Japan
サイト内の現在位置
【音楽×AI】作曲支援!歌詞から生み出せコード進行編
2022年12月6日
はじめに
NEC AI・アナリティクス事業統括部の大澤です。2022年度に入社したばかりの新人ですが、今回データサイエンティストブログを執筆させていただくことになりました。
NEC AI・アナリティクス事業統括部では、音楽好きの若手で音楽AI部を結成し、音楽生成に関する研究を行っています。
今回の記事は、音楽AI部の研究を紹介する1本目の記事です。深層学習による歌詞を考慮したコード進行の自動生成についてお話します。
作曲ってとってもかっこよくて憧れるけれど、敷居が高くてなかなか自分にはできないと考えている人も多いのではないでしょうか。
長年の経験からしかわからない勘や、それがなければ音楽の理論を勉強しないと、思ったようにうまくは作れない…。
音楽が好きだからこそ、自分が試しに作ってみた曲が納得のできるものでなくて、悔しかったり、発表するのは恥ずかしかったりする…。
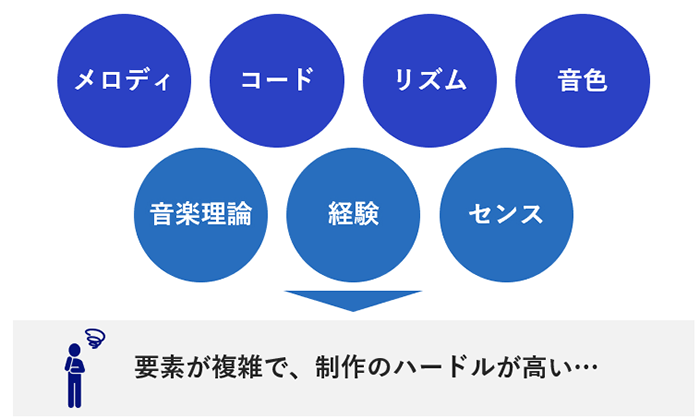
図1のように、楽曲制作は要素が複雑で、制作のハードルは高いと感じていませんか?
こんなとき、作曲の手助けをしてくれるAIと協力して曲が作れたら…!?
そんな思いから音楽AI部では、自分のオリジナルな要素も取り入れながら、楽曲制作をサポートしてくれるAIの実現を目指して活動しています!
コード進行の生成にチャレンジ
今回の研究では、楽曲の雰囲気やオリジナリティに影響する重要な要素である、コード進行に着目してみました。
コード進行とは、コード(和音)の繋がり、つまり、あるコードが時間の経過と共にどのようなコードに変化し、どう展開していくかを表すものです。
次の2つのコード進行を聞いてみてください。
前者は明るい印象、後者は少し暗い印象を受けませんか?
このように、メジャーコードやマイナーコード、その進行によって受ける印象は変わるのです!
一般的な楽曲制作として、作詞を行った後に作曲や編曲を行う手順があります。
そこで、歌詞とコード進行には密接な関係があると考え、図2のような歌詞からコード進行を生成する仕組みを検討しました。なんだか実現できそうな感じがしませんか…!?
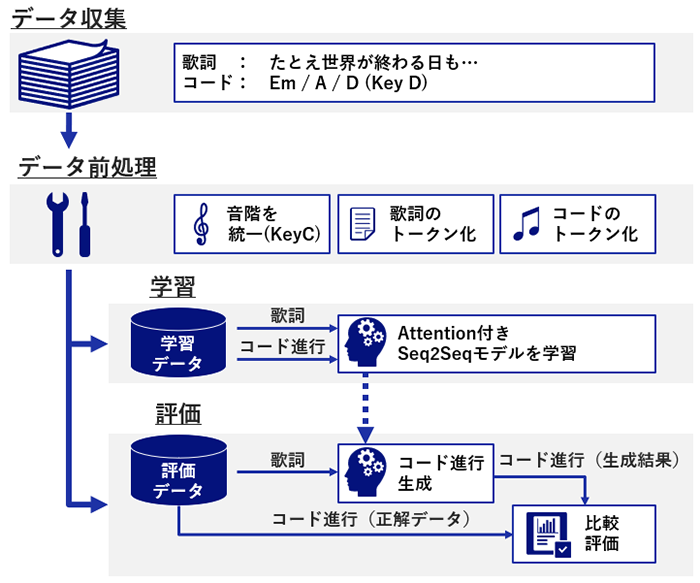
歌詞を入力してAIがコード進行を考えてくれれば、楽曲制作のハードルも随分下がるはず!
データ収集・前処理
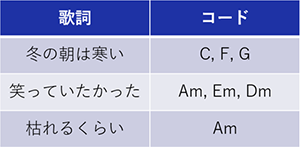
収集したデータは表1のように歌詞とコード進行がセットになっています。
表1 データセットの例
AIの学習・評価に使用するために、収集したデータのキーをCに統一(全ての曲を同じ音階に統一)するよう加工を行いました。
出現回数が少ないコードはノイズとなるため、今回は表2の14種類のコードのみが出現するデータに絞り込みを行いました。各数値はデータセット内で何回そのコードが出現したかを表しており、例えば「C, D, C」というコード進行があった場合、Cを2回カウントしています。
表2 データセットのコード出現回数

絞り込みにより約21万件のデータセットを抽出することができました。表3のように学習データと評価データを分割したところ、1データあたりの平均コード長はそれぞれ3.18, 3.09になりました。
表3 学習データ、評価データ分割結果

モデルの学習
今回のチャレンジには、Attention付きseq2seq[1]というモデルを使用しました。
seq2seq はSequence-to-sequence モデルの略称で、ある文章を受け取って別の文章に変換することができるため、翻訳タスクによく用いられています。
例えば日本語から英語に翻訳する場合だと、日本語の文章を受け取って一度「文脈」と呼ばれるベクトルに変換し、そのベクトルをもとに英語の文章に変換します。
この「文脈」というのが文字通り「伝えたい意図」だったり「表現したい事柄」だったりするわけです。
そこで今回の狙いに当てはめて考えると、歌詞に込めた思いやムードを「文脈」として読み取って、それに合ったコード進行に変換してくれそうだと期待できます…!
結果
モデルの学習ができたので、文章を入力してコード進行を生成させてみます。
Attentionの図は、コード進行生成時にモデルがどの文字列に着目したかを表現しており、数値が高いほど着目した度合いが高かったことを示します。
結果①「めちゃくちゃ嬉しい」「めちゃくちゃ悲しい」
簡単な文章を入力し、嬉しさや悲しさを表現できるか試してみました。
- めちゃくちゃ嬉しい
まずは、「めちゃくちゃ嬉しい」という文章を入力して生成したコード進行をお聞きください。生成結果は表3に、Attentionは図3に示しました。
表4 「めちゃくちゃ嬉しい」の生成結果

メジャーコードを使用したとてもシンプルで明るい印象のコード進行になりました。Attentionはどうなったでしょうか。
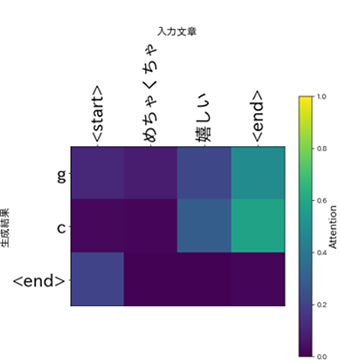
「嬉しい」という単語に影響を受けているようです。「嬉しい」=明るいコード進行という関係をうまく学習できているようですね!
- めちゃくちゃ悲しい
続いて、「めちゃくちゃ悲しい」でコード進行を生成してみましょう。生成結果は表4に、Attentionは図4に示しました。
表5 「めちゃくちゃ悲しい」の生成結果

マイナーコードを使用したシンプルで哀愁のある印象のコード進行になりました。Attentionを見てみましょう。
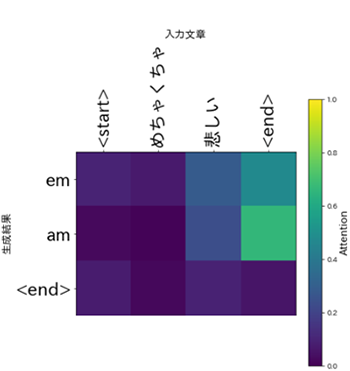
こちらも「悲しい」という単語に影響を受けて、哀愁のあるコード進行を生成したようです。
やはり歌詞とコード進行には関係があり、このモデルはデータからその関係性を学習できているようですね!
結果②「あの頃の気持ちを忘れないように」
みなさんはこの文章からどのような印象を受けるでしょうか?モデルが生成したコード進行はイメージにあっているでしょうか?
生成結果は表5に、Attentionは図5に示しました。
表6 「あの頃の気持ちを忘れないように」の生成結果

後半にセブンスコードという少し複雑な響きのコードが生成されており、物語性が感じられます。
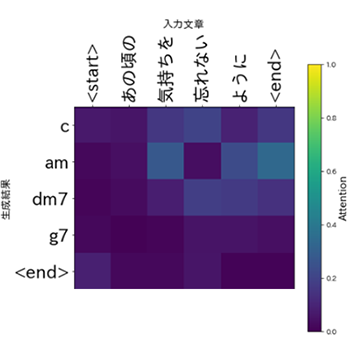
Attentionを確認すると、「気持ちを」や「忘れない」などの文字列に影響を受けているようです。「気持ちを忘れないように」という部分から、複雑な響きで物語性のあるコード進行を生成したんですね!
評価目的・手法
AIの研究では、AIを作って結果を出すだけではどのくらい良い結果だったのかよくわからないので、評価を行います。
1.定量的評価
定量的評価には再現率、編集距離を使いましたが、今回の記事では再現率のみを説明します。
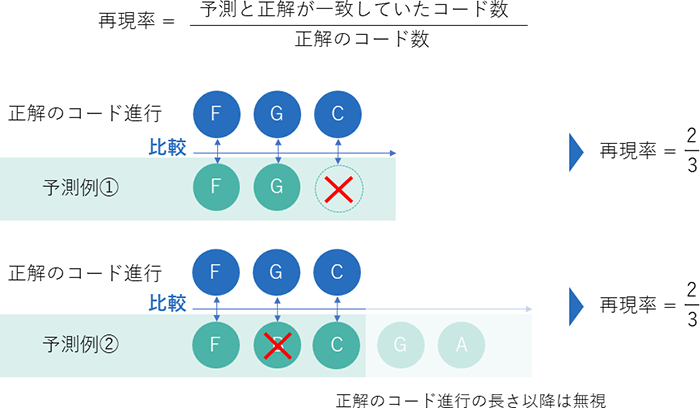
図6のように、正解となるコード進行に対し、生成されたコードのうち、一致したものの割合を再現率とします。正解のコード進行の範囲のみで評価しました。
評価には約4万件のデータを使用しました。
2.定性的評価
定性的評価を行うために、ある長い文章を用いてコード進行を生成し、30秒程度のピアノ演奏を作成しました。
289名に対して入力した文章とピアノ演奏を提示し、その文章の印象に合っているかアンケート評価を行いました。入力した文章については今回割愛しますが、ぜひ評価に使用したピアノ演奏をお聞きください。
評価結果
1.定量的評価
図7に定量的評価結果の精度推移を示します。縦軸は再現率平均を表し、横軸はepoch数を表しています。再現率平均とは、評価目的・手法の節に記載した手法を用いて、評価データ約4万件それぞれについて算出した再現率を平均した値を表しています。epoch数とは1つの学習データを何回繰り返して学習したかを表しています。
生成したコード進行のうち31.4%は正解のコード進行と完全一致し、再現率は平均0.494となりました。
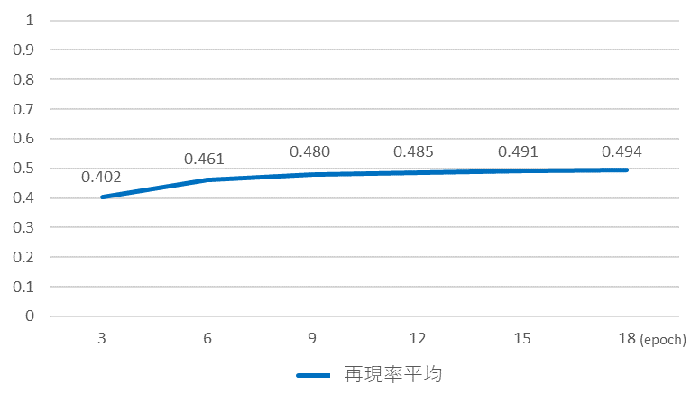
ランダムでコード進行を提示するモデルの評価結果において再現率平均は0.18となったことから、ランダムより良い精度でコード進行を生成できていることがわかりました。また、epoch数が増えるにつれて再現率平均が増加していることが確認できます。
2.定性的評価
図8に289名の被験者を対象にした定性的評価結果を示します。定性的評価では、肯定的な回答が合計 46%、否定的な回答が 8%となりました。
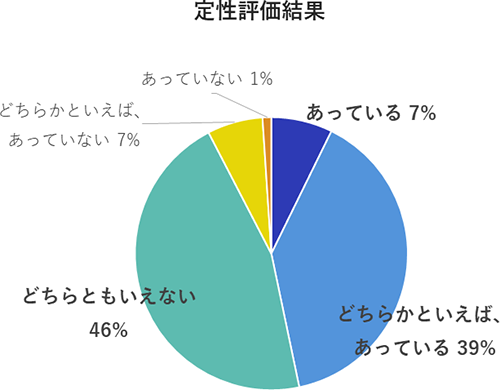
よって、今回の生成結果は人が持つ文章の印象と大きく異なってはいないことがわかりました。
おわりに
今回の記事では、深層学習による歌詞を考慮したコード進行の自動生成についてお話しましたが、いかがだったでしょうか?関連する内容を発表した論文[2]もありますので、興味のある方はご参照ください。
NEC AI・アナリティクス事業統括部では、若手の社員がチームを組み、音楽×AIなワクワクする研究を行っており、作曲支援アプリを開発する構想も練っています。
今後も、音楽AI部の研究をデータサイエンティストブログに掲載していきたいと思っておりますので、お楽しみに!
参考文献・サイト
- [1]Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio. (2014). Neural Machine Translation by Jointly Learning to Align and Translate. arXiv preprint arXiv:1409.0473
- [2]
- [3]
 深層学習による歌詞を考慮したコード進行の自動生成, 世良拓也,大井雄介,浜野祐介,谷口浩平; 深層学習による歌詞を考慮したコード進行の自動生成; 情報処理学会第84回全国大会講演論文集,pp.99-100,2022
深層学習による歌詞を考慮したコード進行の自動生成, 世良拓也,大井雄介,浜野祐介,谷口浩平; 深層学習による歌詞を考慮したコード進行の自動生成; 情報処理学会第84回全国大会講演論文集,pp.99-100,2022執筆者プロフィール

大澤 真優乃(おおさわ まゆの)
AI・アナリティクス事業統括部 データサイエンスコンピテンシーセンター
2022年4月、日本電気株式会社入社。大学では人間工学や統計を学び、入社後はPythonを勉強しながらデータ分析業務を務めている。AI・アナリティクス事業統括部では珍しい学部卒。趣味は音楽で、社会人になってから新しい楽器に触れたいと思い、バイオリンのレッスンに通い始めた。
執筆者プロフィール

大井 雄介(おおい ゆうすけ)
AI・アナリティクス事業統括部 AIプロダクト&サービスセンター
2014年4月、日本電気株式会社入社。技術開発職としてRAPID機械学習やテキスト分析 with Deep Learningといった深層学習を利用したソフトウェアの開発に従事するとともに、販促・データ分析作業も兼務。画像、テキストをはじめ業種問わず幅広なデータ分析に携わっている。現在は主に自然言語処理を担当。ライブ参加やカメラが趣味で、プライベートでは知人のライブイベントの撮影なども行っている。
執筆者プロフィール

世良 拓也(せら たくや)
AI・アナリティクス事業統括部 データサイエンスコンピテンシーセンター
2018年4月、日本電気株式会社入社。製造業、官公庁のお客様を中心に、自然言語処理、機械学習を活用した分析サービス、システム導入支援に従事。AI楽器、AI音楽生成、AIファッション生成、「waneco talk」のような新しいAI活用テーマにも挑戦。楽曲制作を兼職として行っている。
執筆者プロフィール

浜野 佑介(はまの ゆうすけ)
AI・アナリティクス事業統括部 データサイエンスコンピテンシーセンター
2021年4月、日本電気株式会社入社。現在は銀行業のお客様を中心に、データ基盤の開発支援に従事。最先端の機械学習モデルをキャッチアップしつつも、それらを活用したクラウドネイティブなシステム構築について学んでいる。また、エンタメ領域やVRにも興味があり、趣味でバーチャル学会などに参加経験がある。
執筆者プロフィール

谷口 浩平(たにぐち こうへい)
AI・アナリティクス事業統括部 AIプロダクト&サービスセンター
2021年4月、日本電気株式会社入社。現在は製造業や官公庁のお客様を中心に、画像認識AIを活用した業務効率化支援に従事。作曲活動とラジオ配信にプライベートの大半を費やしている。