Japan
サイト内の現在位置
特徴量とは?AI活用でなぜ必要なのか、なぜ重要なのか、基礎から解説

AIの進化とともに、実際の業務への適用を検討する企業が増えています。実用化にあたっては「いかに精度を高めるか」が大きな課題となります。そこで、AIの手法の1つである「機械学習」において、精度向上の鍵を握るのが「特徴量」です。AI活用において不可欠であり、予測精度に大きく影響する特徴量とは、いったいどのようなものなのでしょうか?
本コラムでは、「AIを活用するために基本的な知識をまず押さえておきたい」という方へ、「特徴量」とはどのようなものか、その精度を高めるための設計方法についてまとめました。
特徴量とは
AI・機械学習では、大量のデータからパターンやルールを自動で学習し、データの分類や予測を実現しますが、この際に必要になるのが「特徴量」です。特徴量は、対象データの特徴を定量的な数値として表したものです。
AIは特徴量としてまとめられたデータをもとに、予測などをおこなうため、その予測精度は特徴量に大きく影響されます。当然ですが、特徴量は「手元にあるデータをなんでも入れればよい」というものではありません。
データを仮説に基づいて選択・設計しますが、関連が薄いデータを指定してしまうと、意図した結果を得られなくなってしまいます。
構造化データと非構造化データの特徴量
特徴量はいったいどんなものなのか、データの種類ごとにもう少し具体的に解説しましょう。
構造化データ
まず、行・列を持ち、表形式に整形されている構造化データについて見ていきます。この場合は、列ごとにどのようなデータがあるのかが明確であり、列単位で特徴量として指定します。
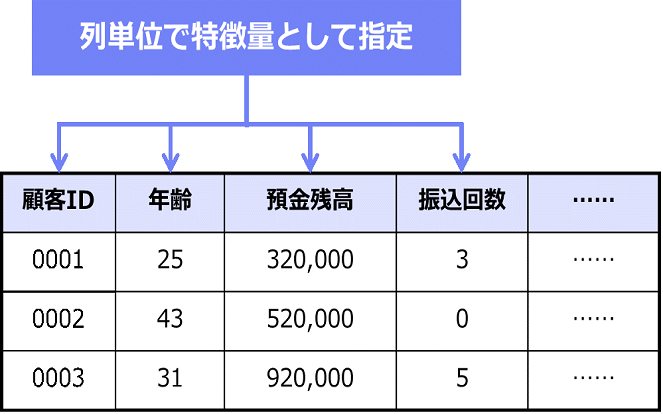
例えば、銀行の営業担当が、お客様が特定の投資商品を契約するかどうかを予測するAIモデルを生成する場合、「お客様の年齢」「直近3ヵ月間の預金残高の平均値」「証券会社への振り込み回数」などが、特徴量の候補になります。
非構造化データ
では、画像・音声・テキストなどの非構造化データはどうでしょうか。こちらは構造化データと異なり、「どこにどのデータがあるか」が明確ではなく、違ったアプローチが必要になります。

例えば、テキスト(自然言語処理)は単語などに分割したり、構文や意味を解析したりすることで、単語や文章の傾向を数値化する方法などがあります。ほかにも画像であれば、ピクセル単位で色が近いところに注目するなどのアプローチがありますが、いずれも構造化データと比較して、人が判断するのは難しく、ディープラーニングなどにより自動で特徴量を導くことが多いです。
特徴量エンジニアリング(特徴量設計)とその重要性
機械学習でなんらかの予測をおこなう際、その対象に影響す るデータは1つではなく、様々なデータベース・テーブルに分散して格納されています。ですが、機械学習で予測するためには、データを1つの表(テーブル)にまとめなければなりません。予測したい内容に関連するデータをピックアップし、特徴量に変換する作業が必要です。
このように様々なデータから機械学習に入力するデータを抽出し、特徴量としてまとめる作業が特徴量エンジニアリング(特徴量設計)です。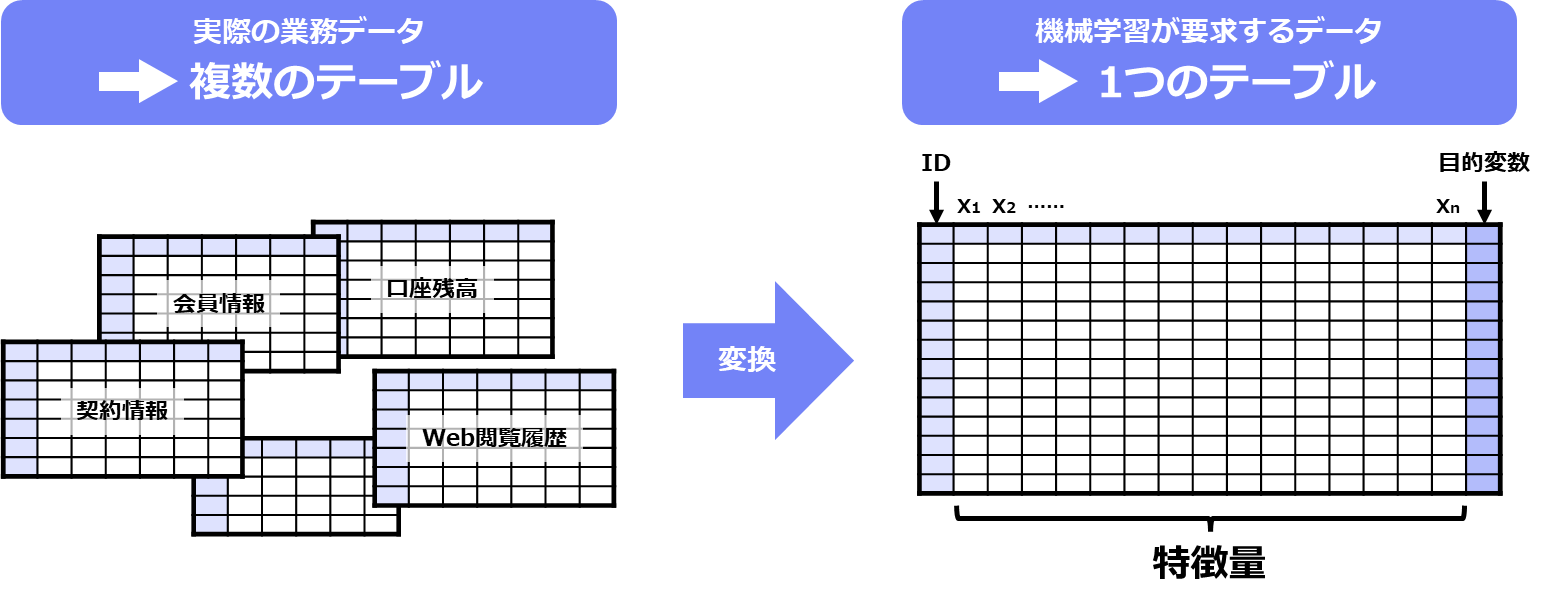
単に既存のデータを1つの表にまとめるだけではなく、「生年月日を年齢に変換する」「来店回数を、リピーターかどうかのフラグに変換する」「売上金額を3ヵ月間の平均値にする」など必要に応じてデータを加工することもあり、この作業には高度なデータサイエンスの専門知識が求められます。
特徴量エンジニアリング(特徴量設計)のプロセス
予測精度の向上を目指すためにも、予測に影響をもたらす重要な情報を漏らさずに特徴量を設計することが鍵となります。そのためには、試行錯誤しながら様々なデータを検証していくしかありません。しっかり成果を出すためにも、特徴量エンジニアリング(特徴量設計)は下記5つのプロセスに沿って進める形が一般的です。
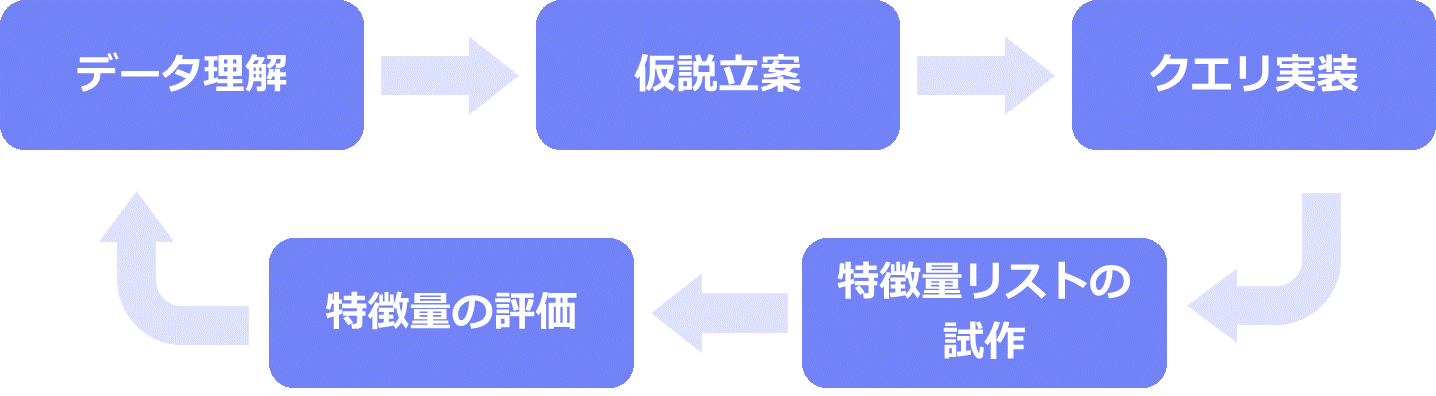
①データ理解
まずは、特徴量の元となる、今ある業務データを理解しなければ始まりません。どのようなデータを取得・蓄積できているのか、どのタイミングでデータを取得しているのか、そのデータからどういった傾向が読み取れるのかなど、BIツールなども活用しながら、理解を進めます。
②仮説立案
データをしっかり理解したら、次は仮説立案です。例えば、「Webサイトに滞在する時間が長い人は、契約する可能性が高いのではないか」など、これまでのデータから見えてきた仮説を立てていきます。仮説を立案し、「どのデータが関連しているか」を判断するためには、データサイエンスの知識だけではなく、実際のビジネスに関するドメイン知識も不可欠です。
③クエリ実装
仮説を立案したら、必要な数字を業務データから抽出し、特徴量を生成するプログラムを実装します。プログラムはPythonやSQLなどのプログラミング用語を用いて開発します。
④特徴量リストの試作
③で開発したプログラムを用いて、機械学習に投入する特徴量リストを試作します。
⑤特徴量の評価
試作した特徴量リストを用いて、機械学習で分析をおこない、その結果を評価します。
もちろん、このプロセスは1度おこなって終わりではありません。導かれた結果をもとに、「この特徴量は影響が少なかった」などを判断し、対象とするデータを入れ替えるなど、仮説立案から評価のサイクルを繰り返していくことになります。
これらのプロセスでは、専門知識と高度なスキルが求められる上、時間もかかり、1つの特徴量を設計するのに数ヵ月かかり、負担の大きい作業と言えます。
また、作成する特徴量リストの品質は、アウトプットの品質、すなわち予測精度に直結します。特徴量設計をビジネス知識がないまま進めた結果、「せっかく精度の高いモデルが完成したのに、現場では使えない」というケースも少なくありません。このギャップをどう解消するかも大きな課題となっています。
特徴量設計を完全自動化するAI自動化ソリューション「dotData」
「専門知識が必要」「設計に時間がかかる」「ビジネスの現場とのギャップが生まれてしまう」……と様々な課題を一気に解決するのがAI自動化ソリューション「dotData」です。データサイエンスのプロセス全体を自動化するため、専門知識がなくても、AI・機械学習を活用できるようになります。
さらに、dotData独自の「特徴量自動設計」技術は、元となるデータをインプットするだけで、多様な観点に基づいた特徴量を生成します。さらに、導き出された特徴量は、「人が見て理解することができる」解釈性の高いホワイトボックス型になっている上、データごとにスコアが表示されるため、どのデータを採用するかの判断も容易になります。このように、現場の担当者自身で、どのデータをもとにAI・機械学習で予測分析するのかなどを判断できるようになり、データサイエンスとビジネスのギャップも解消できます。
DX・データ活用が進むとともに、「いかにビジネスの現場で成果を出すか」が求められています。そのためには、AI・機械学習の精度向上で重要なポイントとなる特徴量設計も、よりビジネス現場に近いところでおこなうことが、近道となります。現場担当者のデータ活用をサポートするdotDataがもたらす効果は大きいはずです。