Japan
サイト内の現在位置
AI/ML向け開発プラットフォームFrovedisのご紹介
no.0092021.3.31 世の中には主に科学技術計算や気象シミュレーションを高速に実行することに注力するコンピューターが存在します。NECではSXシリーズとして30年以上に渡り、科学技術計算用途向けにスーパーコンピュータの提供を続けてきました。
その最新モデルであるSX-Aurora TSUBASAは、数百台のサーバで構成される大規模なシステムとして様々な科学技術計算を実行して頂いている事例があります。
ところで、HPCwireという「スーパーコンピュータ(あるいはハイパフォーマンスコンピュータ)に関する情報発信」を行っているサイトをご存じでしょうか。このサイトのHeadlinesでは、スーパーコンピュータを使った科学技術シミュレーション関連記事の他に、AI/MLに関連する記事が散見されます。最近ではこのようにスーパーコンピュータはシミュレーションを実行させるだけでなくAI/ML、あるいはAI/MLとシミュレーションを融合するというような使われ方も増えてきていることが分かります。
例えば、HPCwireの記事Researchers Train Fluid Dynamics Neural Networks on Supercomputersでは、流体計算を教師あり学習で補完するというシミュレーションとAI/MLのハイブリッドな事例が紹介されており、大規模なシミュレーションをAI/MLのサポートを利用して計算量を削減しながらも精度を向上させることに成功したそうです。
こうした潮流をうけて、スーパーコンピュータを従来の科学技術計算やシミュレーションのためだけでなくAI/ML領域でもお使いいただけるようにするために、NECはAI/ML向け開発プラットフォーム整備に取り組んでいます。
シミュレーションをはじめとする科学技術計算ではレディーメードのシミュレーションソフトウェアを使用する場合を除き、多くはFortranやC/C++で計算処理をプログラムコード化したものをコンパイルにより実行ファイルを作成したうえで、処理実行することが一般的な使われ方でしょう。
この際に使用されるベクトルプロセッサ用コンパイラや並列処理のためのライブラリであるMPI、また数値計算ライブラリやデバッガなどがSX-Aurora TSUBASAの科学技術計算処理向け開発プラットフォームの構成要素になります。
一方、AI/MLを使ったアプリケーションでは異なる開発スタイルを取ることが多いようです。C/C++でコードを書くことにより処理速度向上を追及することや省メモリプログラミングを狙うケースは少なからずあるとは思いますが、多くはscikit-learnやTensorFlowといったフレームワークを使い、例えばPythonからAPIを呼び出して処理することが一般的になっています。こうした背景を踏まえてSX-Aurora TSUBASA向けに機械学習やディープラーニング処理の実行をベクトルプロセッサに任せることで高速化するためのAI/ML開発フレームワークが用意されています。
では、AI/MLの開発フレームワークの具体的な中身について簡単に見てみましょう。
AI/MLにおいて機械学習を行う前処理として、データの準備は避けては通れません。この前処理ではデータファイルをディスクから読み込む、あるいはデータベースに蓄積されたデータであればSQLクエリ処理を通して必要なデータを抽出します。
また多くの場合にデータに対して欠損値の扱いや正規化といった何らかの加工処理が施されます。この加工処理ではNumPyやPandasを使いベクトルやマトリックスデータに必要な処理を加えていきます。機械学習の作業時間全体に占める割合が大きいのは実はこの前処理作業であると言われています。
第5回のコラムで紹介しましたが、NumPyと互換性を持たせたNLCPyを使うことで、こうした計算処理をベクトルプロセッサで高速に実行することができます。
データの前処理が完了すると次に機械学習やディープラーニングのためのフレームワークにデータを送って学習処理させます。例えばscikit-learnでは分類、クラスタリング、回帰分析など数多くのアルゴリズムが用意されており、分析用途に応じて選択したアルゴリズムにデータを読み込ませて機械学習を行うことができるようになっています。
SX-Aurora TSUBASAのための機械学習フレームワークとして、FrovedisやSX-Aurora TSUBASAで実行可能なTensorFlowがオープンソースとしてGitHubに公開されています。SX-Aurora TSUBASAのAI/ML開発フレームワークの中から、今回はこのFrovedisについてご紹介したいと思います。
Frovedis? Spark? Hadoop?
Frovedisとは? 一言で表すと、「NEC middleware compatible to Spark」、少し踏み込んだ説明ではSX-Aurora TSUBASAのベクトルプロセッサを意識せず、Apache Spark(以下、Spark)がもつデータ分析で利用される機械学習やデータフレームライブラリが使用できるミドルウェアの名称です。
さて、ここで登場するSparkとは何でしょうか。Sparkは大規模データをインメモリで分散処理するためのフレームワークです。一台のサーバが持つメモリサイズを大きく超えるデータを高速に扱えるようにするため、Sparkは複数のサーバのメモリにデータを分散配置します。
この時、並列分散処理部分におけるタスク分割やスケジューリングといった面倒な作業をSparkが管理実行するため、並列分散処理環境を意識する必要性を低減してくれます。大規模なデータを並列分散処理するためのミドルウェアとして他にHadoopがありますが、こちらはHDFS呼ばれるファイルシステムにアクセスし処理するものです。すなわち、Sparkでは主にメモリ上のデータに対して並列分散処理を行いますが、HadoopではHDFSが管理する多数のディスク上のデータに対して行います。Sparkは単独で利用できますし、複数のサーバが持つメモリサイズを超えるような超巨大なデータ処理をHadoopと連携して行うことも可能です。
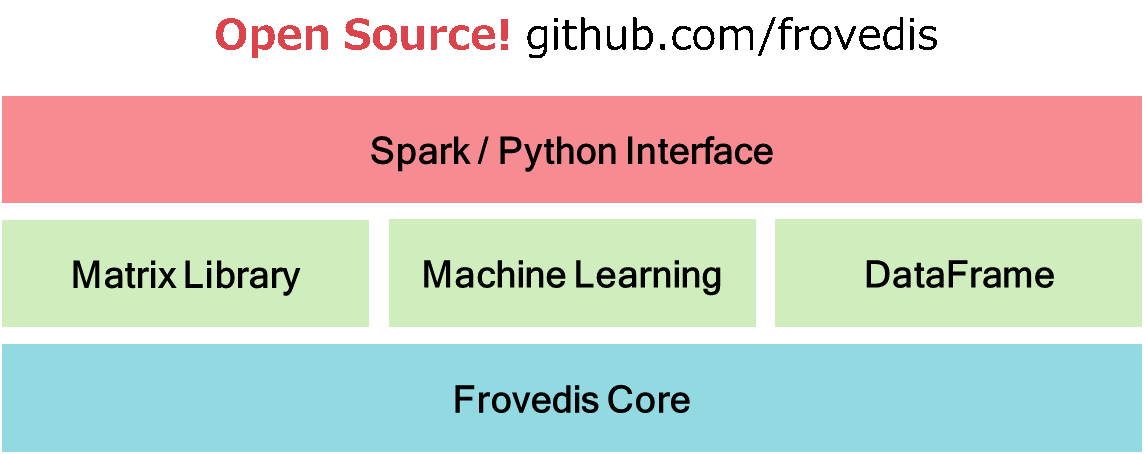
Sparkの詳細についてはオンライン上にある様々なガイドを見ていただくとして、Sparkフレームワークがもつコンポーネントの概略だけ触れておきます。クラスタのメモリに分散配置されたデータを使った機械学習を行うためのMLlibの他、ストリーミング データの処理を行うための Spark Streaming、グラフ操作とアルゴリズムのための GraphX、分散データに対するSQL クエリのための Spark SQLが用意されています。
FrovedisではこれらSparkコンポーネントの中でMLlibの一部について互換性を保った形でサポートしています。また、データを簡便に扱うためのデータフレームも用意しています。
Frovedisに用意された機械学習のためのAPIを利用できるのはSparkからだけではありません。他にもPython、C++を使ってFrovedisのAPIを利用することができます。
複数のサーバ上に分散させる必要がない規模のデータ、例えば数G Bytes程度のサイズであればSparkを使わずPythonからAPIを呼び出してデータ処理や機械学習する方が現実的です。単独のタワー型サーバやラックマウントモデルのメモリサイズで扱えるデータサイズでありながら、CPUでは処理時間がかかりすぎるという悩みを抱えておられる方は少なくないと思います。
PythonからFrovedisのAPIを通してSX-Aurora TSUBASAのベクトルプロセッサに処理をオフロードし、処理時間を短縮することでこうした悩みが解決されます。その結果、最適な機械学習モデルを決めるための試行錯誤を容易に、あるいは高い頻度で機械学習を実施して学習の精度を高めることが可能になります。
FrovedisがPython向けに提供する機械学習APIは大きくscikit-learnとFrovedisオリジナルAPI群、そしてgraphアルゴリズムの3つに分けられます。
1. scikit-learn API
2. FrovedisオリジナルAPI
3. Frovedis.graph アルゴリズム
順を追ってこれらを見てみましょう。
scikit-learnはPythonを使用して機械学習を行うためのライブラリ群です。scikit-learnに用意される多くの機械学習ライブラリを使用することで、NumPyやSciPyで直接数式をコーディングすることに比べて、はるかに手軽に統計ベースの機械学習を行うことができるようになります。
FrovedisのAPIはこのscikit-learnの機械学習APIの一部をベクトルプロセッサにオフロードする機能を提供しています。対象となるAPIについてはFrovedisのチュートリアル内の4. Machine learning algorithmsを参照ください。各機械学習アルゴリズムの末尾に(sklearn)とつけられているものがFrovedisで利用可能なAPIになります。使用方法はリンク先を、とありますが、リンク先は本家scikit-learnマニュアル内の各APIについてのガイドです。
このことから分かるように、Frovedisが提供するこれらAPIはscikit-learnのAPIを使用する際のパラメータや属性と互換性があります。そのため、CPUベースで書かれたPythonコードのscikit-learnの呼び出し部分を書き換えることなく、ベクトルプロセッサに処理をオフロードするプログラムへの変更はとても容易となります。
次にFrovedisオリジナルなAPIグループですが、以下の4つで構成されます。
Frovedis.mllib.fm.FactorizationMachineClassifier
Frovedis.mllib.recommendation.ALS
Frovedis.mllib.fpm.FPGrowth
Frovedis.mllib.feature.Word2Vec
そして3番目のグラフアルゴリズムはNetworkXのAPIインターフェースと類似したものとなっています。NetworkXの詳細についてはwikipediaまたはhttps://networkx.org/documentation/stable/index.htmlをご覧いただくとして、ここでは簡単な説明にとどめますがNetworkXが持つグラフアルゴリズムを使うことでソーシャルネットワーク内のコミュニティーを抽出するといった分析が行えるようになります。現在、ベクトルプロセッサで実行できるグラフアルゴリズムは次の8つになります。
Frovedis.graph.pagerank
Frovedis.graph.connected_components
Frovedis.graph.single_source_shortest_path
Frovedis.graph.bfs_edges
Frovedis.graph.bfs_tree
Frovedis.graph.bfs_predecessors
Frovedis.graph.bfs_successors
Frovedis.graph.descendants_at_distance
以上あげた機械学習APIの他に、FrovedisはPandasライクなDataFrame操作をSX-Aurora TSUBASAのベクトルプロセッサ上で行うためのインターフェースやScaLAPACK, PBLASをPythonから利用するためのAPIをそろえています。
今回はSX-Aurora TSUBASAのAI/MLフレームワークの一つであるFrovedisの概要についてのみのご紹介になりました。次回以降、FrovedisのDataFrameやNLCPyを使ったデータ前処理、機械学習APIを使った学習について、次回以降で具体的な使い方の例を紹介していきます。
関連リンク
 AL/ML開発向けオープンソースプラットフォーム「Frovedis」
AL/ML開発向けオープンソースプラットフォーム「Frovedis」
SX-Aurora TSUBASAテクニカルセミナー特設サイト
本コラム内容を踏まえたテクニカルセミナー動画公開中。第1回講演3参照。