Japan
サイト内の現在位置
NumPy互換数値演算ライブラリNLCPy
no.005 ~SX-Aurora TSUBASA向けPythonライブラリ~(その1)2020.11.30 Pythonでは、スカラーやベクトル、マトリクス形式のデータの数値計算を高速化することを目的としてNumPyが広く利用されています。NumPyの利用例や、またその使用方法についてはhttps://numpy.org/に詳細が紹介されています。”Numerical Python”を意味するといわれるNumPy、Pythonを使った機械学習、データサイエンス、 科学技術計算など幅広い分野でデファクトスタンダードな計算ライブラリです。
NumPyの特徴はなんといってもndarrayと呼ばれるn-次元配列をサポートしている点です。Pythonビルトインの”List”データタイプとは異なり、ndarrayの配列には単一形式(整数型、浮動小数点型など)のデータ要素が納められます。ndarrayに対してはループ処理を用いず一括で配列全体に高速な計算処理を行うことができます。そして、この計算処理に利用できる数学関数が用意されています。
今回ご紹介するNLCPyは、このNumPyを使ったスクリプトをSX-Aurora TSUBASAのベクトルエンジンを使ってさらに高速化するためにNECが開発しているPython向けのライブラリです。
NLCPyが登場するまで、SX-Aurora TSUBASAで何か仕事をさせるためには、計算処理のC/C++あるいはFortranコードを書いてコンパイル、そこにライブラリをリンクして、という手順を踏むことがごく自然な流れでした。
プログラミング言語の人気ランキング「TIOBEインデックス」によると、最新のランキング結果でもC/C++といったプログラミング言語は今も人気上位を占めています。しかし、Pythonはインタラクティブな操作が可能なことと、非常に豊富な機能追加モジュールを使った幅広い用途に向けたプログラミングが可能なことからC/C++に劣らず高い人気を保っており、Python Success Storiesにあるように多くのアプリケーション向けに使用されていることが分かります。
PythonとNumPyによる利用例の中で最近では、初めてブラックホールをイメージ化したTHE FIRST IMAGE OF A BLACK HOLEが有名ではないでしょうか。BBCの記事はこちらから。
今回紹介するNLCPyの登場によって、SX-Aurora TSUBASAをPythonベースでの数値計算のプラットフォームとしても利用できるようになりました。SDKでサポートされるコンパイル型言語による開発とは異なり、PythonにおいてNLCPyをインストールすると、極端に言うと電卓を使うような感覚でインタラクティブな操作でSX-Aurora TSUBASAを使うこともできます。かつてスーパーコンピュータと呼ばれていたベクトルエンジンを電卓感覚でも使える。なんとも感慨深いことです。
それではいくつかのサンプルプログラムを使いながら、NLCPyの使い方と高速性、Pythonの他モジュールとの連携等について見ていきましょう。
先に少し触れたように、NumPyではndarrayを用いて数値計算処理を高速に実行することができます。
ndarrayとはn次元配列オブジェクト(n-dimensional array)を意味しますが、ndarrayに対する数値計算処理はその配列要素全てに対し一括で実行され、処理が高速化されます。C/C++あるいはFortranといった言語では、配列データに対し何らかの数値計算処理をする際、forもしくはwhileループを使って配列内のデータを順番に参照しながら処理を行うコードを書くことが一般的です。
一方NumPyでは、ndarrayによる配列志向プログラミングのスタイルをとることで、ループ処理コードによる演算に比較して高速に処理を行います。この配列志向のことをオライリーの本の中ではベクトル演算と呼んでいますが、SX-Aurora TSUBASAのベクトルエンジンによるベクトル演算と全く同じことを指しているわけではありません。しかし、配列内のデータを一括して数値処理するという点は共通項と言えます。
では、ループ処理により数値演算処理を行った時と、配列志向(ユニバーサル関数を使い全ての配列要素への関数適用)のによる処理で、どれほど処理時間に差が現れるのか確認してみましょう。使用するサンプルコードはガウス分布を積分処理するものです。
ループを使ったコード(naive_gauss.py)では横軸方向で分割した各区間の長さxと縦軸方向の高さyをかけて求めた面積を足し合わせています。
一方、NumPyあるいはNLCPyのユニバーサル関数を使ったコード(NumPy_gauss.pyもしくはNLCPy_gauss.py)では各区間の長さをyに掛け合わせ、sumをとり一気に面積を求めています。以下に3つのサンプルコードを示します。
最初のコード(Figure-1)はNumPyもNLCPyも使わず標準のPythonがもつ機能でループ処理を行っています。次に示すコード(Figure-2)はNumpyのユニバーサル関数を使って処理しており、3番目のコード(Figure-3)ではNumPyに代わってNLCPyのユニバーサル関数で計算処理を行っています。
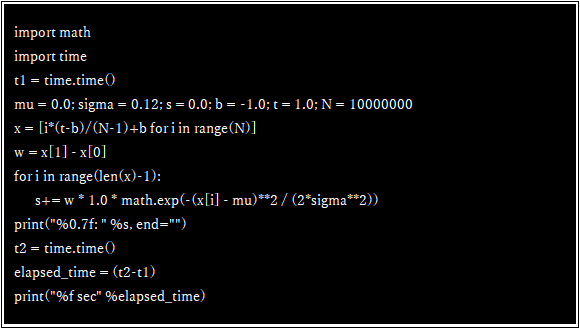

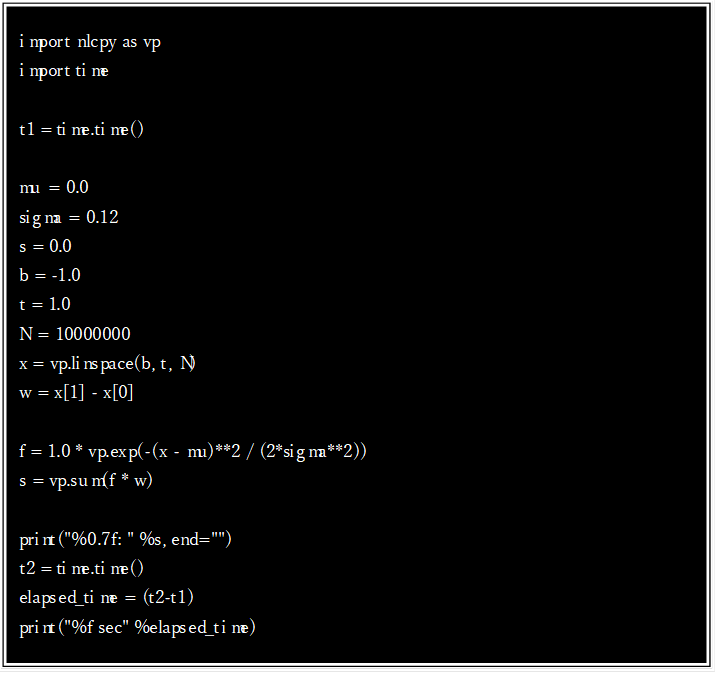
それぞれのコードの実行時間をFigure-4に示しました。Python標準の組み込み機能とループ処理では実行に7.3秒要するのに比べ、NumPyのユニバーサル関数とブロードキャストを使うと0.3秒に短縮されています。さらにNumPyの代わりにNLCPyを使うことで、同じ処理が0.01秒となります。
このように、Python標準組み込み機能とループ処理の代わりにNumPyを使用することで高速処理できること、NumPyの代わりにNLCPyを使うことで数値処理時間をさらに大きく短縮できることがお分かりいただけたかと思います。

次に、NumPy とNLCPyでのndarrayの相互転送変換について説明します。ここでの相互転送とはNumPyで作成したndarrayをNLCPyのndarrayへコピー、またその反対の操作を行うことを指します。
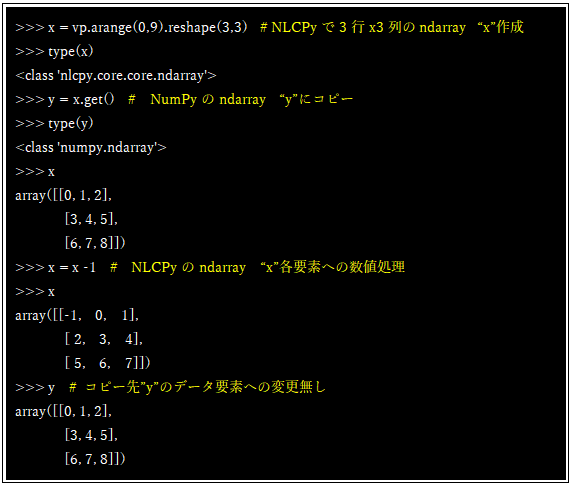
まず、NLCPyにおいて3行x3列のndarray “x”を作成します。次にこの”x”をget()関数を使用してNumPyのndarray “y”に変換します。この時、ndarrayのデータはベクトルエンジン(以降VE)のメモリからベクトルホスト(以降VH)のメモリに転送されNumPyのndarray “y”というコピーが作成されます。そのためndarray “x”に対して行う数値処理はコピー先であるNumPyのndarray “y”には反映されません。こうした操作をFigure-5に示しました。
反対に、NumPyのndarrayに入ったデータをNLCPyのndarrayにコピーするにはasarray()関数を使います。はじめにNumPyにおいて3行x3列のndarray ‘x’を作成します。次にこの’x’をasarray()関数を使いNLCPyのndarray ‘y’へコピーします。この際、ndarrayのデータはVHのメモリからVEのメモリに転送されNLCPyのndarray ‘y’というコピーが作成されます。これら一連の操作はFigure-6に示した通りです。

ndarray相互転送の説明に続いて、NumPyとNLCPyそれぞれのndarrayの間で算術演算した場合のデータ移行について見ていきましょう。
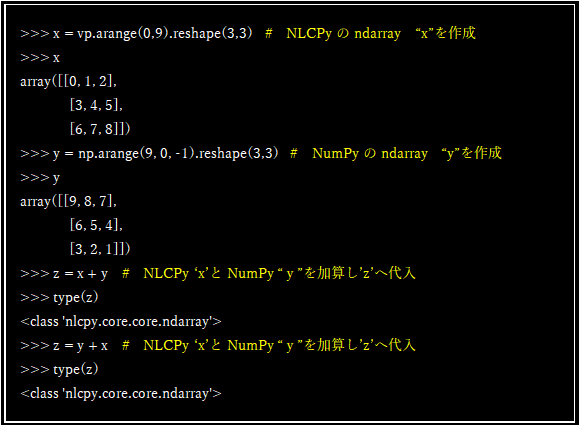
まず、NLCPyとNumPyそれぞれでndarrayの配列データを用意します。次に、NLCPyのndarray ‘x’とNumPyのndarray ‘y’を算術演算し、その結果を’z’に代入します。’z’の属性が<class 'nlcpy.core.core.ndarray'>と示される通り、’z’はNLCPyのndarrayであることが分かります。NLCPyのndarrayであることから、’z’ ndarrayのデータはVEのメモリに置かれていることになります。Figure-7がその操作の様子です。
この算術演算操作の裏では、NumPyのndarray y(VHのメモリに確保されています)のデータがVEのメモリにコピーされた後に、NLCPyのndarray ‘x’に対し加算され、結果がNLCPyのndarrayに引き渡される、という処理が行われています。NumPyとNLCPyのndarrayの間で算術演算を行う際には、VH-VE間でデータ転送が発生することから、大なり小なり転送のコストが発生することへの注意が必要です。
NLCPyとNumPyのndarray同士の算術演算に続いて、NumPy、NLCPyそれぞれが持つユニバーサル関数を使ってNumPyとNLCPyのndarray同士を演算する流れを見ましょう。
NumPyのユニバーサル関数addを使ってNLCPyとNumPyのndarray同士を演算した結果はNumPyのndarray(VHのメモリに保存)に格納されます。反対にNLCPyのユニバーサル関数addを使ってNLCPyとNumPyのndarray同士を演算した結果はNLCPy(VEのメモリに保存)のndarrayになります。これら操作をFigure-8に示します。

 Aurora Forum Web Documentation
Aurora Forum Web Documentation