Japan
サイト内の現在位置
オンライン最適化
NECのコア技術 : オンライン最適化
オンライン最適化は、不確実性の高い環境下でも最適な意思決定を実現する技術です。
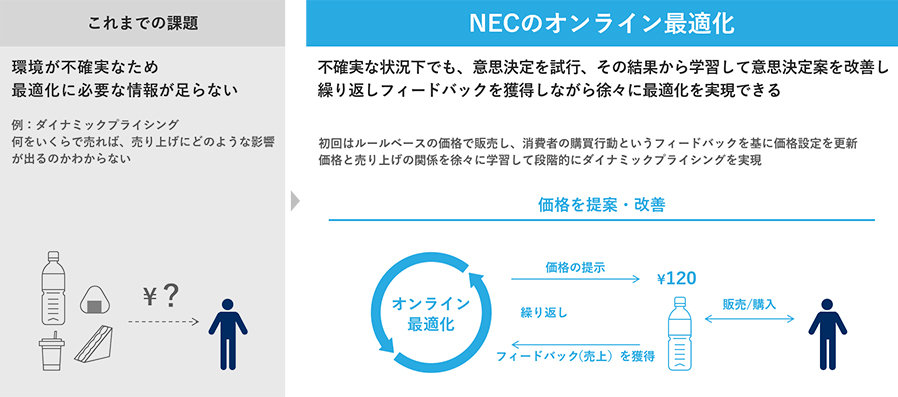
近年、ダイナミックプライシングやレコメンドのパーソナライズなど、状況に応じて施策を自動的に変化させて、最適な意思決定を実現する取り組みが注目されています。従来は、状況に応じて柔軟に施策を変更する場合、データから見出した傾向に基づいて最適化する方法がとられてきました。しかしこの方法では、データ不足により十分な精度の予測が得られない場合や、事業環境が頻繁に変化する場合には、かえって逆効果になってしまう恐れもあります。
NECのオンライン最適化は、これらの不確実性を考慮し、多様なデータを獲得しながら最適な意思決定を実現します。オンライン最適化を活用することで、これまで意思決定の自動化が難しかった領域でも効果の高い意思決定を実現します。
図:オンライン最適化の課題適用例
オンライン最適化の特長
従来の予測分析では、事前に大量のデータを用意する必要がありました。
オンライン最適化なら、予測の不確実性を考慮して最適化するため、データが貯まるのを待つ必要はありません。また、この特性を活かしたスモールスタートが可能です。
スモールスタートが可能
季節やトレンドなどの変化により最適な意思決定が移り変わる業務では、環境の変化を絶えず観測して意思決定に反映する必要があります。
オンライン最適化は、探索的な意思決定も交えることで常に環境を観察し、最新のフィードバックに基づいて環境変化に追従します。
環境変化への自動適応
NECのオンライン最適化は、従来手法と組み合わせることでシームレスな意思決定高度化が可能です。
例えば、すでに予測分析を用いたレコメンドシステムを導入している場合、オンライン最適化を併用することで、きめ細やかなパーソナライズや、ユーザ嗜好の変化への適応が可能になります。
シームレスな移行
期待できる効果
オンライン最適化は、データの探索と活用を繰り返すことで、スマートな意思決定自動化を実現します。
きめ細やかな意思決定
個人や店舗ごとに意思決定モデルを構築し、それぞれにとって最適な意思決定を実現激しい環境変化にも対応
環境変化への自動適応により、質の高い意思決定自動化を実現固定化した戦略からの脱却
ルールベースなどの固定的な戦略で生じてしまう機会損失を、臨機応変な戦略により最小化ユースケース
<Case1> ダイナミックプライシング
価格と売れ行きの関係を学習しながら最適化
従来のダイナミックプライシングでは、さまざまな価格で販売したデータがないとプライシングのモデルが作成できず、このことが導入のハードルになっていました。
オンライン最適化なら、データが不十分な場合でもダイナミックプライシングの導入が可能です。具体的には、必要最低限の探索的価格を設定して、その売れ行きから価格との関係を学習していきます。これを繰り返し、最適な価格設定を自動的に見出します。これにより、機会損失の削減や在庫品の調整が可能になります。

<Case2> レコメンド最適化
ユーザの嗜好が不明な状態からでもパーソナライズを実現
従来のレコメンドは共通のルールやモデルに基づいているため、本来であれば重要な嗜好の個人差がノイズとして扱われてしまい、きめ細やかなレコメンドができませんでした。 また、嗜好の変化に対応するにはルールの再設定やモデルの再学習が必要でした。
オンライン最適化なら、ユーザごとに個別のレコメンドモデルを作成することで、これらの課題を解決できます。レコメンド内容へのユーザの反応に基づいてモデルを自動更新していくため、少ないレコメンド回数でもきめ細やかなパーソナライズを実現し、嗜好の変化へも自動適応します。

<Case3> 品揃え最適化
店舗ごとの特性に合わせて最適化
全店舗共通の品揃えでは各店舗の地域特性などを考慮することができないため、店舗別の品揃えモデルを作ることが理想です。しかし、従来手法では、店舗個別のモデル作成およびその保守や運用には非常に労力がかかり、非現実的でした。また、消費者のニーズ変化に適応することも容易ではありません。
オンライン最適化なら、環境変化に自動適応するモデルを店舗ごとに作成することで、この課題を解決できます。売れ行きから消費者の嗜好を学習し、より良い品揃えを効率的に探索していくことで、各店舗の特性に合わせた品揃えを最小限の試行錯誤で実現できます。

想定される適用範囲
- ダイナミックプライシング
- 品揃え最適化
- 推薦商品のパーソナライズ
- フィットネス計画のパーソナライズ
- 旅行計画のパーソナライズ
研究成果
NECのオンライン最適化技術はアカデミアでも高い評価を得ており、AAAI、NeurIPS、COLTなどをはじめとする最難関AI国際会議に採択されています。
 Ito, Shinji. "On optimal robustness to adversarial corruption in online decision problems." Advances in Neural Information Processing Systems 34 (2021).
Ito, Shinji. "On optimal robustness to adversarial corruption in online decision problems." Advances in Neural Information Processing Systems 34 (2021).- Ito, Shinji. "Hybrid regret bounds for combinatorial semi-bandits and adversarial linear bandits." Advances in Neural Information Processing Systems 34 (2021).
- Ito, Shinji. "Parameter-free multi-armed bandit algorithms with hybrid data-dependent regret bounds." Conference on Learning Theory. PMLR, 2021.
- Matsuoka, Tatsuya, Shinji Ito, and Naoto Ohsaka. "Tracking Regret Bounds for Online Submodular Optimization." International Conference on Artificial Intelligence and Statistics. PMLR, 2021.
- Takemura, Kei, Shinji Ito, Daisuke Hatano, Hanna Sumita, Takuro Fukunaga, Naonori Kakimura, and Ken-Ichi Kawarabayashi. "Near-Optimal Regret Bounds for Contextual Combinatorial Semi-Bandits with Linear Payoff Functions." Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 35. No. 11. 2021.
その他オンライン最適化に関する論文はこちら