
Japan
サイト内の現在位置
「特徴量重要度」って結局何の指標を使えばいいの?
2022年9月22日
はじめに
突然ですが、皆さんにはこんな経験ありませんか?
あなた「AIにとにかくいろんなデータを学習させてみたら予測精度が80%を超えました!」
上司「ほう、それは凄い!で、なぜそんなに精度が上がったんだい?」
あなた「(わ、わかんないっピ…)」
とにかく高い精度をもとめてがむしゃらにやってみたら、なんかいい感じの精度が出たけど、理由は説明できない。
そんな困ったときに役立つのが「特徴量重要度」という指標です。学習させた数々のデータのうち、結局どれが予測に貢献しているのか定量的に計ることでどの特徴量が重要なのか推測することができます。
今回はこの特徴量重要度を計る際に役に立つ手法をいくつか、古典的なものから新しいものまでご紹介したいと思います。
そもそも特徴量とは
そんなもん知ってるよ!という方は読み飛ばしてください。
特徴量とは、機械学習において予測の手がかりとなる数値のことです。
例えばある商品の売上予測をしたい場合、過去の販売実績などを参照すればある程度パターンが見えてだいたいの予測を人間でもできるはずです。これを機械学習で行う場合、過去の販売実績・価格・気温・曜日など手掛かりになりそうなデータを数値化し学習させて予測モデルを作ります。この予測に用いる数値化されたデータを特徴量と呼びます。
特徴量重要度ってどうやって分かるの?
特徴量の中には、目的変数の予測にとても重要なものもあれば、そうでないものも混ざっています。特徴量重要度を参考にしたうえで特徴量を適切に取捨選択することで、予測精度の向上やモデル作成効率化が見込まれます。
それでは本題ですが、どのようにして特徴量重要度を計るのでしょうか。わ、わかんないっピ…という方はぜひ最後まで読んでくださいね☆
ものは試しで、実際のデータを使って特徴量重要度を計ってみましょう。
今回はBoston housing Dataset[1]を使います。Boston housing Datasetは住宅価格の予測を目的としたデータセットで、機械学習初心者向けチュートリアルとして非常によく使われます。データは13属性(説明変数)+1属性(目的変数)の14属性で構成されています(提供元によって多少違いがあります)。
- CRIM 町ごとの犯罪率
- ZN 25,000平方フィートを超える区画に分類される住宅地の割合(広い家の割合)
- INDUS 町ごとの非小売業の割合
- CHAS チャールズ川に接しているか否か(川に接している場合は1、そうでなければ0)
- NOX 一酸化窒素濃度(0.1ppm単位)
- RM 住居あたりの平均部屋数
- AGE 1940年以前に建設された持ち家の割合(古い家の割合)
- DIS 5つのボストン雇用センターまでの加重距離(主要施設への距離)
- RAD 主要高速道路へのアクセス性の指数
- TAX 10,000ドルあたりの固定資産税率
- PTRATIO 町ごとの生徒と教師の比率
- B 町ごとの黒人の割合
- LSTAT 低所得者人口の割合
- MEDV 住宅価格(1000ドル単位)の中央値(目的変数)
機械学習の手法は大きく分けると「教師あり学習」「教師なし学習」の2つに分類され、今回のデータのように学習用に蓄積されたデータと正解データの組がある場合は「教師あり学習」を行うのが一般的です。
教師あり学習の代表的な方法として、連続値の予測を行う「回帰」と、複数のカテゴリのうちいずれに該当するのか予測する「分類」があります。今回は住宅価格という連続値を予測するため「回帰」を用いるのが適切です。
前処理については、こちらのデータは全て数値データのため変数変換は必要ありません。本来であれば前処理には欠損値補間や標準化などいろいろあるのですが、今回は特に何もせずそのまま学習データとして使おうと思います。
回帰分析を行うにあたり様々なアルゴリズムが存在しますが、今回はKaggle等のデータ分析コンペでも非常によく使われる決定木回帰の一つであるXGBoostを用います。
特徴量重要度の羅針盤
ここでは特徴量重要度を計るための羅針盤として3つの手法を紹介し、その結果の違いを比較したいと思います。そして最後に、各手法の結果をもとに特徴量選択を行ってモデル精度評価をしてみます。
相関係数
特徴量重要度について、統計学でも古くからよく使われている指標は「相関係数」です。
相関係数とは、2つの変数の関係性の強さを−1から1の間の値で表した数値です。+1 に近ければ近いほど「強い正の相関がある」、−1 に近ければ近いほど「強い負の相関がある」、0 に近ければ近いほど「ほとんど相関がない」と評価されます。
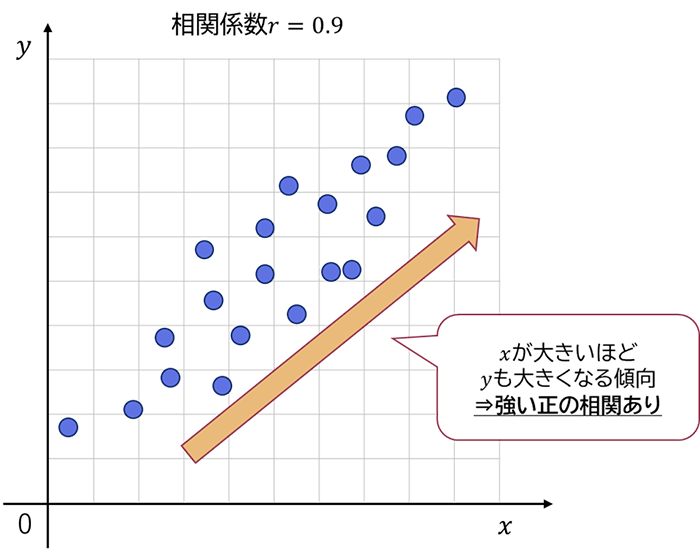
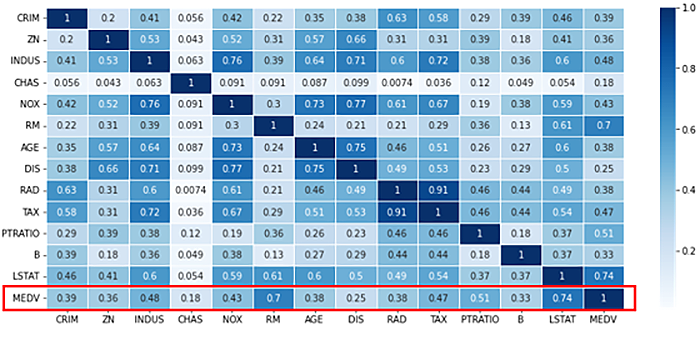
試しにBoston housing Datasetにおける相関係数のヒートマップ(二次元の配列を分かりやすく可視化したもの 色が濃いほど数値が高い)を見てみましょう。目的変数であるMEDVに対して相関が高いのはLSTAT(相関係数:0.74)、RM(相関係数:0.7)、PTRATIO(相関係数:0.51)の順であることが分かります。逆に相関が低いのはCHAS(相関係数:0.18)で、あまり重要でない特徴量かもしれません。
SHAP[2]
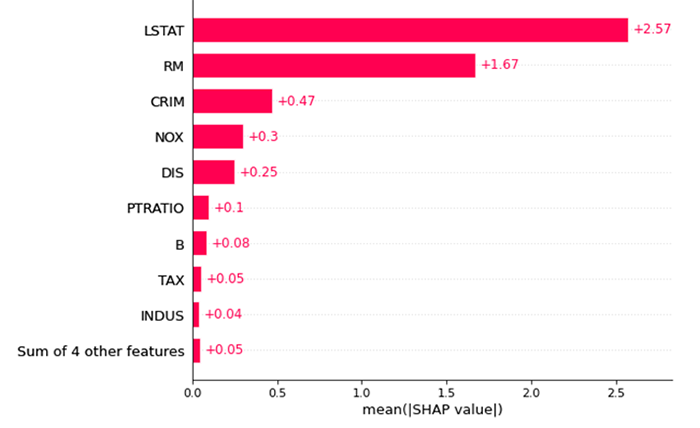
特徴量重要度の指標として近年非常によく用いられる指標がSHAPです。正式名称はSHapley Additive exPlanationsで、線形回帰モデルと協力ゲーム理論を用いて予測に対する特徴量の貢献度を定量的に評価する手法です。コードは割愛しますがOSSライブラリとして公開されているため実装も容易にできます。
Boston housing Datasetの特徴量に対してXGBoostを用いた回帰モデルを作成しSHAP値を比較すると図3のようなグラフになりました。高い順にLSTAT(SHAP値:2.57),RM(SHAP値:1.67),CRIM(SHAP値:0.47),NOX(SHAP値:0.3)と並んでおり、先ほどの相関係数の結果とは少し異なることが分かります。
Cohort Shapley[3]
さて、今回ようやく1番紹介したかった手法が出てきました。2022年6月に開催されたJSAI(人工知能学会全国大会)[4]にて発表された比較的新しい手法です。日立製作所で機械学習の説明性・解釈性の研究を主に従事されている間瀬氏によるもので、とても興味深いお話でしたので紹介させていただきます。
そもそものお話ですが、最近の機械学習において、予測モデルが特定の出力を生成する理由を理解するのは非常に困難になってきています。そのためブラックボックスAIと揶揄されることがよくあるのですが、透明性を確保するためにXAI(eXplainable AIの略 機械学習のアウトプットを人間が理解し信頼やすくするための手法)という分野が集中的に研究されています。先ほど紹介したSHAPもその1つなのですが、従来手法では各変数の予測への貢献度を評価する過程において、実際には存在しない合成データを生成するプロセスがあるため、信頼性に欠ける場合があるという指摘があります。そこで、Cohort Shapleyでは合成データを生成せず、実際に観測されている変数とその予測値(目的変数)のみ用いて各変数の貢献度を評価するという手法を取っています。これにより変数と予測値との因果関係を崩すことなく、より信頼できる貢献度評価を行うことができるとされています。
それでは、Boston housing Datasetの特徴量に対してXGBoostを用いた回帰モデルについてSHAP値とCohort Shapley値を比較してみましょう。
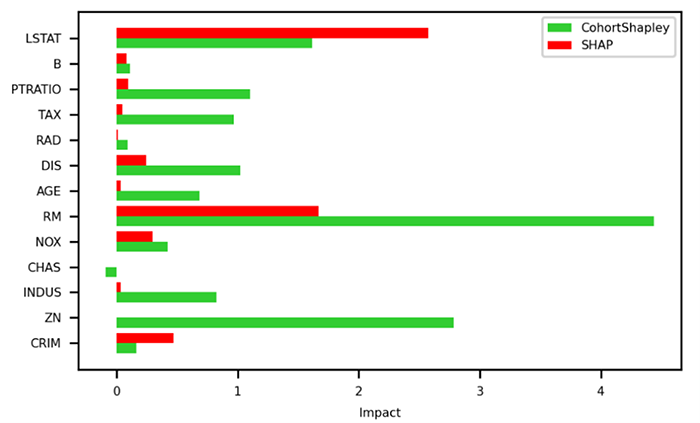
図4を見ていただくと、SHAP値とCohort Shapley値で意外と差があることが分かります。SHAP値は高い順にLSTAT,RM,CRIM,NOX…ですが、Cohort ShapleyはRM,ZN,LSTAT,PTRATIO…の順になっています。特にZN(広い家の割合)に対する両者の重要度の差が大きいのが分かります。直感的には、広い家が多い地域=家賃相場が高いとは必ずしもならなそうだし、図2のとおりZNの相関係数もあまり高くないのですが、従来の手法では見えなかった重要度が出てくるのが面白いところですね。
特徴量重要度の比較評価
それでは最後に、これらの重要度を基準に特徴量選択をしたうえでモデルの精度を確かめてみましょう。
今回のような回帰モデルの場合の評価基準は一般にRMSE(Root Mean Square Error 二乗平均平方根誤差)と決定係数がよく用いられます。RMSEは予測と値がどれほど離れているのか計算した値で、小さければ小さいほど差がない(予測と正解が近い)ということになります。決定係数は目的変数に対する予測値の説明力を表す指標で0~1の値をとり、1に近いほど有効とされています。
各重要度指標の比較のため、相関係数・SHAP・CohortShapleyそれぞれの重要度上位8件までの特徴量に絞りXGBoostのモデルにかけてみました。
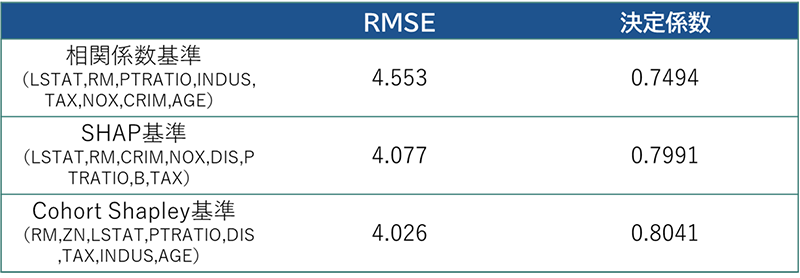
図5の結果をみると、大きな差があるわけではありませんが相関係数基準・SHAP基準に比べてCohort Shapley基準では精度が高いことが分かります。もちろんこの結果だけで優劣を判断することはできませんが、少なくともCohort Shapleyが充分に参考になる重要度指標であるといえるのではないでしょうか。
おわりに
今回は特徴量重要度の指標について新しいものを含めて3つ紹介しました。今回紹介した以外にも様々な指標が研究されていますので、ぜひいろいろ探してみて下さい。
AIについてまだまだ勉強中の身ですが、予測精度を上げようとして複雑なモデルを作ると説明が難しくなるんですよね。私もXAI(eXplainable AI)についてもっとよく勉強して、お客さまや上司から説明を求められたときに、「わ、わかんないっピ…」とならないように頑張りたいと思います!
参考文献・サイト
 Boston housing dataset | Kaggle
Boston housing dataset | Kaggle執筆者プロフィール

池田 匡(いけだ まさし)
AI・アナリティクス事業統括部 データサイエンス3G
2022年1月NEC中途入社。前職では鉄道会社にてシステム企画およびデータ分析業務を務める。現在は自然言語処理を中心としたテキスト分析や提案事業に従事。4歳息子と1歳娘の父業務も兼務。