
Japan
サイト内の現在位置
PostgreSQL
pg_bulkloadを用いたデータ高速ロードの実現方法
本ページでは、pg_bulkloadを用いたデータ高速ロードの実現方法について解説します。サンプルシナリオでは具体的な運用例についてもご紹介していますので、ぜひ最後までご覧ください。
pg_bulkloadのメリット
pg_bulkloadを使用することによって、PostgreSQL本体のCOPYコマンドよりも高速にデータをロードできます。
実際に両者の性能を比較してみたところ、初期ロード、追加ロードそれぞれにおいて、COPYコマンドよりもpg_bulkloadの方が高速でロードできていることがわかります。
※pg_bulkloadの機能概要についてはこちらをご覧ください
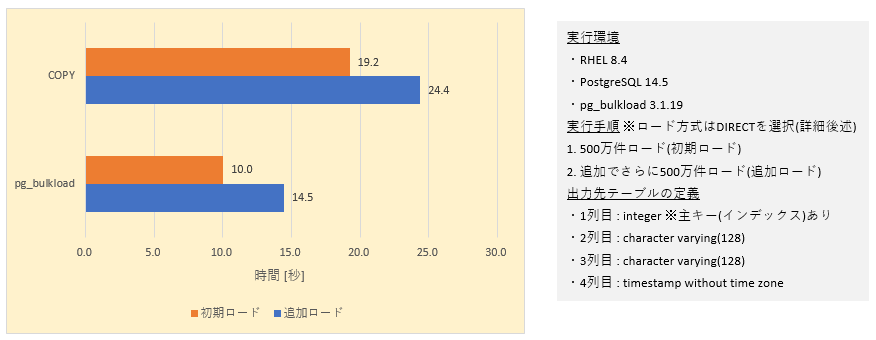
図1 比較結果
pg_bulkloadの使い方
初期設定
pg_bulkload用関数をPostgreSQLに登録するために、以下の項目をpostgresユーザーで実行します。この操作はpg_bulkloadを使用したいデータベースごとに実行する必要があります。
$ psql
postgres=# CREATE EXTENSION pg_bulkload;
ロード実行時に指定できる入力元・出力先データ種別
ロード時に指定できる入力元、出力先データのタイプは以下の通りです。
|
データタイプ |
制御ファイル内での記述 |
説明 |
|---|---|---|
| CSVファイル(デフォルト) |
CSV |
CSV フォーマットのテキストデータを読み込む。 |
| 固定長バイナリファイル |
BINARY | FIXED |
固定長のバイナリデータを読み込む。 |
| 指定した関数が返した 行セット |
FUNCTION |
関数が返した行セットを読み込む。 |
入力データタイプは制御ファイル内で以下のように指定します。
TYPE = CSV | BINARY | FIXED | FUNCTION
|
データタイプ |
説明 |
|---|---|
| データベース内のテーブル |
データベース内のテーブルに出力する。 |
| 固定長バイナリファイル |
固定長バイナリファイルに出力する。 |
ロード設定の指定方法
ロード設定の指定方法には以下の2種類があります。
コマンドラインオプション
コマンドラインで指定する方法です。以下のように記述します。
$ pg_bulkload [各種パラメータ]
(実行例)
$ pg_bulkload -i /var/lib/pgsql/input_data.csv -O output_table
NOTICE: BULK LOAD START
NOTICE: BULK LOAD END
0 Rows skipped.
2 Rows successfully loaded.
0 Rows not loaded due to parse errors.
0 Rows not loaded due to duplicate errors.
0 Rows replaced with new rows.
-iで入力元、-Oで出力先を指定しています。手軽に使用できますが複雑なオプション設定には対応していません。
制御ファイル
あらかじめ各種パラメータを定義した制御ファイル(テキストファイル)を作成しておき、以下のように記述します。
$ pg_bulkload [制御ファイル名]
(実行例)
$ cat control_file.ctl
#
# pg_bulkload (Control file)
#
INPUT = /var/lib/pgsql/input_data.csv #入力元
OUTPUT = output_table #出力先
WRITER=DIRECT #ロード方式
$ pg_bulkload /var/lib/pgsql/control_file.ctl
NOTICE: BULK LOAD START
NOTICE: BULK LOAD END
0 Rows skipped.
2 Rows successfully loaded.
0 Rows not loaded due to parse errors.
0 Rows not loaded due to duplicate errors.
0 Rows replaced with new rows.
制御ファイルを作成する手間はありますが、複雑なオプション設定が可能です。
[補足]
ロード方式の指定は以下のように記述します。
WRITER | LOADER = DIRECT(デフォルト) | BUFFERED | BINARY | PARALLEL
| 方式 |
バックアップ対象 |
|---|---|
| DIRECT |
共有バッファを使用せず、テーブルに直接ロードする。高速だが特殊なリカバリ手順が必要。 |
| BUFFERED |
共有バッファを使用してロードする。PostgreSQL本体のCOPYコマンドに近く、低速。 |
| BINARY |
バイナリファイルに出力する。出力時、出力したバイナリファイルロード用の |
| PARALLEL |
「WRITER = DIRECT」と「MULTI_PROCESS = YES」(マルチプロセスで実行)を指定した場合と同じ。MULTI_PROCESSの指定は無視される。 |
ロード実行時のデータチェック
ロード実行時における各種データチェックについて説明します。
一意制約
一意制約違反のレコードがないかチェックします。このチェックは常に行われます。
以下の内容を制御ファイル内で指定します。
・許容件数
DUPLICATE_ERRORS = [許容件数] (デフォルト:0)
一意制約違反によるエラーの許容件数を指定します。「0」でまったく許容しない、「-1」または「INFINITE」ですべて許容となります。
一意制約違反のエラーがここで許容した件数を超えた場合、その時点でロールバックされてロード処理全体が取り消されます。たとえば、デフォルトの0件だとロード中に1件でも一意制約違反が発生した時点で全てロールバックされます。
・一意制約違反があった場合のレコードの取り扱い
ON_DUPLICATE_KEEP = NEW (入力元データで上書き(デフォルト))/ OLD (出力先側のデータを残す)
一意制約違反があった場合に、レコードを入力元データで上書きするか出力先側のデータを残すか指定できます。
・一意制約違反の不良レコードを記録するファイルのパス
DUPLICATE_BADFILE = [一意制約違反レコードの記録ファイルフルパス]
一意制約違反のエラーレコードがあった場合、そのレコードを記録するファイルのファイル名と作成先を指定することができます。指定しない場合はデフォルトで「$PGDATA/pg_bulkload/[年月日時分秒]_[DB名]_[スキーマ名]_[テーブル名].dup.csv 」になります。
一意制約違反以外のエラー
文字エンコード、検査制約、パースエラーや非NULL制約など、一意制約以外のチェックについて説明します。
文字エンコードの正当性チェックと検査制約のチェックはデフォルトでは行われませんが、これらを除く一意制約違反以外のエラー(パースエラーや非NULL制約など)のチェックは常に行われます。
・文字エンコード
ENCODING = [入力データのエンコード名]
指定することで、入力データのエンコーディングを検証し、必要に応じてエンコーディングを変換します。デフォルトではこの検証と変換は行われません。
入力データと出力先データベース内のエンコードが同じ場合は、ENCODINGパラメータを指定しないことでチェックとコード変換がスキップされ、高速にロードできます。
・検査制約
CHECK_CONSTRAINTS = YES (ロード時に検査制約のチェックを行う) /NO (ロード時に検査制約のチェックを行わない (デフォルト))
検査制約チェックの有無を指定できます。デフォルトではロード時の検査制約チェックは行われない点に注意してください。
・許容件数
PARSE_ERRORS = [許容件数] (デフォルト:0)
一意制約違反以外のエラーの許容件数を指定します。「0」でまったく許容しない、「-1」または「INFINITE」ですべて許容となります。
一意制約違反以外のエラーがここで許容した件数を超えた場合、その時点でコミットされて残りの入力データのロードは行われません。たとえば、デフォルトの0件だとロード中に1件でも一意制約違反以外のエラーが発生した時点でコミットされロード処理は終了されます。
・一意制約違反以外の不良レコードを記録するファイルのパス
PARSE_BADFILE = [一意制約違反以外の不良レコードの記録ファイルフルパス]
一意制約違反以外のエラーレコードがあった場合、そのレコードを記録するファイルのファイル名と作成先を指定することができます。指定しない場合はデフォルトで「$PGDATA/pg_bulkload/[年月日時分秒]_[DB名]_[スキーマ名]_[テーブル名].prs.[入力元ファイルの拡張子] 」になります。
ロード実行後の終了コード
終了コードを確認することで、ロード終了後の状態がわかります。終了コードの一覧を以下に示します。
終了コード1の場合の動作例を示します。
1. 入力元ファイル内容確認
|
終了コード |
意味 |
補足説明 |
|---|---|---|
| 0 |
正常終了 |
スキップされた行 (Rows skipped) や、置換された行 (Rows replaced, ON_DUPLICATE_KEEP = NEW) が |
| 1 |
PostgreSQLでSQLを実行中にエラー発生 |
許容件数を超えた一意制約違反エラーが |
| 2 |
PostgreSQLへの接続に失敗 |
- |
| 3 |
準正常終了 |
許容件数を超えたパースエラー・ |
$ cat input_data.csv
1,AAA
1,BBB
3,CCC
出力先テーブルの1列目に一意制約があり、空の状態でロードするものとします。
2. ロード実行
$ pg_bulkload /var/lib/pgsql/control_file.ctl
NOTICE: BULK LOAD START
ERROR: query failed: ERROR: could not create unique index "output_table_pkey"
DETAIL: Key (id)=(1) is duplicated.
DETAIL: query was: SELECT * FROM pgbulkload.pg_bulkload($1)
2列目の"1"で一意制約違反が起こっています。
3. 終了コード確認
$ echo $?
1
SQL実行中にエラーが発生したため、1が返されました。
サンプルシナリオ
実際の運用を想定した動作例を示します。ロード実行後、入力元データにエラーレコードがあったためその修正をし、再度ロードを実行するという想定です。
作業の大まかな流れは以下の通りです。
1. 制御ファイル作成
2. ロード実行
3. 終了コード確認
4. 実行結果確認
5. 実行ログ確認
6. 入力元データ修正
7. 制御ファイル修正
8. 修正したレコードのみロード実行
詳細な手順を説明します。
1. 制御ファイル作成
制御ファイルを任意の場所に作成します。(例) /var/lib/pgsql/control_file.ctl
#-------------------------------
# pg_bulkload (Control file)
#-------------------------------
# 入出力の指定
INPUT = /var/lib/pgsql/input_data.csv
OUTPUT = output_table
# エラーチェックの指定
PARSE_ERRORS = -1
# その他の指定
WRITER = DIRECT
2. ロード実行
1. で作成した制御ファイルをパラメータに指定してpg_bulkloadを実行します。
$ pg_bulkload /var/lib/pgsql/control_file.ctl
3. 終了コード確認
終了コードを確認します。
$ echo $?
3
"3"は準正常終了で、ロードされていないデータがあることがわかります。
4. 実行結果確認
ロード結果のサマリ表示部分を確認します。
$ pg_bulkload /var/lib/pgsql/control_file.ctl
NOTICE: BULK LOAD START
NOTICE: BULK LOAD END
0 Rows skipped.
999998 Rows successfully loaded.
2 Rows not loaded due to parse errors.
0 Rows not loaded due to duplicate errors.
0 Rows replaced with new rows.
WARNING: some rows were not loaded due to errors.
一意制約違反以外のエラーが2件あることがわかります。
5. 実行ログ確認
実行ログファイルでエラーの詳細を確認します。
$ cat 20221226144109_postgres_public_output_table.log
pg_bulkload 3.1.19 on 2022-12-26 14:41:09.902803+09
INPUT = /var/lib/pgsql/input_data.csv
PARSE_BADFILE = /var/lib/pgsql/14/data/pg_bulkload/20221226144109_postgres_public_output_table.prs.csv
LOGFILE = /var/lib/pgsql/14/data/pg_bulkload/20221226144109_postgres_public_output_table.log (中略)
Parse error Record 1: Input Record 499999: Rejected - column 1. null value in column "id" violates not-null constraint
Parse error Record 2: Input Record 999999: Rejected - column 3. missing data for column "update_time"
(後略)
実行ログファイルはコマンドラインオプションまたは制御ファイル内で作成先を指定することができます。指定しない場合でも常にpg_bulkloadのデフォルトディレクトリ内に作成されます。デフォルトの実行ログファイルフルパスは、「 $PGDATA/pg_bulkload/[年月日時分秒]_[DB名]_[スキーマ名]_[テーブル名].log 」です。
実行ログより、
・499999件目のレコードで、「id」列が非NULL制約に違反している
・999999件目のレコードで、「update_time」列の値が存在しない(パースエラー)
ことがわかります。
6. 入力元データ修正
5. の結果をもとに入力元データを修正し、修正したレコードのみの新たなCSVファイルを作成します。
#修正前のレコード
$ cat 20221226144109_postgres_public_output_table.prs.csv
,テスト用データ_ユーザー499999,user_id_499999@email.co.jp,2022-12-26 10:41:36.884498
999999,テスト用データ_ユーザー999999
#修正後のレコード
$ cat /var/lib/pgsql/input_data_2.csv
499999,テスト用データ_ユーザー499999,user_id_499999@email.co.jp,2022-12-26 10:41:36.884498
999999,テスト用データ_ユーザー999999,user_id_999999@email.co.jp,2022-12-26 10:50:00.000000
7. 制御ファイル修正
次のロードでは、6. で作成した修正レコードのみのCSVファイルをロードするため、制御ファイルを書き換えます。
#-------------------------------
# pg_bulkload (Control file)
#-------------------------------
# 入出力の指定
INPUT = /var/lib/pgsql/input_data_2.csv #変更箇所
OUTPUT = output_table
# エラーチェックの指定
PARSE_ERRORS = -1
# その他の指定
WRITER = DIRECT
8. 修正したレコードのみロード実行
$ pg_bulkload [制御ファイル名フルパス]
(例)
$ pg_bulkload /var/lib/pgsql/control_file.ctl
NOTICE: BULK LOAD START
NOTICE: BULK LOAD END
0 Rows skipped.
2 Rows successfully loaded.
0 Rows not loaded due to parse errors.
0 Rows not loaded due to duplicate errors.
0 Rows replaced with new rows.
$ echo $?
0
エラーだった2件がロードされ、正常終了しました。
注意事項
pg_bulkloadをダイレクトロード(WRITER=DIRECT または PARALLEL)で使用する場合の重要な注意事項について説明します。
クラッシュ時
ロード実行中にクラッシュし、「$PGDATA/pg_bulkload」ディレクトリ内に「.loadstatus」ファイルが残っていた場合、特殊なリカバリ手順が必要です。
#リカバリ手順
$ pg_bulkload -r
$ pg_ctl start
PITR(ポイントインタイムリカバリ)利用時
適切なWALを残さないため、pg_bulkloadを利用したときのWALを用いると正常にリカバリできません。PITRを利用する場合は、pg_bulkloadによるロード終了後に対象のデータベースのバックアップを再取得し、その時点を起点としてください。
ストリーミングレプリケーション
適切なWALを残さないため、pg_bulkloadを利用したときのWALを用いると正常にレプリケーションできません。ストリーミングレプリケーションを利用している場合は、ロード終了後の対象データベースのバックアップからスタンバイを作り直してください。
Advancedサポートサービスのご紹介
PostgreSQL保守Advancedサポートサービスでは、PostgreSQL技術者による24時間365日体制のサポートのもと、PostgreSQLの技術的な問い合わせや、障害調査、pg_bulkloadを含む指定のOSSツールのサポートに対応します。詳細はこちらをご覧ください。

お問い合わせ