Japan
サイト内の現在位置
ディレクトリスキャンツール「feroxbuster」のご紹介
NECセキュリティブログ2022年5月13日
FFUFの使用で直面した問題
Hack The BoxのFlusteredというRetiredマシンを解いていた際に問題を感じました。本マシンでは、接続時に認証が必要なプロキシサーバ経由でないとアクセスできないWebページが存在しました。そのWebページに対しディレクトリスキャンを実施しようとした際の出来事です。
FFUFやgobuster  [3]で、認証情報をURLに埋め込んだProxyを指定(http[:]//(ID):(PASSWORD)@IPアドレス)すると、ProxyのURLフォーマットエラーが発生して利用できないことがわかりました。回避策としてBurpのUpstream Proxy Serversに認証サーバを設定するなどすることで、FFUFからのスキャンも可能です。しかし、Burp経由のスキャンを実施するとスキャン時間を要するため、別のツールを探していました。
[3]で、認証情報をURLに埋め込んだProxyを指定(http[:]//(ID):(PASSWORD)@IPアドレス)すると、ProxyのURLフォーマットエラーが発生して利用できないことがわかりました。回避策としてBurpのUpstream Proxy Serversに認証サーバを設定するなどすることで、FFUFからのスキャンも可能です。しかし、Burp経由のスキャンを実施するとスキャン時間を要するため、別のツールを探していました。
ツールの調査をしていく中で、feroxbusterにたどり着きました。feroxbusterであれば、認証情報付きのサーバに対してもスキャンが可能でした。
改めて確認して、後から気づきましたが、FFUFを実行する際に” Proxy-Authorization: Basic (Base64でエンコードした認証情報)”をHeaderに付与することでスキャン可能であることを確認しました。
FFUFとferoxbusterの違い
FFUFとferoxbusterの違いを確認してみます。大きな違いとしては、FFUFはディレクトリスキャンだけではなく、様々なパラメータに対してファジングが可能です。一方で、feroxbusterはディレクトリスキャンに特化しており、そのスキャン機能がFFUFよりも強力です。以下に簡単な比較表を作成しました。
| 機能 | feroxbuster | FFUF |
| ディレクトリスキャン | 〇 | 〇 |
| 再帰的ディレクトリスキャン | 〇 | 〇 |
| GETパラメータのファジング | × | 〇 |
| HTTPメソッドのファジング | × | 〇 |
| HOSTヘッダーのファジング | × | 〇 |
| POSTデータのファジング | × | 〇 |
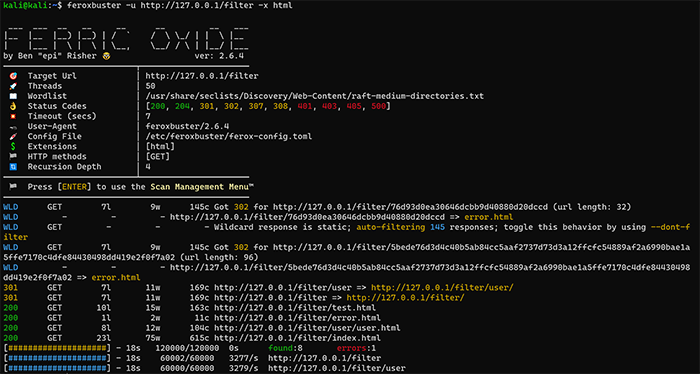
| Directory-Listing検知機能 | 〇 | × |
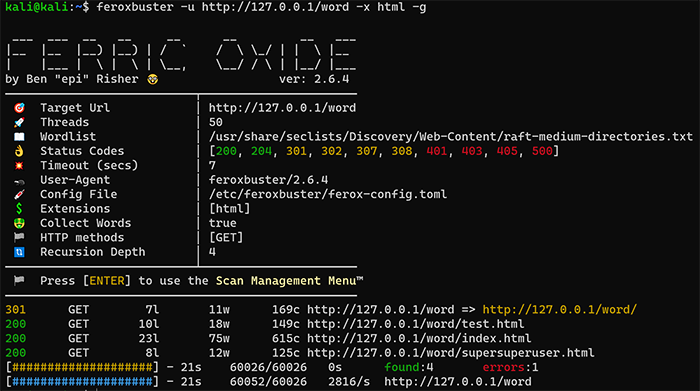
| ページ内リンク収集機能 | 〇 | × |
| 自動フィルター条件追加機能 | 〇 | × |
| ページ内ワード収集機能 | 〇 | × |
| Proxy経由のスキャン | 〇 | 〇 |
| Basic認証のURL埋め込み | 〇 | × |
| Proxyへの再送 | 〇 | 〇 |
| 出力ファイル形式(json) | 〇 | 〇 |
| 出力ファイル形式(json以外) | × | 〇 |
| 検査結果のマッチ条件(HTTP Status) | 〇 | 〇 |
| 検査結果のマッチ条件(HTTP Status以外) | × | 〇 |
| 検査結果の除外条件 | 〇 | 〇 |
| ワードリストのコメントアウト無効化 | 〇 | 〇 |
| 拡張子自動追加機能 | 〇 | × |
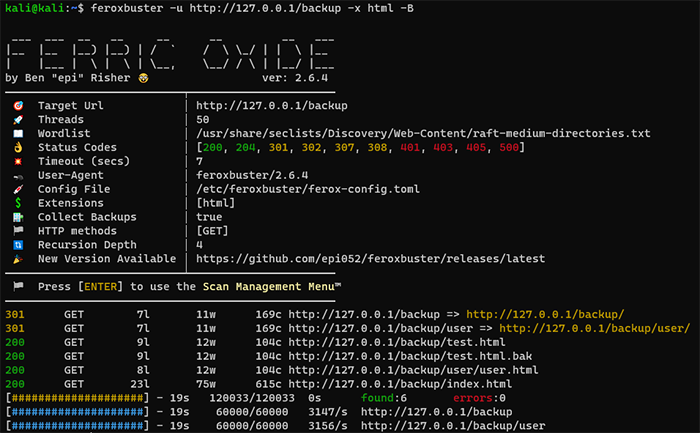
| バックアップファイル探索機能 | 〇 | × |
| 実行画面の見やすさ | 〇 | △ |
feroxbusterの特徴は、「Directory-Listing検知機能」と「ページ内リンク収集機能」、「自動フィルター条件追加機能」、「ページ内ワード収集機能」、「拡張子自動追加機能」、「バックアップファイル探索機能」の6点があります。また、実行中の画面に関しては、feroxbusterのほうが、進捗状況を把握しやすくなっていました。
それでは、使い方とそれぞれの特徴の紹介を行います。
feroxbusterの使い方
動作環境
- Kali Linux on WSL
- feroxbuster 2.6.4
- FFUF 1.5.0 (比較用)
- 検査対象
- nginxにて、必要な環境を整備しました。検査対象の環境は以下のようなディレクトリ構成になっています。具体的な構成の紹介は省略いたします。
|-- index.html
|-- normal (通常検査用)
| |-- index.html
| |-- test.html
| `-- user
| `-- user.html
|-- dir
| |-- index.html
| |-- test.html
| `-- user (Enable autoindex)
| `-- supersuperuser.html
|-- link
| |-- index.html
| |-- new_test_page_developer_only.html
| |-- test.html (new_test_page_developer_onlyへのリンクが記載されている)
| `-- user (Enable autoindex)
| `-- supersuperuser.html
|-- filter (500などのエラーを全てerror.htmlにリダイレクトさせる)
| |-- error.html
| |-- index.html
| |-- test.html
| `-- user
| `-- user.html
|-- word
| |-- index.html
| |-- supersuperuser.html
| `-- test.html (supersuperuserという文言が含まれている)
|-- autoadd
| |-- index.html
| |-- index.php
| |-- test.html
| `-- test.php
`-- backup
|-- index.html
|-- test.html
|-- test.html.bak
`-- user
`-- user.html
基本的な使い方
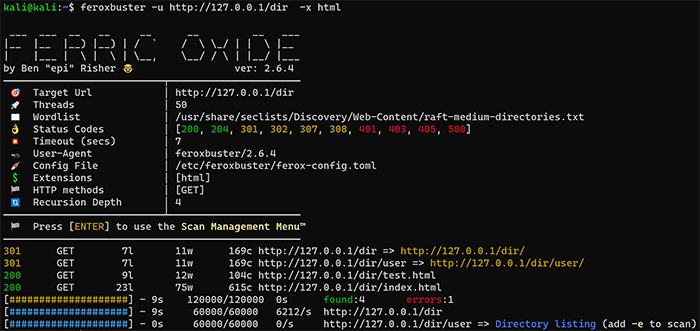
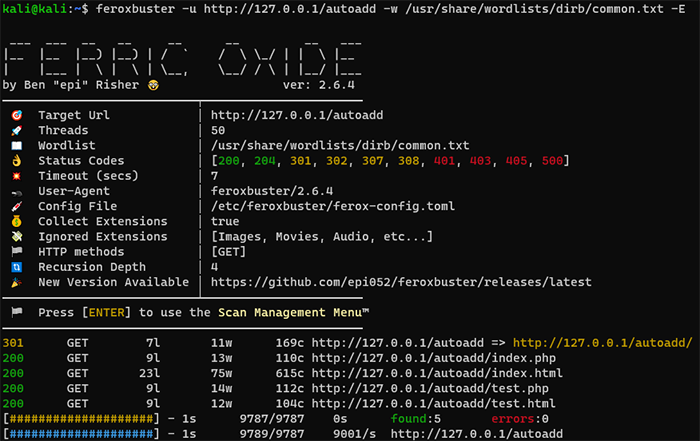
まずは、feroxbusterの動作確認を行います。ここでは、再帰オプションなしで実行し、結果の見方などを紹介します。
feroxbusterでは、デフォルトで再帰処理が有効化されています。-nを指定して実行することで再帰オプションなしでferoxbusterを実行できます。
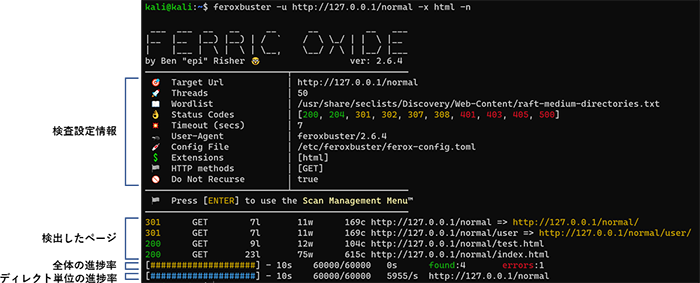
全体、およびディレクトリ単位の進捗率の表示などがあり、検査の状況が非常に見やすくなっています。また、検査結果と進捗状態の表示場所が分けられているため、結果のみの確認もしやすくなっています。
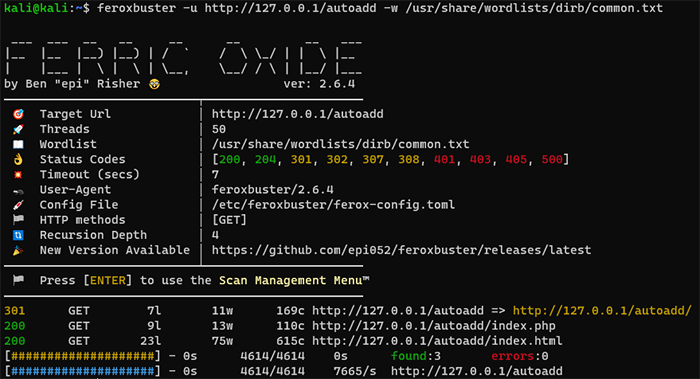
結果の確認方法を紹介いたします。まずは、全体的な項目の説明です。上記の結果を対象に説明いたします。結果の表示エリアは、「検査設定情報」と「検出したページ」、「全体の進捗率」、「ディレクトリ単位の進捗率」の4つに分かれています。ここでは、「検出したページ」と「全体の進捗率」、「ディレクトリ単位の進捗率」について説明いたします。
検出したページでは、サーバからのステータスコードや文字数、検出したURLが一覧でまとまっています。リダイレクト先があった際はそのURLも表示されます。

全体の進捗率は、黄色い#で進捗率を示し、実行終了予定時間や検出数を表示します。

ディレクトリ単位の進捗率は、青い#で進捗率を示します。本項目はディレクトリ数の増加に比例します。対象のサーバにてどれだけの数のディレクトリがあるのかを確認することができます。

feroxbusterとFFUFの実行結果画面の比較
feroxbusterとFFUFの比較を行います。今回は同じ条件で比較するため、再帰処理ありで比較をします。
まずは、feroxbusterを再帰オプションありで実行してみます。
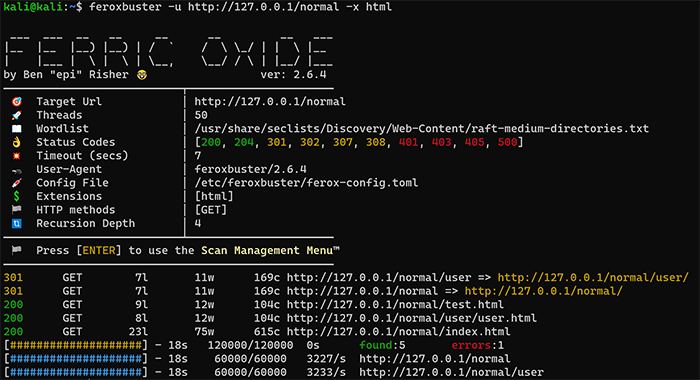
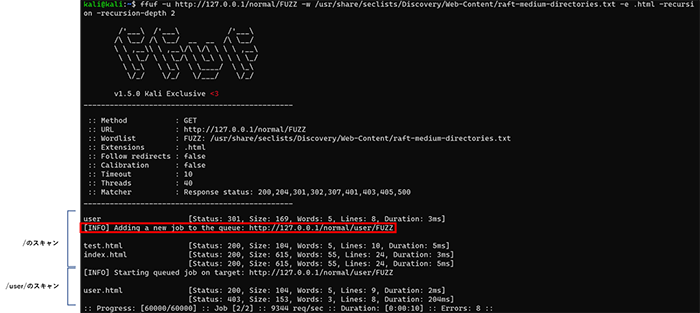
先ほどの結果とは異なり、normal/user/user.htmlまで検出できていることが確認できます。ディレクトリ単位の進捗率についても、先ほどはnormalに対してのみスキャンしていたのに対し、normal/userまでスキャンされていることが確認できます。このように再帰的にスキャンを実行しても、検出したディレクトリ情報を含んだURLリストが出力されます。そのため、検出したページを指摘事項としてまとめやすくなっています。
次にFFUFを実行してみます。