Japan
サイト内の現在位置を表示しています。
【2021年版】AWSで両系活性を防止する方法(Windows/Linux)
CLUSTERPRO オフィシャルブログ ~クラブロ~
※本記事の改訂版(2022年版)を公開しています。
※2024/09/13 以下を追記。
- -OS起動時間の調整について記述を追加しました。
はじめに
Amazon Web Services(以降、AWS)において、HAクラスターの両系活性を防止するために、CLUSTERPROの機能の一つである強制停止スクリプトを利用したHAクラスターの構築を試してみました。
本記事は、 以前のブログの改訂版(2021年版)です。
以前のブログの改訂版(2021年版)です。
前回の記事公開から、CLUSTERPROのアップデートがいくつかリリースされており、設定方法、設定項目に更新がありますので合わせてご紹介します。
本記事の主な改訂内容は以下の通りです。
- ・HTTP NP解決リソースによるネットワークパーティション解決の設定方法
- ・強制停止スクリプトの戻り値判定の設定(フェイルオーバーの抑制)方法
- ・Cluster WebUIを使用した設定方法
- ・サンプルスクリプト(Windows版)の追加
CLUSTERPROでは、両系活性を防止する方法としてネットワークパーティション解決(以降、NP解決)が設定可能です。AWSにおける推奨構成ではHTTP NP解決を設定します。(HTTP NP解決は、CLUSTERPRO X 4.1以降で設定可能です)
NP解決の詳細は
こちら。 しかし、NP解決を設定したとしてもOSストールや、AZ間の通信断などの障害が起きた場合は、両系活性が発生する可能性があります。
そのような場合にも両系活性を発生させない方法として、強制停止スクリプトという機能があります。
今回は、この強制停止スクリプトをAWS上のHAクラスターに設定します。
- ※物理環境では、IPMIの機能や、VMware vCenter Serverの機能を利用する「強制停止機能」によって、サーバーを停止することができます。AWS環境では同様の機能は使用できないため、強制停止スクリプトによりサーバーの停止を実現します。
この記事の内容
1. 強制停止スクリプトとは
強制停止スクリプトとは、サーバーのダウンを認識したときに残りのサーバー(正常なサーバー)でユーザーが作成した任意のスクリプトを実行する機能です。この機能を使用することで、ダウンしたサーバーを強制的に停止させることが可能になります。
これにより、ネットワークパーティション(スプリットブレイン)の状態が発生した場合でも、NP解決リソースによる対応に加えて強制停止スクリプトを利用してサーバーを停止させることで、両系活性の防止をより確実なものにすることができます。
強制停止スクリプトを実行する契機は、ハートビートタイムアウトによりサーバーのダウンを検出し、ダウンしたサーバーで起動していたフェールオーバーグループを他のサーバーで起動する場合となります。
Cluster WebUIなどからサーバーを正常に停止した場合や、ダウンしたサーバー上でフェールオーバーグループが起動しておらずフェールオーバーが発生しない、といった場合は強制停止スクリプトを実行しないため、不必要なタイミングでサーバーを強制停止することはありません。
強制停止スクリプトの詳細については、リファレンスガイドをご参照ください。
【参考】
● CLUSTERPRO X 4.3 > Windows > リファレンスガイド
→第 7 章 その他の監視設定情報
→7.2 強制停止スクリプト
● CLUSTERPRO X 4.3 > Linux > リファレンスガイド
→第 7 章 その他の監視設定情報
→7.4 強制停止スクリプト
2. 構築するHAクラスター構成
「VIP制御によるHAクラスター」を構築します。AWS構築ガイドの構成から少し変更します。
AWS構築ガイドではHTTP NP解決のターゲットとしてVPC外(インターネット上)のWebサーバーを指定していますが、セキュリティポリシーなどによりHAクラスターの構成サーバーからインターネットへアクセスさせたくない場合は利用できません。
本記事ではインターネットへアクセスしないHAクラスター構成として、「VPCエンドポイント」と組み合わせたパターンで「VIP制御によるHAクラスター」を構築します。
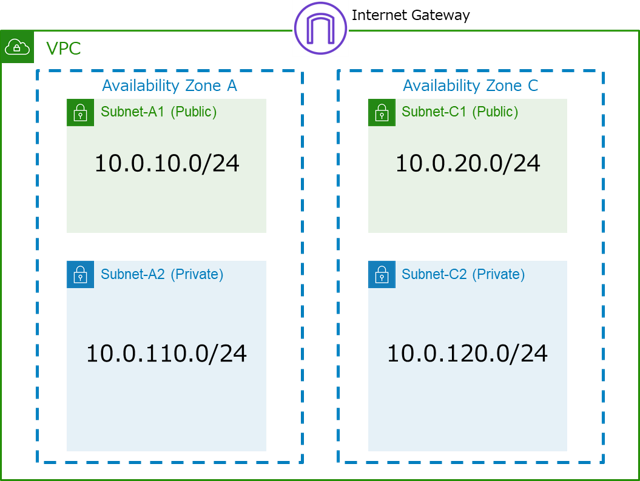
構築するHAクラスターの構成図は以下の通りです。

フェールオーバーグループにはAWS仮想IPリソース、ミラーディスクリソースのみを設定します。
また、HTTP NP解決のターゲットには、Amazon S3上に作成したウェブサイトを指定します。Amazon S3へはゲートウェイエンドポイントを介してアクセスを行い、セキュリティの観点から、HAクラスターを構築するVPCからのみ接続可能となるように設定します。
さらに、強制停止スクリプトを設定し、AWS CLIを利用してダウンしたサーバーをシャットダウンします。
- ※NP解決リソースはHAクラスター環境に合わせて適宜設定してください。
たとえば、オンプレミスにあるクライアントがDirectConnectを使用してAWS上のHAクラスター環境にアクセスする場合、Ping NP解決リソースを使用して、Pingターゲットにオンプレミス側のゲートウェイを設定することでNP解決を実現することも可能です。
ゲートウェイエンドポイントの詳細や作成手順、Amazon S3上でウェブサイトをホスティングする手順については以下を参照ください。
3. HAクラスターの構築手順
HAクラスターの構築手順をご紹介します。
構築手順は、WindowsとLinuxで異なりますのでご注意ください。
3.1 HAクラスター構築の事前準備
AWS環境における事前準備の詳細はAWS構築ガイドをご参照ください。
今回の構成では、AWS CLIのコマンド実行時のHAクラスター構成サーバーからエンドポイントに対する通信にVPCエンドポイントを利用するため、NATインスタンスの作成は不要です。
VPCエンドポイントの設定手順は、以前のブログをご参照ください。
【参考】
● Windows > クラウド > Amazon Web Services
→CLUSTERPRO X 4.3 向け HAクラスタ 構築ガイド
→第 5 章 VIP 制御によるHA クラスタの設定
→5.1 VPC 環境の設定
→5.2 インスタンスの設定
● Linux > クラウド > Amazon Web Services
→CLUSTERPRO X 4.3 向け HAクラスタ 構築ガイド
→第 5 章 VIP 制御によるHA クラスタの設定
→5.1 VPC 環境の設定
→5.2 インスタンスの設定
また、今回は強制停止スクリプトでEC2インスタンスを停止するため、強制停止スクリプトからAWS CLIのstop-instanceコマンドを実行します。そのため、サーバーに割り当てるIAMロールのポリシーにEC2:StopInstancesのアクションを追加します。AWS仮想IPリソースの制御に必要なアクションと合わせ、IAMロールのポリシーでは以下のアクションを許可します。
"ec2:Describe*"
"ec2:StopInstances"
"ec2:ReplaceRoute"
VPCの構成は以下の通りです。
Amazon S3(VPCエンドポイント)への経路は、ゲートウェイエンドポイント作成時に選択したルートテーブルへ自動的に追加されます。
- VPC(VPC ID:vpc-1234abcd)
- -CIDR:10.0.0.0/16
- -Subnets
- ■Subnet-A1 (サブネット ID:sub-1111aaaa):10.0.10.0/24
- ■Subnet-A2 (サブネット ID:sub-2222aaaa):10.0.110.0/24
- ■Subnet-C1 (サブネット ID:sub-1111cccc):10.0.20.0/24
- ■Subnet-C2 (サブネット ID:sub-2222cccc):10.0.120.0/24
- -RouteTables
- ■Main (ルートテーブル ID:rtb-00000001)
- >10.0.0.0/16 → local
- >0.0.0.0/0 → igw-1234abcd (Internet Gateway)
- >20.0.0.200/32 → eni-1234abcd (ENI ID)
- ■Route-A (ルートテーブル ID:rtb-0000000a)
- >10.0.0.0/16 → local
- >20.0.0.200/32 → eni-1234abcd (ENI ID)
- >pl-xxxxxxxx → vpce-5678cdef (Endpoint ID)
- ※Amazon S3(VPCエンドポイント)への経路
- ■Route-C (ルートテーブル ID:rtb-0000000c)
- >10.0.0.0/16 → local
- >20.0.0.200/32 → eni-1234abcd (ENI ID)
- >pl-xxxxxxxx → vpce-5678cdef (Endpoint ID)
- ※Amazon S3(VPCエンドポイント)への経路
3.2 HAクラスターの構築
「VIP制御によるHAクラスター」の構築手順の詳細については、AWS構築ガイドをご参照ください。
【参考】
● Windows > クラウド > Amazon Web Services
→CLUSTERPRO X 4.3 向け HAクラスタ 構築ガイド
→第 5 章 VIP 制御によるHA クラスタの設定
→5.3 CLUSTERPRO の設定
● Linux > クラウド > Amazon Web Services
→CLUSTERPRO X 4.3 向け HAクラスタ 構築ガイド
→第 5 章 VIP 制御によるHA クラスタの設定
→5.3 CLUSTERPRO の設定
今回の構成ではAWS構築ガイドの構成からHTTP NP解決リソースのターゲットホストを変更、また、強制停止スクリプトを追加で設定します。
HTTP NP解決のターゲットホストにAmazon S3上に作成したウェブサイトを指定します。

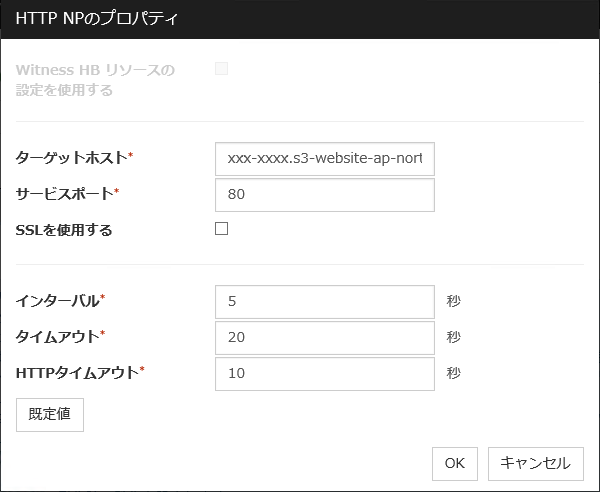
3.2.1 HTTP NP解決リソースの設定
HTTP NP解決リソースは、以下のように設定します。
今回は、Amazon S3上に作成したウェブサイトに対して、HTTP NP解決リソースの設定を行います。

HTTP NP解決リソースのプロパティは以下の通りです。
3.2.2 強制停止スクリプトの設定
強制停止スクリプトは、以下のように設定します。
- 1.「クラスタのプロパティ」の「拡張」タブにて、「強制停止スクリプトを実行する」をチェックし、「スクリプト設定」をクリックします。

- 2.「スクリプトの編集」で「編集」をクリックします。

- 3.起動したテキストエディタで、以下のスクリプトを入力します。
- ※以下のスクリプトはサンプルであり、動作を保証するものではありません。
- ※★部分の変数の値は環境に合わせて設定してください。
- ※スクリプトが正常終了する際に戻り値として0を返却するように記述します。
強制停止スクリプト(Windows)
@echo off
rem ***************************************
rem * forcestop.bat *
rem ***************************************
rem AWS CLI用の設定情報
set AWS_CONFIG_FILE=C:\Users\Administrator\.aws\config
rem AWS CLIの絶対パス
set AWS_PATH="C:\Program Files\Amazon\AWSCLI\bin\aws.exe"
rem 1ノード目の設定情報
set SERVER1_NAME=server01 ★ サーバー1のホスト名
set SERVER1_INSTANCE=i-11111111111111111 ★ サーバー1のインスタンスID
rem 2ノード目の設定情報
set SERVER2_NAME=server02 ★ サーバー2のホスト名
set SERVER2_INSTANCE=i-22222222222222222 ★ サーバー2のインスタンスID
rem インスタンス停止の最大試行回数
set STOP_LOOP_MAX=2 ★ 停止処理の最大試行回数
rem インスタンス状態確認の最大試行回数
set CHECK_LOOP_MAX=240 ★ 確認処理の最大試行回数
echo "START"
echo "DOWN SERVER NAME : %CLP_SERVER_DOWN%"
echo "LOCAL SERVER NAME: %CLP_SERVER_LOCAL%"
if %CLP_SERVER_DOWN%==%SERVER1_NAME% (
set INSTANCE_ID=%SERVER1_INSTANCE%
) else if %CLP_SERVER_DOWN%==%SERVER2_NAME% (
set INSTANCE_ID=%SERVER2_INSTANCE%
) else (
echo "SERVER is not found."
exit 1
)
rem シャットダウン要求
STOP_LOOP_COUNT=0
:STOP_LOOP
%AWS_PATH% ec2 stop-instances --instance-ids %INSTANCE_ID% --force
set ret=%ERRORLEVEL%
if %ERRORLEVEL%==0 (
echo "succeeded to stop instance. (%INSTANCE_ID%)"
GOTO STOP_CHECK
)
echo "failed to stop instance. (%INSTANCE_ID%, ret=%ret%)"
timeout /t 1
set /a STOP_LOOP_COUNT=STOP_LOOP_COUNT+1
if %STOP_LOOP_COUNT%==%STOP_LOOP_MAX% (
echo "EXIT %ret%"
exit %ret%
)
GOTO STOP_LOOP
:STOP_CHECK
rem サーバーダウン確認
rem サーバーの停止を確認できなくても、
rem CHECK_LOOP_MAXを超えた場合は停止が失敗したとして処理を終了する
set CHECK_LOOP_COUNT=0
:CHECK_LOOP
%AWS_PATH% ec2 describe-instances --instance-ids %INSTANCE_ID% --filters "Name=instance-state-name,Values=stopped" | findstr %INSTANCE_ID%
set ret=%ERRORLEVEL%
if %ERRORLEVEL%==0 (
echo "%INSTANCE_ID% has been stopped."
GOTO EXIT
)
timeout /t 1
set /a CHECK_LOOP_COUNT=CHECK_LOOP_COUNT+1
if %CHECK_LOOP_COUNT%==%CHECK_LOOP_MAX% (
echo "EXIT %ret%"
exit %ret%
)
GOTO CHECK_LOOP
:EXIT
echo "EXIT 0"
exit 0
強制停止スクリプト(Linux)
#! /bin/sh
#***************************************
#* forcestop.sh *
#***************************************
# AWS CLIの絶対パス
AWS_CLI="/usr/local/bin/aws" ★ AWS CLIのパス
# 1ノード目の設定情報
SERVER1_NAME="server01" ★ サーバー1のホスト名
SERVER1_INSTANCE="i-11111111111111111" ★ サーバー1のインスタンスID
# 2ノード目の設定情報
SERVER2_NAME="server02" ★ サーバー2のホスト名
SERVER2_INSTANCE="i-22222222222222222" ★ サーバー2のインスタンスID
# インスタンス停止の最大試行回数
STOP_LOOP_MAX=2 ★ 停止処理の最大試行回数
# インスタンス状態確認の最大試行回数
CHECK_LOOP_MAX=240 ★ 確認処理の最大試行回数
echo "START"
echo "DOWN SERVER NAME : ${CLP_SERVER_DOWN}"
echo "LOCAL SERVER NAME: ${CLP_SERVER_LOCAL}"
if [ "${CLP_SERVER_DOWN}" = "${SERVER1_NAME}" ]; then
INSTANCE="${SERVER1_INSTANCE}"
elif [ "${CLP_SERVER_DOWN}" = "${SERVER2_NAME}" ]; then
INSTANCE=${SERVER2_INSTANCE}
else
echo "DOWN SERVER is not found."
echo "EXIT 1"
exit 1
fi
# シャットダウン要求
STOP_LOOP_COUNT=0
while [ ${STOP_LOOP_COUNT} -lt ${STOP_LOOP_MAX} ]
do
${AWS_CLI} ec2 stop-instances --instance-ids ${INSTANCE} --force
ret=$?
if [ ${ret} -eq 0 ]; then
echo "succeeded to stop instance. (${INSTANCE})"
break
fi
echo "failed to stop instance. (${INSTANCE}, ret=${ret})"
sleep 1
let STOP_LOOP_COUNT=${STOP_LOOP_COUNT}+1
done
if [ ${ret} -ne 0 ]; then
echo "EXIT ${ret}"
exit ${ret}
fi
# サーバーダウン確認
# サーバーの停止を確認できなくても、
# CHECK_LOOP_MAXを超えた場合は停止が失敗したとして処理を終了する
CHECK_LOOP_COUNT=0
while [ ${CHECK_LOOP_COUNT} -lt ${CHECK_LOOP_MAX} ]
do
${AWS_CLI} ec2 describe-instances --instance-ids ${INSTANCE} --filters "Name=instance-state-name,Values=stopped" | grep ${INSTANCE}
ret=$?
if [ ${ret} -eq 0 ]; then
echo "${INSTANCE} has been stopped."
break
fi
sleep 1
let CHECK_LOOP_COUNT=${CHECK_LOOP_COUNT}+1
done
if [ ${ret} -ne 0 ]; then
echo "EXIT ${ret}"
exit ${ret}
fi
echo "EXIT 0"
exit 0
- 4.「スクリプトの編集」に戻り、「フェイルオーバーの抑制」、「タイムアウト」を設定します。
[実行失敗時にグループのフェイルオーバを抑制する]にチェックを入れ、設定を有効化します。(フェイルオーバ抑制の設定は、CLUSTERPRO X 4.1以降で設定可能です。)
こちらの設定を有効化することで、強制停止スクリプトの戻り値を判定します。強制停止スクリプトが失敗した場合は、フェールオーバーが抑制されるため、より確実に両系活性を防止することが可能です。
また、今回は強制停止スクリプトでダウンしたサーバーの停止完了の待ち合わせを実施するため、タイムアウトを300秒に設定します。

強制停止スクリプトの設定後に、OSの起動時間を調整します。
強制停止スクリプト実行中に対向サーバーでOS再起動などが実行された場合に、両系活性が発生することや、クラスター起動処理中に強制停止が実行されることを防止します。
OSの起動時間を以下となるように設定します。
OSの起動時間 >= 強制停止スクリプトのタイムアウト + ハートビートタイムアウト + ハートビートインターバル
OS起動時間の調整手順の詳細については、インストール&設定ガイドをご参照ください。
【参考】
● CLUSTERPRO X 4.3 > Windows > インストール&設定ガイド
→第 2 章 システム構成を決定する
→2.6 ハードウェア構成後の設定
→2.6.3. OS 起動時間を調整する (必須)
● CLUSTERPRO X 4.3 > Linux > インストール&設定ガイド
→第 2 章 システム構成を決定する
→2.8 ハードウェア構成後の設定
→2.8.5. OS 起動時間を調整する (必須)
CLUSTERPRO X 4.3以前のバージョンでは、Windowsの場合のみ、OS起動時間を調整する代わりに互換コマンド(armdelay.exe)を使用してCLUSTERPROサービスの起動を遅延させることで対応が可能です。
CLUSTERPROサービス起動時の遅延時間を以下となるように設定します。
CLUSTERPROサービス起動時の遅延時間 >= 強制停止スクリプトのタイムアウト + ハートビートタイムアウト + ハートビートインターバル
CLUSTERPROサービス起動時の遅延時間の設定手順の詳細については、互換機能ガイドをご参照ください。
【参考】
● 共通 > 互換機能ガイド(Windows)
→第 4 章 互換コマンドリファレンス
→4.24 起動遅延時間を設定/表示する(armdelay コマンド)
詳細については、
【2024年版】サービス起動遅延時間設定機能の紹介も併せて参照ください。- ※リンク先の記事はCLUSTERPRO X 5.0から追加されたサービス起動遅延時間設定機能について解説していますが、サービス起動遅延時間の考え方とOS起動時間を調整する(遅延させる)考え方は同じものです。
また、リンク先の記事では強制停止スクリプトではなく、CLUSTERPRO X 5.0から追加された強制停止リソースを利用しています。リンク先の記事の「強制停止リソースの強制停止タイムアウト時間 + 強制停止リソースの停止完了待ち時間」の部分は本記事の「強制停止スクリプトのタイムアウト」と読み替えてください。
4. NP解決時の動作確認
強制停止スクリプトを実行する構成、また、実行しない構成で、ネットワークパーティション状態を起こして、HAクラスターの動作を確認します。
今回は、Windows環境における動作確認の例を記載します。
ネットワークパーティション状態を起こすため、ネットワークACLの設定によりHAクラスターを構成するサーバーのAZ間をまたぐ通信を全て遮断するようにしました。これにより、サーバー間のハートビートが途絶えますが、Amazon S3上に作成したウェブサイトへのhttp通信は可能であるため、それぞれのサーバーが「相手サーバーで問題が発生した」と判断してフェールオーバーグループを起動しようとします。

4.1 強制停止スクリプトを実行しない場合
強制停止スクリプトを実行しない場合、それぞれのサーバーがフェールオーバーグループを起動するため、両系活性状態となってしまいます。
それぞれのサーバーでHAクラスターの起動状態を確認すると以下となります。それぞれのサーバーでフェールオーバーグループが起動していることが確認できます。
[サーバー1のクラスターの起動状態]
サーバー1でフェールオーバーグループが起動しています。
C:\Users\Administrator>clpstat
======================== CLUSTER STATUS ===========================
Cluster : cluster
*server01 ........: Online ←server01は起動中
lankhb1 : Normal LAN Heartbeat
httpnp1 : Normal http resolution
server02 ........: Offline ←server02は停止中
lankhb1 : Unknown LAN Heartbeat
httpnp1 : Unknown http resolution
failover ........: Online
current : server01 ←server01でフェールオーバーグループが起動中
awsvip : Online
md : Online
awsvipw1 : Normal
mdnw1 : Error
mdw1 : Caution
userw : Normal
=====================================================================
[サーバー2のクラスターの起動状態]
サーバー2でフェールオーバーグループが起動しています。
C:\Users\Administrator>clpstat
======================== CLUSTER STATUS ===========================
Cluster : cluster
server01 ........: Offline ←server01は停止中
lankhb1 : Unknown LAN Heartbeat
httpnp1 : Unknown http resolution
*server02 ........: Online ←server02は起動中
lankhb1 : Normal LAN Heartbeat
httpnp1 : Normal http resolution
failover ........: Online
current : server02 ←server02でフェールオーバーグループが起動中
awsvip : Online
md : Online
awsvipw1 : Normal
mdnw1 : Caution
mdw1 : Caution
userw : Normal
=====================================================================
4.2 強制停止スクリプトを実行する場合
強制停止スクリプトを実行する場合、待機系サーバーはフェールオーバーグループを起動する前に強制停止スクリプトを実行して現用系サーバーを停止させます。そのため、両系活性を防ぐことができます。
待機系サーバーが現用系サーバーのダウンを検出した後のイベントログの出力は以下のようになります。フェールオーバーグループの起動前に強制停止スクリプトを実行していることが確認できます。
情報 2021/05/18 7:18:17 CLUSTERPRO X 2401 なし ミラーディスクmdのフルコピーを開始しました。
情報 2021/05/18 7:18:19 CLUSTERPRO X 2402 なし ミラーディスクmdのフルコピーが成功しました。
情報 2021/05/18 7:18:23 CLUSTERPRO X 1526 なし 監視 mdw1 の状態が正常に復帰しました。
情報 2021/05/18 7:20:42 CLUSTERPRO X 2 なし サーバserver01が停止しました。 ★現用系サーバーのダウンを検出
情報 2021/05/18 7:20:44 CLUSTERPRO X 1405 なし 強制停止スクリプトを開始しました。 ★強制停止スクリプトを実行開始
警告 2021/05/18 7:20:57 CLUSTERPRO X 1504 なし 監視 mdw1 は警告の状態です。 (102 : ミラーディスクmdはミラーリングされていません。)
警告 2021/05/18 7:21:18 CLUSTERPRO X 1504 なし 監視 mdnw1 は警告の状態です。 (100 : ネットワーク異常。)
情報 2021/05/18 7:21:27 CLUSTERPRO X 1406 なし 強制停止スクリプトが完了しました。 ★強制停止スクリプトの実行完了
情報 2021/05/18 7:21:28 CLUSTERPRO X 1060 なし グループ failover をフェイルオーバしています。 ★フェールオーバーグループの起動を開始
情報 2021/05/18 7:21:29 CLUSTERPRO X 1010 なし グループ failover を起動しています。
情報 2021/05/18 7:21:30 CLUSTERPRO X 1030 なし リソース awsvip を起動しています。
フェールオーバー完了後、現用系サーバーのEC2インスタンスの起動状態を確認するとstoppedとなっており、現用系インスタンスが停止していることを確認できます。
C:\Users\Administrator>aws ec2 describe-instances --instance-ids i-11111111111111111 --query "Reservations[0].Instances[0].[InstanceId, State.Name]"
[
[
[
"i-11111111111111111",
"stopped"
]
]
]
さいごに
今回は強制停止スクリプトを利用したHAクラスターの構築手順をご紹介しました。
AWS上でネットワークパーティション発生時に両系活性をより確実に防止することができますので、強制停止スクリプトの利用をご検討ください。
お問い合わせ
本記事に関するお問い合わせは、お問い合わせ窓口までお問い合わせください。
お問い合わせ窓口までお問い合わせください。- ※本記事で紹介しているスクリプトの内容についてのお問い合わせ、および、お客様環境に合わせたカスタマイズにつきましてはCLUSTERPRO導入支援サービスにて承っておりますので、上記窓口の"ご購入前のお問い合わせ"フォームまでお問い合わせください。
