:企業のテキスト文書はテキストスプリッタで小さなチャンクに分割されます(チャンクとは、企業文書内の連続した文の集まり)。埋め込みジェネレータは、各チャンクをあらかじめ決められたn次元のベクトルに埋め込みます。これらのベクトル及び対応するチャンクは、ベクトルデータベースに保存されます。チャンクをベクトルとして保存することで、特定のユーザークエリに関連する企業データを容易に見つけることが可能となります。
クエリ/応答:ユーザークエリもn次元のベクトルに埋め込まれます。図1に示したように、セマンティック検索の手法は、ベクトルデータベース内でユーザークエリベクトルに最も似ているN個のベクトルを特定します。ここで、Nは事前に決定したパラメータです。これらN個のベクトルに対応するチャンクは関連する「RAGコンテキスト」となります。このコンテキストはユーザーのクエリと組み合わされてプロンプトが構築され、LLMからの応答がユーザーに提供されます。プロンプトのサイズはLLM APIの最大トークンの制限を超えることができません(この制限はLLMによって変わる可能性があります)。
3. LeanContext
LeanContextを設計するうえで鍵となる2つの重要な見解があります。1つ目は、実際のアプリケーションでの実験から、LLMが正確な応答を生成する際に、従来のRAGで検索されたコンテキストのN個のチャンクにある情報すべてを必要とするわけではないということが分かっています。2つ目は、RAGコンテキスト内のどの特定の情報が省略可能かは、「ユーザークエリ」に依存しているということです。LeanContextは、これらの所見を活用して、RAGコンテキストからよりコンパクトな「縮小コンテキスト」を構築します。この縮小コンテキストはLLM API使用コストの削減とダイレクトにつながっています。また、縮小コンテキストは、より大きな(N個のチャンクの)RAGコンテキストによるプロンプトを使った場合と同程度の精度を持つLLM応答を実現します。
図2にLeanContextのシステム概要を示します。まず、従来のRAG手法を使用して、企業データコンテキストのN個のチャンクを検索します。次に、このRAGコンテキスト内のセンテンスをユーザークエリとの関連性に基づきランク付けをします。第3章1節の新しい強化学習アルゴリズムでは、縮小コンテキストの構築のために考慮する必要があるランク付けされたRAGコンテキストのなかから、上位k個のセンテンスを特定します。本研究の強化学習アルゴリズムは、ユーザークエリとRAGコンテキストに基づいてkの値を決定します。その後、重要な上位k個のセンテンスはそのまま残されますが、ランク付けされたRAGコンテキスト内にあって重要度が低いその他の文は、フレーズ削除あるいは要約によって更に圧縮されます。そして、第3章2節で説明するように、上位k個のセンテンスと圧縮された重要度の低いセンテンスを組み合わせて縮小コンテキストを作成します。
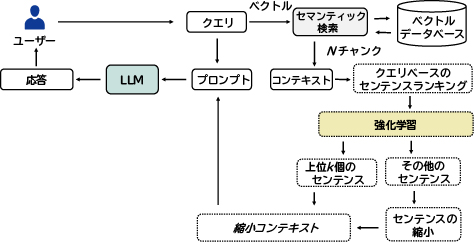
3.1 kを算出するための強化学習
ユーザークエリとこれに対応するRAGコンテキストを与えると、NECの「新規軽量Q学習ベースの強化学習(RL)」アルゴリズムは、この組み合わせに適切なkを計算します。次に、このRLアルゴリズムの状態、行動、報酬のコンポーネントについて簡単に説明します。
状態:N個のチャンクからなるRAGコンテキストの埋め込みベクトルを作成します。次に、RAGコンテキスト埋め込みベクトル(vc)からクエリ埋め込みベクトル(vq)を引いて差分ベクトルを得ます。多数のクエリとコンテキストのペアに対して差分ベクトルを構成し、これらのベクトルをクラスタリングしてセントロイドを算出します(K-Meansクラスタリングアルゴリズムを使用)。これらのセントロイドが本研究で用いる状態ベクトル![]() です。
です。
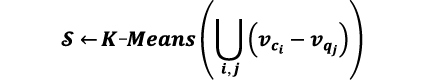
変数iとjは、それぞれ異なるRAGコンテキストとユーザークエリにインデックス付けするため使用します。
行動:行動はランク付けされたRAGコンテキストに含まれる総センテンス数の特定の割合に対応しています。行動は0~0.4の間で任意の値をとることができ、0.05刻みになっています。例えば、行動が最大値の0.4であったとするなら、ランク付けされたRAGコンテキストに含まれる総センテンス数の40%がクエリに最も似ている上位k個のセンテンスであるとみなせるでしょう。上位k個のkは、現在の行動値及びランク付けされたRAGコンテキストに含まれる総テキスト数の積として導き出せます。
報酬:行動の値が与えられると、上位k個のセンテンスとそのトークン数を割り出すことができます。トークン比(![]() )は、縮小コンテキストに含まれる上位k個のセンテンスのトークン数と、ランク付けされたRAGコンテキストに含まれるすべてのセンテンスのトークン数の比として定義されます。トークン比が低いほど、上位kコンテキストの長さは短くなります。しかし、上位k個の縮小コンテキストに対するLLMの応答精度は、完全なRAGコンテキストに対するLLMの応答精度と同等でなければなりません。異なるLLMでの応答精度の比較には、ROUGE-15)スコアを使用します(ROUGE-1スコアを計算するために使用する参照応答は、第3章3節で説明します)。完全なRAGコンテキストでのROUGEスコアが(r*)で、上位k個コンテキストのROUGEスコアがrである場合、
)は、縮小コンテキストに含まれる上位k個のセンテンスのトークン数と、ランク付けされたRAGコンテキストに含まれるすべてのセンテンスのトークン数の比として定義されます。トークン比が低いほど、上位kコンテキストの長さは短くなります。しかし、上位k個の縮小コンテキストに対するLLMの応答精度は、完全なRAGコンテキストに対するLLMの応答精度と同等でなければなりません。異なるLLMでの応答精度の比較には、ROUGE-15)スコアを使用します(ROUGE-1スコアを計算するために使用する参照応答は、第3章3節で説明します)。完全なRAGコンテキストでのROUGEスコアが(r*)で、上位k個コンテキストのROUGEスコアがrである場合、![]() であるならQテーブル内の現在の(状態、行動)ペアの値には報酬を与えられます。そうでない場合にはペナルティーが課されます。報酬関数Rは次のように定義します。
であるならQテーブル内の現在の(状態、行動)ペアの値には報酬を与えられます。そうでない場合にはペナルティーが課されます。報酬関数Rは次のように定義します。
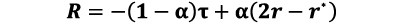
ここで、αはトークン比と応答精度の、報酬値に関する相対的な寄与を制御します。
3.2 縮小コンテキスト
開発したRLアルゴリズムは、クエリに固有のkの値を割り出します。これにより上位k個のコンテキストが決まります。このコンテキストにはクエリに関連する重要な上位k個のセンテンスに加えて、上位k個のセンテンスの近傍にあるその他の重要度の低いセンテンスが含まれます。図3に今回の縮小コンテキストの構成方法を示します。クエリに対するコンテキストの関連性を維持するのに重要であるため、最も関連性の高い上位k個のセンテンスはそのまま残します。しかし、重要度の低いセンテンスは、オープンソースのテキスト縮小手法6)-10)を使用して更に個別に圧縮します。また、最後の上位k個を超えるセンテンスは縮小コンテキストに含めません。
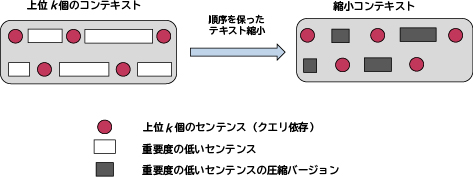
ランク付けされたRAGコンテキストにおいて、上位k個のセンテンスと重要でないセンテンスの両方で元の順序は保持されます。センテンスの順序を保持することによりコンテキストの時間的な一貫性が確保されます。縮小コンテキストの構成にこうした全体的なアプローチをとることにより、LLM API使用のコストを大幅に削減しながら、LLM応答の精度の確保を最終的に実現します。
3.3 結果
企業データ:本研究ではarXivとBBCニュースのデータリポジトリを使用しました。これらのデータリポジトリには2023年3月に公開された文書6)が含まれており、GPT-3.5-Turboモデルの事前訓練には使用されていません。まず、arXivからはランダムに25の文書を選びました。これらの文書には63~962のセンテンス、1文書当たり平均で352のセンテンスがあります。同様に、BBCニュースからは100の文書を選びました。これらの文書には4~139のセンテンス、1文書当たり平均で30のセンテンスがあります。
クエリと参照応答:本研究ではQAGenerationChain11)を用いて、各データセットでそれぞれ100個のクエリを生成しました。これらは、RAGやLeanContextのROUGE-1精度スコアを算出するための「基準」となるLLM応答を得るために、文書全体をコンテキストとして使用します。
企業データコンテキスト:arXivデータセットに対してはN=4、BBCニュースに対してはN=8を設定しました。arXivデータセットの場合、RAGコンテキストの総センテンス数は9~25の間で変動し、コンテキスト当たりの平均センテンス数は15でした。同様に、BBCニュースデータの場合、コンテキスト内の総センテンス数は18~34の間で変動し、コンテキスト当たりの平均センテンス数は26でした(図4)。
縮小コンテキスト:arXivデータとBBCニュースデータにおける上位k個のセンテンスの分布を、それぞれ図5と図6に示します。
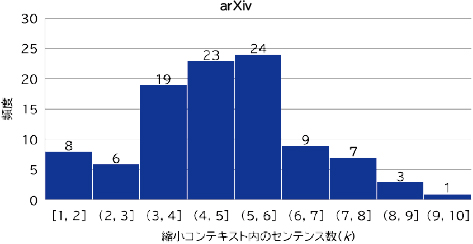
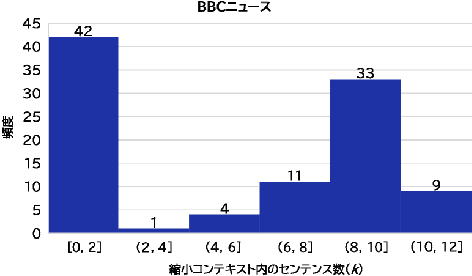
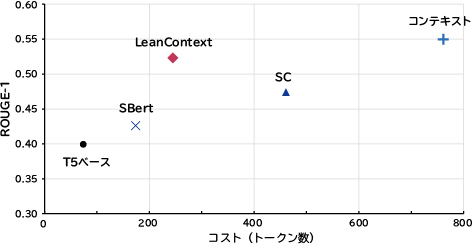
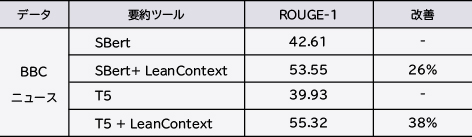
表1では、RAGコンテキストと縮小コンテキストとの効果を比較しています。LLMの応答精度(ROUGE-1スコア)はほぼ同じですが、縮小コンテキストはLLM APIの使用コストを37%~68%削減します。T510)、BERT9)、SC6)などの有名なテキスト縮小モデルと比較すると、LeanContextはコストを削減し、精度が向上します(図4)。また、他の有名な要約ツールを使用してRAGコンテキストを縮小するケースでも、応答精度(ROUGE-1スコア)が向上します(表2)。
表1 従来のRAGと縮小コンテキストとの比較(精度はROUGE-1スコア)
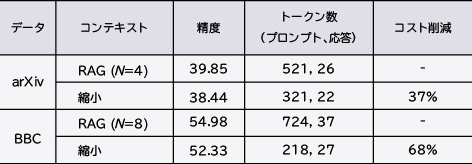
表2 他の有名な要約ツールでRAGコンテキストを縮小する際の応答精度の向上
4. むすび
LeanContextは、高い精度を維持しながら、LLM APIの使用に関係したコストを軽減する、コスト効率に優れたクエリ考慮型コンテキスト縮小システムです。コンテキストの縮小はLLMの推論時間の改善にもつながります。LeanContextは、他の有名な要約ツールと組み合わせてRAGコンテキストを縮小するケースでも、効果的に使用できます。
参考文献
- 1)
- 2)
- 3)
- 4)
- 5)
- 6)
- 7)
- 8)
- 9)
- 10)
- 11)
 OpenAI: GPT-4
OpenAI: GPT-4執筆者プロフィール
AREFEEN Md Adnan
NEC Laboratories America
Research Assistant
University of Missouri-Kansas City
NEC Laboratories America
Research Assistant
University of Missouri-Kansas City
DEBNATH Biplob
NEC Laboratories America
Senior Researcher
NEC Laboratories America
Senior Researcher
CHAKRADHAR Srimat
NEC Laboratories America
Department Head
NEC Laboratories America
Department Head

