
Japan
サイト内の現在位置
PostgreSQL
周辺OSSツール紹介
Pgpool-Ⅱ機能紹介
データベースシステムを運用する際、障害に強い高可用で処理性能が高いシステムが求められます。
本ページでは、単一のPostgreSQL構成では実現できないこれらのシステム要求を満たすために、Pgpool-IIを利用した高可用、高性能を実現する機能について紹介します。
以降の機能説明では、Pgpool-IIバージョンは4.2.6が前提となります。
また、PostgreSQLサーバーのクラスタ構成として、ストリーミングレプリケーション機能を利用した構成を前提として説明します。
高可用性を実現する機能
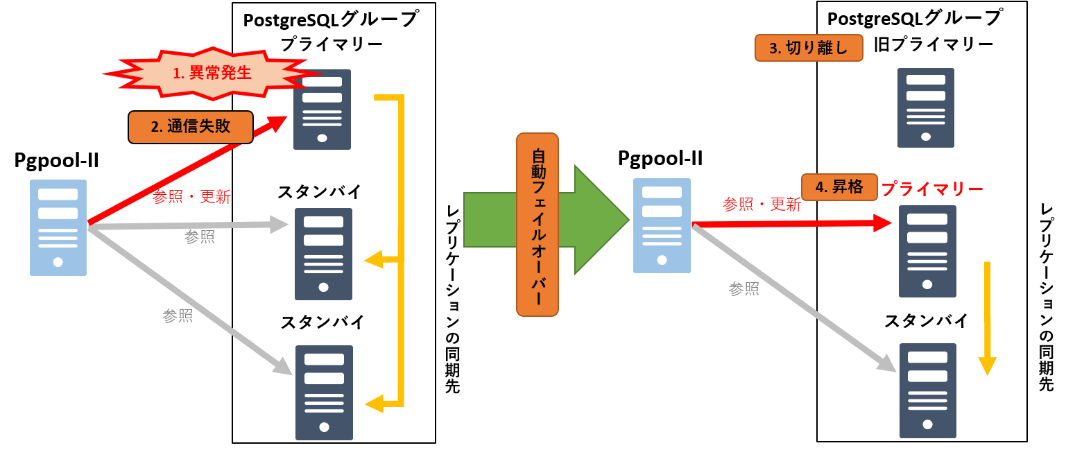
1. 自動フェイルオーバー機能
自動フェイルオーバー機能は、Pgpool-IIがプライマリーサーバーで異常を検知した際に、自動的に障害サーバーを切り離して、残りのサーバーで処理を継続させる機能です。
自動フェイルオーバーの発生契機は、Read/Write失敗・シャットダウン検知等があります。また、ヘルスチェック機能を利用することにより、定期的にPostgreSQLに接続して、PostgreSQLが正常に稼働しているかどうかを確認することもできます。
ヘルスチェック機能は、パラメータ設定により監視間隔など様々な調整ができます。
パラメータについて一部紹介します。システム要件に応じて、設定値を検討・テストする必要があります。
ヘルスチェック機能
定期的にPostgreSQLデータベースへ接続をすることでシステム正常性をチェックします。
- ・接続先について
ヘルスチェック(接続)を行う、対象PostgreSQLデータベース名・ユーザ名をパラメータ「health_check_database」「health_check_user」で指定します。
- ・監視間隔について
接続間隔(秒)はパラメータ「health_check_period」で指定します。
デフォルトは 0 でヘルスチェック無効を意味します。
- ・リトライ回数・リトライ間隔について
ヘルスチェック(接続)に失敗する場合、フェイルオーバーを始める前にリトライする最大回数はパラメータ「health_check_max_retries」で指定します。
一時的な障害の検知を抑止する際に有用です(誤検知の防止に有用です)。
「health_check_max_retries」を有効にする場合は、後述する「failover_on_backend_error」をoff(無効)にするのが望ましいです。
リトライ間隔(秒)はパラメータ「health_check_retry_delay」で指定します。
自動フェイルオーバー機能の動作設定
パラメータ「failover_on_backend_error」を on に設定することで、PostgreSQLバックエンド接続からの Read/Write エラーをバックエンドノードの故障と見なし、現在のセッションを切断した後にそのノードをフェイルオーバーします。
off に設定した場合は、Read/Write エラーの場合、エラーをレポートしてセッションを切断します(フェイルオーバーしません)。
2. Watchdog機能
Pgpool-II自身を冗長化させるための機能です。
Watchdog機能はアクティブ/スタンバイ構成のPgpool-IIサーバー同士で互いに監視し、障害が発生した際でも自動フェイルオーバーを行い、運用を継続させます。
アクティブサーバーが仮想IPを持ち、フェイルオーバー時に新たにアクティブになったサーバーで同一のIPアドレスで仮想IPが起動されるため、アプリケーション側で意識することなく、運用を継続することができます。
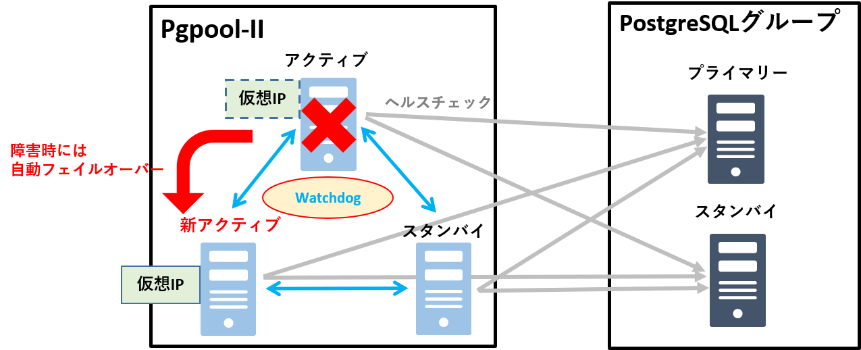
Pgpool-II複数構成での注意点
Pgpool-II複数構成では、PostgreSQLサーバーの故障判断をPgpool-IIサーバーの多数決で判断しています。
そのため、多数決で判断できるようにPgpool-IIサーバーを3台以上の奇数台で構成することが推奨されています。※
下図のようにアクティブPgpool-IIサーバー・プライマリーPostgreSQL間でネットワーク障害があった場合、アクティブPgpool-IIサーバーは、プライマリーPostgreSQLを故障と判断してしまいますが、2台のスタンバイPgpool-IIサーバーは生存していると判断し、多数決でプライマリーPostgreSQLは生存していると判断できます。

また、多数決による故障判断はPgpool-II間での死活監視でも行われており、複数のPgpool-IIサーバーがアクティブ状態になってしまうスプリットブレインを回避することができます。
- ※Pgpool-II2台構成も可能です。パラメータ「enable_consensus_with_half_votes」をonにすることで、1台のPgpool-IIサーバーのみで判断ができるようになります。
ただし、この場合でもPgpool-IIサーバーのスプリットブレインを防ぐことはできません。
設定関連
- ・Pgpool-II死活監視
デフォルトではWatchdog機能は無効になっているため、パラメータ「use_watchdog」をonに設定します。
死活監視方法はパラメータ「wd_lifecheck_method」で指定します。
指定できる値は"heartbeat"、"query"、"external"です。
"heartbeat"では、UDPハートビート信号を用いて、死活監視を行います。
"query"では、監視用クエリを発行することで死活監視を行います。
"external"を指定すると、Pgpool-II機能での死活監視は行わず、外部システムを用いて死活監視を行います。
死活監視方法はパラメータ「wd_lifecheck_method」で指定します。
指定できる値は"heartbeat"、"query"、"external"です。
"heartbeat"では、UDPハートビート信号を用いて、死活監視を行います。
"query"では、監視用クエリを発行することで死活監視を行います。
"external"を指定すると、Pgpool-II機能での死活監視は行わず、外部システムを用いて死活監視を行います。
- ・Pgpool-IIフェイルオーバーの挙動
パラメータ「delegate_IP」に仮想IPを設定します。
Pgpool-IIがフェイルオーバーするときに動作する仮想IPの起動/停止、ARPリクエストの送信を行うコマンドをパラメータ「if_up_cmd」「if_down_cmd」 「arping_cmd」に設定します。
パラメータ「wd_escalation_command」にアクティブノードに昇格したときに実行されるコマンドを設定します。
Watchdogプロセスの異常で旧アクティブノードに仮想IPが起動したまま、新アクティブで同一の仮想IPが起動されることを防ぐために、旧アクティブノードで仮想IPを停止するコマンドを設定します。
パラメータ「wd_escalation_command」にアクティブノードに昇格したときに実行されるコマンドを設定します。
Watchdogプロセスの異常で旧アクティブノードに仮想IPが起動したまま、新アクティブで同一の仮想IPが起動されることを防ぐために、旧アクティブノードで仮想IPを停止するコマンドを設定します。
- ・PostgreSQLサーバーのフェイルオーバーの挙動
パラメータ「failover_when_quorum_exists」をonにすることで、多数決による故障判断を行うように設定できます。
offに設定した場合、障害を検知すると多数決を取れていなくてもフェイルオーバーを実行します。
offに設定した場合、障害を検知すると多数決を取れていなくてもフェイルオーバーを実行します。
性能を向上する機能
1. 複数サーバーへのクエリ分散機能
Pgpool-IIでは、PostgreSQL本体には無い機能として、クエリ分散(負荷分散)の機能があります。
これにより、参照クエリを効率的に振り分け、負荷を分散し、性能を向上できます。
本機能は、ストリーミングレプリケーション機能、および、ホットスタンバイ構成が前提となります。
ただし、参照クエリが負荷分散の対象になるため、更新クエリが多いシステムについては、性能の向上が見込めない可能性があります。

負荷分散モード
パラメータ「statement_level_load_balance」で設定します。選択できるモードは2つあり、onまたはoffで設定します。
- ・セッションレベル (off)
デフォルトはoffで、セッションレベルで負荷分散されます。
セッションが始まり、そのセッションが終了するまで負荷分散先は変わりません。
- ・ステートメントレベル(on)
onに設定すると、セッションごとではなく、クエリごとに負荷分散先を決めることができるため、コネクションプールなどバックエンドサーバに接続したままのようなアプリケーションの場合は、onに設定することで、負荷分散機能を活用できます。
負荷分散の重み付け(比率)
参照系クエリをどのサーバでどのくらい処理を行うか、サーバごとに負荷分散させる比率を設定することができます。
例えば、プライマリーを更新処理専用にし、全ての参照クエリを同じ比率でスタンバイに振り分ける場合、以下のようにパラメータ「backend_weight」で負荷分散の比率を指定します。
パラメータ名の末尾に数字を付加することで複数のPostgreSQLサーバーを指定できます。
backend_weight0 = 0
backend_weight1 = 1
backend_weight2 = 1
backend_weight1 = 1
backend_weight2 = 1
クエリの振り分け先
以下のパラメータにより、データベース名、アプリケーション名でクエリの振り分け先を指定できます。
- ・データベース名によってクエリの振り分け先を決定
パラメータ「database_redirect_preference_list」で設定
- ・アプリケーション名によってクエリの振り分け先を決定
パラメータ「app_name_redirect_preference_list」で設定
「app_name_redirect_preference_list」は「database_redirect_preference_list」よりも優先されます。 特定クエリの振り分け除外
パラメータ「primary_routing_query_pattern_list」を以下のように設定することで、「my_table」を含むクエリを負荷分散させないようにすることが可能です。
primary_routing_query_pattern_list = '.*my_table*.'
設定では、SQLパターンをセミコロン区切りで指定し、SQLのマッチングに正規表現を使うことができます。上記の設定例では、SELECT * FROM my_table は負荷分散されません。
この機能を使用する場合、パフォーマンスが低下する可能性があります。
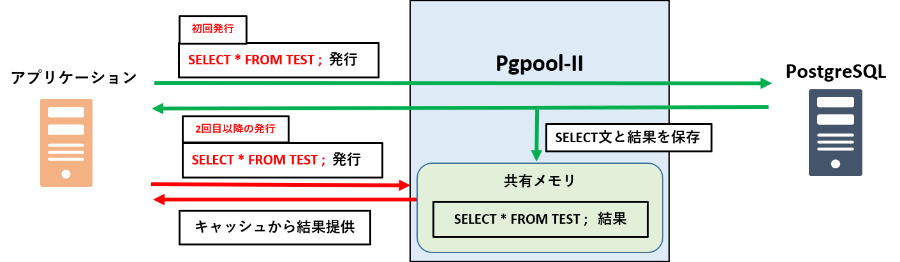
2. クエリキャッシュ機能
クエリキャッシュ機能では、SELECT文とその検索結果を記録し、同じSELECT文が発行された場合にPgpool-IIはキャッシュから結果を返すことで通常よりも高速に処理を行います。
特に、更新がそこまで頻繁でなく、同じSELECT文を大量に発行するようなシステムでは飛躍的な性能向上が見られます。
また、あるテーブルが更新された場合、自動的にそのテーブルに関係するキャッシュが削除される機能があります。
そのため、削除処理のオーバーヘッドにより、更新が頻繁にあるシステムは、パフォーマンスが低下する可能性があります。
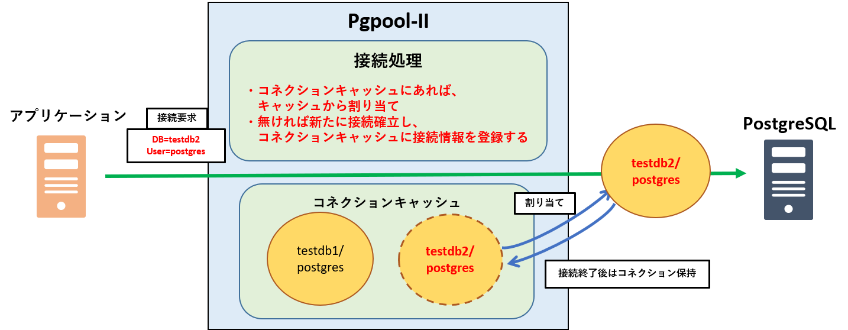
3. コネクションプーリング機能
通常、データベースへの接続には時間がかかったり、接続のための余分な処理が必要とされます。
そのため、データベースへの接続という操作を繰り返し行うと、通常よりもオーバーヘッドが増加します。
Pgpool-IIのコネクションプーリング機能ではデータベースへのコネクションを保持でき、保持したコネクションを再使用することで、データベースへ接続する際の余分な処理がなくなり、オーバーヘッドを軽減できます。

お問い合わせ