Japan
サイト内の現在位置
クラスタリングとt-SNE(次元削減)における学習時間の短縮(scikit-learn比較)
no.014 Frovedis機械学習 教師なし学習編2021.9.17 教師なし学習とは、その名が示す通り正解を示す指標が存在しないデータセットを用いて、そこから何かの情報を引き出す学習の総称です。教師あり学習では入力データに対応する出力(正解)データがセットになっているおかげで、学習モデルによる推論の正しさを検証することができました。しかし、教師なし学習では正解不正解を示す物差しが存在しないため、学習モデルが適切な推論結果を出しているか、判断することは一般的に困難である、という特徴を持ちます。
ここで、前回からの流れを把握していただくために次の図を掲載します。
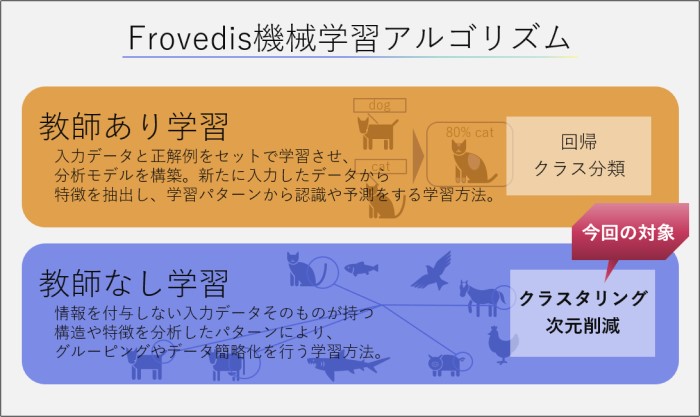
教師なし学習の用途は2つに大別されます。一つ目はデータセットの特徴に応じてグループに分けるクラスタリングです。例えば個々のニュース記事に含まれる単語の類似性をもとにして、政治、経済、スポーツなどに記事のグループ分けを行うといった用途です。各グループの名称は教師なし学習が自動的に付与しないため、人による判断で個々にラベリングする必要があります。また、グループ分けされた結果の確からしさも人による判断が求められます。
そして二つ目はデータの次元削減と呼ばれるもので、高次元の特徴量を持つデータセットを低次元に変換します。これにより、データが持つ特徴を視覚的に分かりやすく示すことができます。高次元の特徴量を持つデータセットは、その特徴をグラフ化して把握することは容易ではありません。そのため、高次元の特徴量から特徴を決める上で重要な変数の作成や、高次元空間でのデータ間の距離をもとに低次元空間でのデータに変換するなどの次元削減が有用です。
今回の教師なし学習アルゴリズムサンプルには、あらかじめニュース記事を単語分割したうえでword2vecを用いてベクトル化したデータセットを使用します。そして、はじめにk-means クラスタリングを用いてニュース記事に含まれる単語のグループ分けを行います。t-SNEによるデータ特徴量の視覚化を実施した後、DBSCANアルゴリズムで再びクラスタリングを行います。この際、それぞれの学習アルゴリズムにおける学習に要する時間を、Frovedisとscikit-learnで計測します。
In [1]:
import numpy as np
import pandas as pd
from frovedis.mllib import Word2Vec
from gensim.models import word2vec
from sklearn.cluster import KMeans
from collections import defaultdict
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
import csv
import sys, os, time, csv
from frovedis.exrpc.server import FrovedisServer
import warnings
/home/user01/.local/lib/python3.6/site-packages/gensim/similarities/__init__.py:15: UserWarning: The gensim.similarities.levenshtein submodule is disabled, because the optional Levenshtein package <https://pypi.org/project/python-Levenshtein/> is unavailable. Install Levenhstein (e.g. `pip install python-Levenshtein`) to suppress this warning. warnings.warn(msg)
ベクトル化された単語データロード¶
In [2]:
model = word2vec.Word2Vec.load("word2vec.finance_news_cbow500.model")
#max_vocab = 50000000000000
vocab = list(model.wv.key_to_index.keys())[:]
vectors = [model.wv[word] for word in vocab]
Frovedis k-Meansによるクラスタリング¶
In [3]:
from frovedis.mllib.cluster import KMeans as frovKM
FrovedisServer.initialize("mpirun -np 2 {}".format(os.environ['FROVEDIS_SERVER']))
t1 = time.time()
f_est = frovKM(n_clusters=8, init='random', algorithm='full', random_state=123, n_init=1).fit(vectors)
t2 = time.time()
FrovedisServer.shut_down()
print("Frovedis KMeans train time: {:.3f} sec".format(t2-t1))
print(set(f_est.labels_))
u, counts = np.unique(np.array(f_est.labels_), return_counts=True)
print(u, counts)
Frovedis KMeans train time: 0.081 sec
{0, 1, 2, 3, 4, 5, 6, 7}
[0 1 2 3 4 5 6 7] [1756 2514 2775 1972 2478 2090 3905 2602]
In [4]:
cluster_labels = f_est.labels_
cluster_to_words = defaultdict(list)
for cluster_id, word in zip(cluster_labels, vocab):
cluster_to_words[cluster_id].append(word)
for i in range(len(cluster_to_words.values())):
print(list(cluster_to_words.keys())[i], list(cluster_to_words.values())[i][:25])
print("----------------------------------")
6 ['u.s.', 'market', 'china', 'fed', 'economy', 'covid-19', 'investor', 'economic', 'global', 'growth', 'time', 'business', 'add', 'cut', 'far', 'get', 'think', 'move', 'continue', 'demand', 'people', 'well', 'world', 'policy', 'inflation'] ---------------------------------- 0 ['year', 'trade', 'rise', 'last', 'week', 'stock', 'month', 'price', 'new', 'expect', 'report', 'point', 'data', 'gain', 'dollar', 'high', 'yield', 'end', 'day', 'increase', 'accord', 'fell', 'close', 'show', 'wednesday'] ---------------------------------- 3 ['company', 'share', 'firm', 'group', 'announce', 'revenue', 'airline', 'france', 'corp', 'shareholder', 'maker', 'operate', 'stake', 'unit', 'co', 'giant', 'retailer', 'dividend', 'rival', 'electric', 'boeing', 'ltd', 'motor', 'chip', 'spain'] ---------------------------------- 7 ['bank', 'government', 'include', 'fund', 'plan', 'work', 'debt', 'use', 'issue', 'cost', 'tax', 'loan', 'finance', 'offer', 'source', 'pay', 'purchase', 'provide', 'public', 'benefit', 'program', 'rule', 'cash', 'account', 'reduce'] ---------------------------------- 2 ['donald trump', 'deal', 'country', 'president', 'tell', 'u.k.', 'meet', 'state', 'e.u.', 'official', 'call', 'talk', 'news', 'comment', 'two', 'joe biden', 'administration', 'statement', 'agreement', 'agree', 'national', 'foreign', 'election', 'italy', 'decision'] ---------------------------------- 1 ['analyst', 'investment', 'chief', 'financial', 'economist', 'note', 'capital', 'head', 'strategist', 'equity', 'security', 'executive', 'senior', 'research', 'new york', 'manager', 'write', 'strategy', 'director', 'partner', 'management', 'goldman sachs', 'manage', 'portfolio', 'jpmorgan'] ---------------------------------- 5 ['tariff', 'industry', 'supply', 'american', 'home', 'goods', 'order', 'worker', 'production', 'health', 'export', 'product', 'lockdown', 'international', 'import', 'build', 'restriction', 'travel', 'canada', 'power', 'reopen', 'region', 'city', 'impose', 'producer'] ---------------------------------- 4 ['service', 'technology', 'value', 'tech', 'list', 'ceo', 'apple', 'invest', 'bitcoin', 'ipo', 'name', 'customer', 'cryptocurrency', 'valuation', 'online', 'amazon', 'tesla', 'launch', 'digital', 'medium', 'platform', 'hedge fund', 'facebook', 'spac', 'model'] ----------------------------------
scikit-learn k-Meansによるクラスタリング¶
In [5]:
from sklearn.cluster import KMeans as skKM
t1 = time.time()
s_est = skKM(n_clusters=8, init='random', algorithm='full', random_state=123, n_init=1).fit(vectors)
t2 = time.time()
print("scikit-learn KMeans train time: {:.3f} sec".format(t2-t1))
print(set(s_est.labels_))
scikit-learn KMeans train time: 0.677 sec
{0, 1, 2, 3, 4, 5, 6, 7}
Frovedis t-SNEを使った次元削減¶
In [6]:
from frovedis.mllib.manifold import TSNE as frovTSNE
FrovedisServer.initialize("mpirun -np 2 " + os.environ["FROVEDIS_SERVER"])
t1 = time.time()
f_est = frovTSNE(n_components=2, method="exact").fit_transform(vectors)
t2 = time.time()
print("Frovedis t-SNE train time: {:.3f} sec".format(t2-t1))
FrovedisServer.shut_down()
Frovedis t-SNE train time: 18.727 sec
scikit-learn t-SNEを使った次元削減¶
In [7]:
from sklearn.manifold import TSNE as skTSNE
t1 = time.time()
s_est = skTSNE(n_components=2, method='barnes_hut').fit_transform(vectors)
t2 = time.time()
print("scikit-learn t-SNE train time: {:.3f} sec".format(t2-t1))
scikit-learn t-SNE train time: 198.753 sec
Frovedis t-SNEによる次元削減後のデータのグラフ化¶
In [8]:
FrovedisServer.initialize("mpirun -np 2 " + os.environ["FROVEDIS_SERVER"])
clustered = frovKM(n_clusters=8, init='random', algorithm='full', random_state=123, n_init=1).fit_predict(vectors)
FrovedisServer.shut_down()
fig, ax = plt.subplots(figsize=(30, 30))
cmap = plt.get_cmap('Dark2')
for i in range(f_est.shape[0]):
cval = cmap(clustered[i] / 4)
ax.scatter(f_est[i][0], f_est[i][1], marker='.', color=cval)
ax.annotate(cluster_labels[i], xy=(f_est[i][0], f_est[i][1]), color=cval, fontsize=18)
plt.plot()
Out[8]:
[]

Frovedis DBSCANによるクラスタリング¶
In [9]:
from frovedis.mllib.cluster import DBSCAN as frovDB
FrovedisServer.initialize("mpirun -np 2 {}".format(os.environ['FROVEDIS_SERVER']))
t1 = time.time()
f_est = frovDB(eps=1.5, metric="euclidean", min_samples=5, algorithm="brute").fit(vectors)
t2 = time.time()
print("Frovedis DBSCAN train time: {:.3f} sec".format(t2-t1))
u, counts = np.unique(np.array(f_est.labels_), return_counts=True)
print("labels_ \n",u)
print("counts_ \n",counts)
cluster_labels = f_est.labels_
cluster_to_words = defaultdict(list)
for cluster_id, word in zip(cluster_labels, vocab):
cluster_to_words[cluster_id].append(word)
for i in range(len(cluster_to_words.values())):
print(list(cluster_to_words.keys())[i], list(cluster_to_words.values())[i][:25])
print("----------------------------------")
FrovedisServer.shut_down()
Frovedis DBSCAN train time: 0.204 sec labels_ [-1 0 1 2 3 4 5 6 7] counts_ [11852 5 8195 12 6 8 8 3 3] -1 ['u.s.', 'year', 'market', 'trade', 'china', 'company', 'bank', 'rise', 'fed', 'last', 'week', 'economy', 'stock', 'covid-19', 'investor', 'price', 'economic', 'new', 'expect', 'share', 'report', 'global', 'growth', 'point', 'data'] ---------------------------------- 2 ['month', 'march', 'april', 'june', 'july', 'december', 'january', 'september', 'february', 'october', 'august', 'november'] ---------------------------------- 0 ['wednesday', 'thursday', 'monday', 'tuesday', 'friday'] ---------------------------------- 1 ['get', 'think', 'well', 'need', 'look', 'start', 'many', 'result', 'way', 'begin', 'mean', 'potential', 'worry', 'suggest', 'thing', 'believe', 'happen', 'possible', 'appear', 'seem', 'come', 'reason', 'probably', 'particularly', 'something'] ---------------------------------- 3 ['tdk', 'komatsu', 'keyence', 'sumco', 'yuden', 'taiyo'] ---------------------------------- 4 ['26-week', '13-week', '4-week', '8-week', '119-day', '42-day', '154-day', '105-day'] ---------------------------------- 5 ['razaqzada', 'fawad', 'forex.com', 'otunuga', 'rhona', 'briesemann', 'lukman', 'oconnell'] ---------------------------------- 6 ['btc', 'eth', 'utc'] ---------------------------------- 7 ['wakatabe', 'noguchi', 'masazumi'] ----------------------------------
scikit-learn DBSCANによるクラスタリング¶
In [10]:
from sklearn.cluster import DBSCAN as skDB
t1 = time.time()
s_est = skDB(eps=1.5, metric="euclidean", min_samples=5, algorithm="brute").fit(vectors)
t2 = time.time()
print("scikit-learn DBSCAN train time: {:.3f} sec".format(t2-t1))
u, counts = np.unique(np.array(s_est.labels_), return_counts=True)
print("labels_ \n",u)
print("counts_ \n",counts)
cluster_labels = s_est.labels_
cluster_to_words = defaultdict(list)
for cluster_id, word in zip(cluster_labels, vocab):
cluster_to_words[cluster_id].append(word)
for i in range(len(cluster_to_words.values())):
print(list(cluster_to_words.keys())[i], list(cluster_to_words.values())[i][:25])
print("----------------------------------")
scikit-learn DBSCAN train time: 5.830 sec labels_ [-1 0 1 2 3 4 5 6 7] counts_ [11852 5 8195 12 6 8 8 3 3] -1 ['u.s.', 'year', 'market', 'trade', 'china', 'company', 'bank', 'rise', 'fed', 'last', 'week', 'economy', 'stock', 'covid-19', 'investor', 'price', 'economic', 'new', 'expect', 'share', 'report', 'global', 'growth', 'point', 'data'] ---------------------------------- 2 ['month', 'march', 'april', 'june', 'july', 'december', 'january', 'september', 'february', 'october', 'august', 'november'] ---------------------------------- 0 ['wednesday', 'thursday', 'monday', 'tuesday', 'friday'] ---------------------------------- 1 ['get', 'think', 'well', 'need', 'look', 'start', 'many', 'result', 'way', 'begin', 'mean', 'potential', 'worry', 'suggest', 'thing', 'believe', 'happen', 'possible', 'appear', 'seem', 'come', 'reason', 'probably', 'particularly', 'something'] ---------------------------------- 3 ['tdk', 'komatsu', 'keyence', 'sumco', 'yuden', 'taiyo'] ---------------------------------- 4 ['26-week', '13-week', '4-week', '8-week', '119-day', '42-day', '154-day', '105-day'] ---------------------------------- 5 ['razaqzada', 'fawad', 'forex.com', 'otunuga', 'rhona', 'briesemann', 'lukman', 'oconnell'] ---------------------------------- 6 ['btc', 'eth', 'utc'] ---------------------------------- 7 ['wakatabe', 'noguchi', 'masazumi'] ----------------------------------
In [ ]:
k-meansでグループ分けされた単語群は、世界経済、貿易、金融市場、企業情報など、関連性がありそうな8つのまとまりになっていることが分かります。一方、DBSCANでは、どの記事にも含まれていそうな単語グループが大きく二つ作られています。クラスタリングアルゴリズムはデータ分布形状によってそのグループへの分けられ方が大きく変化することが分かります。
以下のテーブルに各学習に要した時間比較をまとめました。特にt-SNEにおいて学習時間に大きな差が生じています。更には、Frovedisではmethod="exact"を指定することで、より正確な計算を行っているのに対して(計算量が増えて時間がかかる)、scikit-learnは近似により計算量を減らすmethod='barnes_hut'を使っています。今回のデータセットサイズでは、scikit-learnで近似計算を選択しなければおよそ5時間要しましたが、これでは実用的といいがたいでしょう。
| 学習アルゴリズム | Frovedis (秒) | scikit-learn(秒) | Frovedisでの高速化 |
|---|---|---|---|
| t-SNE | 18.73 | 198.75 | 10.6倍 |
| k-means | 0.08 | 0.68 | 8.5倍 |
| DBSCAN | 0.20 | 5.83 | 29.2倍 |
繰り返しになりますが、データセットの分布形状に対してクラスタリングアルゴリズムには向き不向きがあります。どのアルゴリズムが分析対象に向いているか複数のパラメータを組み合わせての学習を繰り返すことは多くの場合、時間を要するものです。SX-Aurora TSUBASAとFrovedisを利用することで機械学習においてこうした負担を削減できます。
 AL/ML開発向けオープンソースプラットフォーム「Frovedis」
AL/ML開発向けオープンソースプラットフォーム「Frovedis」