Japan
サイト内の現在位置
ベクトルプロセッサ専用コンパイラオプション(その2)
no.0082021.2.262. インライン展開機能制御オプション
自動ベクトル化の制約として、関数呼び出しを含むループはベクトル化できないことがあります。その対応策に、自動インライン展開機能を利用してベクトル化を促進する方法があります。自動インライン展開では、関数から呼び出されている関数の定義をコンパイラがサーチした後、インライン展開できる関数をコンパイラが選び出し、関数を呼出す代わりに呼び出されている関数内部の命令列をループの中に展開します。
これにより、ループは関数呼び出しを含まない状態となり自動ベクトル化が適用できるようになります。
なお、展開される関数の中にさらに関数呼び出しが存在するようなコードでは、サーチする関数の深さを指定することでインライン展開を促進します。深さを指定しなければ、深さとして2が指定されたものみなされます。
インライン展開のサンプルとして、NLCPyの回で使った積分プログラムをCに書き換えて、-O2最適化レベルでコンパイルしました。Figure-7にソースコード、Figure-8にコンパイルリストを示します。-O2レベル、そしてインライン展開のためのオプションとして-finline-functionsをつけてコンパイルしています(Figure-9)。
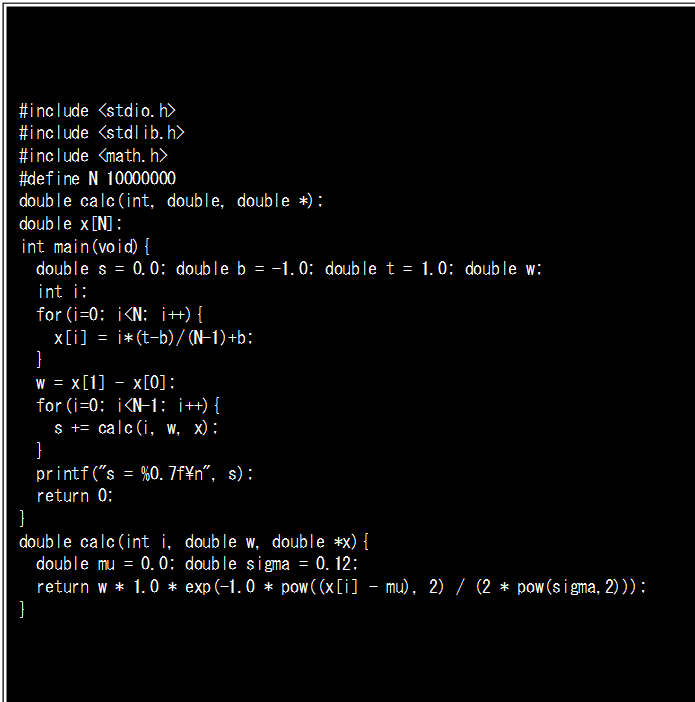
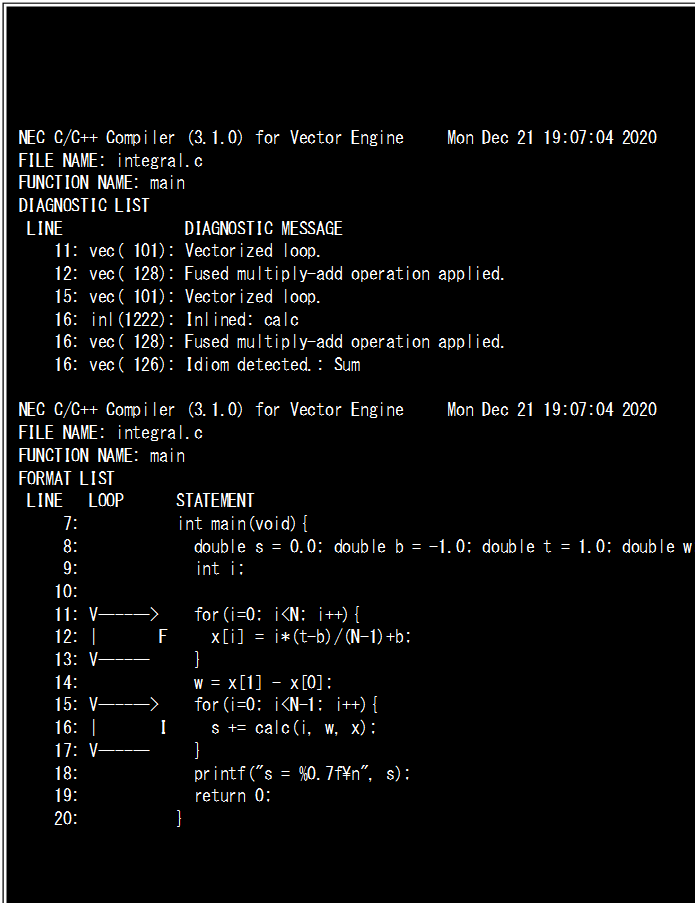

Figre-8のコンパイルリストはcalc関数がループ内部にインライン展開されたことを表示するmain()に関わる部分を抜粋しました。リストでは15行目から始まるループがベクトル化されたことを示す‘V’、さらに16行目のcalc関数呼び出しの先頭に関数呼び出しがインライン展開されたことを示す’I’が表示されています。
このように、コンパイラが自動的に判断し、ループ内で呼び出される関数をループ内に展開することにより、呼び出す側のループ内部の処理がベクトル化されます。このサンプルコードでは、インライン展開されたプログラムの実行時間が0.01秒に対して無展開では28秒要しており、その差は歴然としています。
3. 並列化オプション
演算処理高速化の方法として、最適化・ベクトル化処理に加えて複数のスレッドを生成して並列処理させるプログラムの並列化があげられます。これはループや演算処理の集まりを抽出し、並列処理ができるようにプログラムを変形するものですが、SX-Aurora TSUBASAのコンパイラには自動並列化オプションとOpenMPオプションを使う2つの方法が用意されています。
自動並列化オプションでは-mparallelを、OpenMPオプションでは-fopenmpをコンパイル時に指定します。自動並列化オプションやOpenMPオプションを選択する際にはコンパイルだけでなくリンクの際も-mparallel、または、-fopenmpをパラメータとして指定します。
OpenMPでは、並列処理ができる(並列化阻害要因のない)ループを探し出してfor文を並列化、並列処理ができるようにOpenMPの指示行を挿入する、といったプログラムの編集作業を人間の判断で行います。プログラム中の並列処理できる部分をたくさん探し出せれば、より大きな並列化効果が得られます。
一方、自動並列化機能を選ぶと、並列処理できる部分を探し出す、または、並列処理できるようプログラムを改変する作業をコンパイラが自動で行ってくれます。細かな並列化チューニングという点ではOpenMPを選択して人間の判断でソースコードを編集する方が高い効果が期待できますが、そのようなプログラミングに要する作業時間を抑えて並列化の効果を得たいといった状況では自動並列化機能が力を発揮します。
自動並列化機能(-mparallel)、OpenMP(-fopenmp)の2つのオプションを同時に指定する使い方もあります。この場合、OpenMP並列リージョン内のループはOpenMP並列化の対象に、それ以外の場所は自動並列化が対処することになります。
なお、並列処理に使用するスレッド数はベクトルプロセッサの最大コア数である10(Aurora 20A以外のモデルでは8)までの範囲で選ぶことができ、export OMP_NUM_THREADS=10という具合に、ソースコードのコンパイル後に環境変数にコア数より小さい範囲の数でスレッド数を指定します。この環境変数は、自動並列化機能利用時のスレッド数を指定するためにも使用します。
並列化処理において、並列リージョン内で巨大な配列の宣言や、PRIVATE句で巨大な配列を指定する場合、既定のサイズ(4メガバイト)より大きなスタック領域が必要となります。そのような場合、export OMP_STACKSIZE=1Gのようにスタックサイズを指定しスレッドごとのスタック領域を拡張します。スタックサイズの単位はK(キロバイト)、M(メガバイト)、G(ギガバイト)の何れかを選択できます。この環境変数は、自動並列化機能利用時のスタックサイズを指定するためにも使用します。
4. 性能測定オプション
ここまで、ベクトルプロセッサ専用コンパイラのコンパイラオプションの中からベクトル最適化レベルの選択、インライン展開、並列化実行のためのパラメータ設定について見てきました。次に、ベクトル演算による性能確認や処理に時間を要している箇所を特定するために用意されているPROGINFやFTRACEといったツールを起動させるための方法をご紹介します。
PROGINFやFTRACEで表示される項目や機能について今回踏み込んだ説明は行いませんが、概略的にはPROGINFがプログラム全体の性能情報を把握するものであるのに対して、FTRACEはプログラム内の各関数別に性能情報を表示するものです。思うような処理速度が得られないとき、原因を探るためにどの関数処理で時間がかかっているのか、またベクトル演算率が低い関数を検知するためにFTRACEは使用されます。ベクトル化率が低い関数内のコードを見直し、ループ長をできるだけ長くなるように修正することで性能を上げるといった使い方になります。
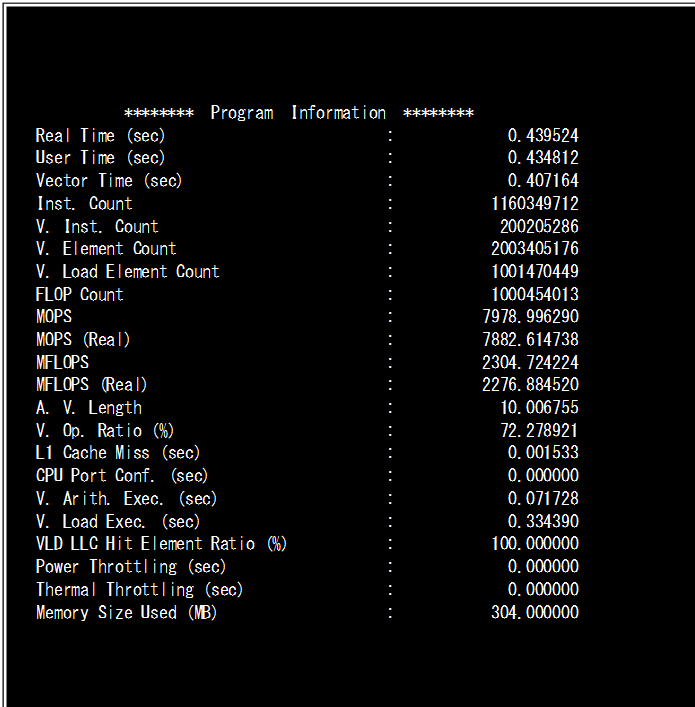
PROGINFにおける性能情報を表示させるには、プログラムを実行する前に環境変数export VE_PROGINF=YES、または、export VE_PROGINF=DETAILを指定します。YESの場合には実行プログラムの時間情報、命令実行回数情報、そしてベクトル化情報といった基本的な情報を、またDETAILの場合には基本情報に加えてベクトルプロセッサカードのメモリ情報を併せて表示します。なお、PROGINFの性能情報を見るためにはコンパイル、リンク時に特別なオプションを指定する必要はありません。Figure-10はPROGINF表示の一例です。
一方のFTRACEではコンパイル、リンクの際に-ftraceオプションをつけて実行ファイルを作成します。実行ファイルの処理が完了するとftrace.outという名称で性能情報が記録されたファイルが自動的に作成されます。ftrace.outに保存された性能情報を見るためにはftraceコマンドを実行します。
複数のソースコードにプログラムが分割されているようなケースでは、FTRACEによる性能情報表示を一部のソースコード内に含まれる関数に限定できます。
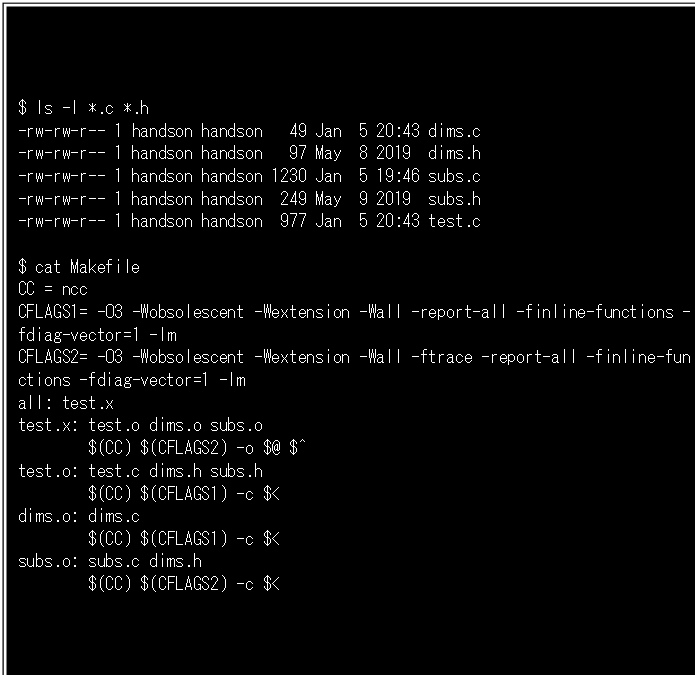
ここにdims.c、dims.h、subs.c、subs.h、test.cという3つのCソースファイルと2つのヘッダファイルで構成されるサンプルプログラムがあります(Figure-11)。そしてsubs.cに含まれる関数だけFTRACEによる性能情報を見たい場合、subc.cとdims.hをコンパイルするときにだけ-ftraceオプションをつけオブジェクトファイルを作成します(Figure-11のMakefile内でftraceオプションを指定したCFLAGS2でコンパイルしています)。
次に、残るdims.c、dims.h、subs.h、test.cにおいてもそれぞれオブジェクトファイルを生成します。そして最後に再びCFLAGS2(ftraceオプション指定つき)でこれら3つのオブジェクトファイルをリンクして実行ファイルにします。実行ファイルの処理終了後、ftrace.outというファイルが作られますので、ftraceコマンドを実行することで、ソースファイルsubs.c内の関数sub1、initについてのみ、性能情報を参照できます(Figure-12)。
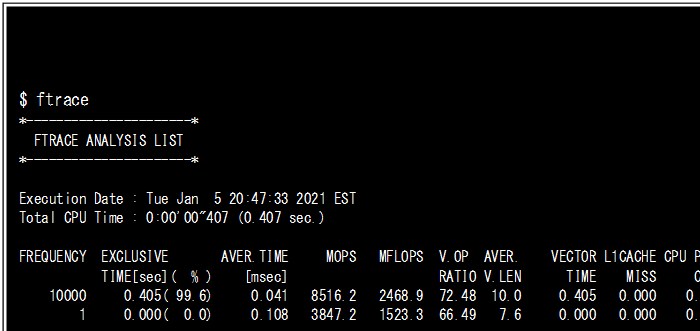
FTRACEは各関数の入り口と出口で性能情報を取得する仕組みをとっています。このため関数呼び出しが多いプログラムでは性能情報処理によってプログラムの実行時間が長くなる可能性があります。これを避けるため性能分析の対象となる関数が含まれるソースコードのオブジェクトファイル作成時にだけ-ftraceを指定し性能測定箇所を限定的にして実行時間の不要な増加を抑えます。
5. デバッグオプション
最後に、プログラムのデバッグする際に利用できるデバッガとトレースバック機能を使うためのオプション設定について見ていきます。
Linux環境で動く標準のデバッガとしてGDBが存在します。SX-Aurora TSUBASAのベクトルプロセッサで実行されるプログラムをデバッグするためにも、このGDBを利用できます。
NECはGDBをSX-Aurora TSUBASA専用として移植しました。GDBでは、ソース行や関数のシンボルを指定してブレークポイントを設定することや、VEプログラムをステップ実行すること、シンボルを指定した変数の表示やスカラレジスタやベクトルレジスタを表示すること、変数やレジスタの値を変更することができます。
なお、GNU版GDBとの相違点については、GDB相違点に相違点概要やSX-Aurora TSUBASA専用GDBに固有なコマンド等について説明があります。詳細について知りたい場合はそちらをご覧ください。
GDBでデバッグするためには、先のFTRACEで実施したことと同様にデバッグしたい部分のソースコードでオブジェクトファイルを生成する際に-gオプションを指定します。その他のソースコードをコンパイルする際は-gをつけません。
また、デバッグ対象のソースコードをコンパイルする際に-gと共に-O0オプションを指定して最適化やベクトル化ができるだけ行われないようにすることをお勧めします。これはコンパイラによる最適化、ベクトル化が行われると、コードや変数の削除や移動などの最適化が適用され、GDBで変数が参照できない、ブレークポイントが設定されないといった事態を避けるためです。
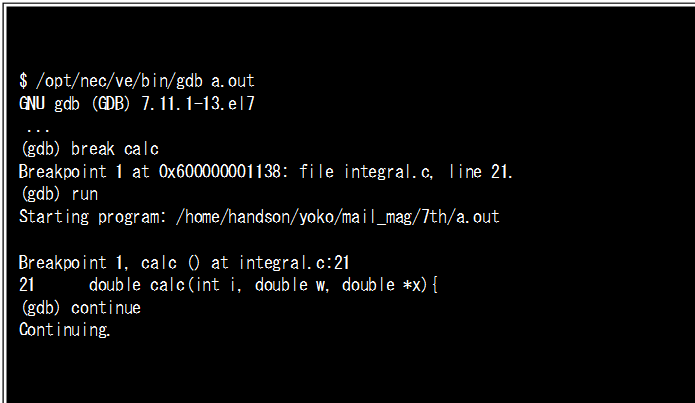
Figure-13はインライン展開のところで使ったサンプルコードintegral.cを-O0でコンパイル後、GDBで実行した様子です。関数calcにブレークポイントを設定してプログラムを実行させています。
トレースバック機能を使うと問題発生個所の特定が容易になります。そのためにはコンパイル、リンク時に-traceback=verboseオプションを指定し、また、実行する前にexport VE_TRACEBACK=VERBOSEと指定します。プログラム実行後にソースコードの中の例が処理発生個所を特定できます。
注意点として、ベクトルプロセッサによる命令の先行制御の影響で例外発生個所が正しく表示されないことがあります。この場合には、export VE_ADVANCEOFF=YESと指定することで先行制御が働かないよう指示を出します。
ただし、この先行制御をオフにすることはプログラムの実行に時間がかかるようになるという副作用があることは心に留めておくべき点です。
プログラムが大規模なものとなり、分割したソースファイルが大量になってくると、コンパイルやリンクに要する時間は長くなってしまいます。また、どの処理や関数で性能が出ていないのか、また、例外処理などによる正しくない計算がどこで起きているかといったバグを見つける作業は容易ではなくなっていきます。
必要なコンパイラオプションを適切に使うことで、大規模な開発においてできるだけ負荷を減らしてください。
以上、駆け足でコンパイラの最適化・ベクトル化やインライン展開・並列化、そして性能モニターやデバッグ機能を使うためのオプションを見てきました。最後に付け加えさせていただくと、SX-Aurora TSUBASAにおけるプログラム開発はホストサーバーのRedHatやCentOS上で行うため、makeだけでなくcvs、git、svnなどLinuxのプログラム開発支援する道具を使ったソースコードの管理が可能です。
また、Makefileの中にncc、nc++だけでなくgccを合わせて指定して、ホストサーバーで動作するアプリケーションからSX-Aurora TSUBASAに特定処理のオフロードをさせるようなシステムを一回のmake実行で作成することも容易です。SX-Aurora TSUBASAのコンパイラオプションを正しく使い、ベクトルプロセッサの性能を活かしたプログラム開発に役立ててください。
関連リンク
 Aurora Forum Web Documentation
Aurora Forum Web Documentation
Table 3: NEC SDK > C/C++コンパイラユーザーズガイド 参照