Japan
サイト内の現在位置を表示しています。
AWSで両系活性を防止する方法(Windows/Linux)
CLUSTERPRO オフィシャルブログ ~クラブロ~
はじめに
Amazon Web Services(以降、AWS)において、HAクラスターの両系活性を防止するために、CLUSTERPROの機能の一つである強制停止スクリプトを利用したHAクラスターの構築を試してみました。
CLUSTERPROでは、両系活性を防止する方法としてネットワークパーティション解決(以降、NP解決)が設定可能です。通常AWSでは、NP解決にPingNP解決を設定します。
NP解決の詳細は  こちら
こちら
2019年にリリースされたCLUSTERPRO X 4.1 以降では、HTTP NP解決が設定可能です。HTTP NP解決の設定例は、AWS構築ガイドをご参照ください。
たとえば、オンプレミスにあるクライアントがDirectConnectを使用してAWS上のHAクラスター環境にアクセスする場合、Pingターゲットにオンプレミス側のゲートウェイを設定することでPingNP解決を実現します。
しかし、適切なPingターゲットがない場合やOSがストールした場合などでは、両系活性が発生する可能性があります。
そこで、両系活性を発生させない方法として、強制停止スクリプトという機能があります。
今回は、この強制停止スクリプトをAWS上のHAクラスターに設定します。
- ※なお、物理環境では、IPMIの機能や、VMware vCenter Serverの機能を利用する「強制停止機能」によって、サーバーを停止することができます。AWS環境では同様の機能は使用できないため、強制停止スクリプトによりサーバーの停止を実現します。
HTTP NP解決の設定例はAWS構築ガイドをご参照ください。
【参考】
● Windows > クラウド > Amazon Web Services
→CLUSTERPRO X 4.3 向け HAクラスタ 構築ガイド
→第 2 章 機能概要
→2.4ネットワークパーティション解決
● Linux > クラウド > Amazon Web Services
→CLUSTERPRO X 4.3 向け HAクラスタ 構築ガイド
→第 2 章 機能概要
→2.4ネットワークパーティション解決
この記事の内容
1. 強制停止スクリプトとは
強制停止スクリプトとは、サーバーのダウンを認識したときに残りのサーバー(正常なサーバー)でユーザーが作成した任意のスクリプトを実行する機能です。この機能を使用することで、ダウンしたサーバーを強制的に停止させることが可能になります。
これにより、ネットワークパーティション(スプリットブレイン)の状態が発生した場合でも、NP解決リソースによる対応に加えて強制停止スクリプトを利用してサーバーを停止させることで、両系活性の防止をより確実なものにすることができます。
強制停止スクリプトを実行する契機は、ハートビートタイムアウトによりサーバーのダウンを検出し、ダウンしたサーバーで起動していたフェールオーバーグループを他のサーバーで起動する場合となります。
WebManagerなどからサーバーを正常に停止した場合や、ダウンしたサーバー上でフェールオーバーグループが起動しておらずフェールオーバーが発生しないなどの場合は、強制停止スクリプトを実行しません。
強制停止スクリプトの詳細については、リファレンスガイドをご参照ください。
【参考】
CLUSTERPRO X 4.0 システム構築ガイド
- > Windows
- > リファレンスガイド
- > 第 9 章 その他の監視設定情報
- > 強制停止スクリプト
- > Linux
- > リファレンスガイド
- > 第 8 章 その他の設定情報
- > 強制停止スクリプト
2. HAクラスター構成
今回は「VIP制御によるHAクラスター」を構築し、強制停止スクリプトを設定します。
強制停止スクリプトでは、AWS CLIを利用してダウンしたサーバーをシャットダウンします。
なお、フェールオーバーグループにはAWS仮想IPリソース、ミラーディスクリソースのみを設定します。

3. HAクラスターの構築手順
3.1 HAクラスター構築の事前準備
AWS環境における事前準備の詳細はAWS構築ガイドをご参照ください。
構築手順は、WindowsとLinuxで異なります。
Windows/Linuxそれぞれで検証実績がありますが、今回はLinuxの手順を記載します。
【参考】
CLUSTERPRO X 4.0 ソフトウェア構築ガイド
- > Linux
- > Amazon Web Services HAクラスタ構築ガイド
- > 第 4 章 VIP 制御によるHA クラスタの設定
今回、強制停止スクリプトでEC2インスタンスを停止するため、強制停止スクリプトからAWS CLIのstop-instanceを実行します。そのため、サーバーに割り当てるIAMロールのポリシーにEC2:StopInstancesのアクションを追加します。AWS仮想IPリソースの制御に必要なアクションと合わせ、IAMロールのポリシーでは以下のアクションを許可します。
"ec2:Describe*"
"ec2:StopInstances"
"ec2:ReplaceRoute"
VPCの構成は以下の通りです。
- VPC(VPC ID:vpc-1234abcd)
- -CIDR:10.0.0.0/16
- -Subnets
- ■Subnet-1a (サブネット ID:sub-1111aaaa):10.0.10.0/24
- ■Subnet-2a (サブネット ID:sub-2222aaaa):10.0.110.0/24
- ■Subnet-1c (サブネット ID:sub-1111cccc):10.0.20.0/24
- ■Subnet-2c (サブネット ID:sub-2222cccc):10.0.120.0/24
- -RouteTables
- ■Main (ルートテーブル ID:rtb-00000001)
- >10.0.0.0/16 → local
- >0.0.0.0/0 → igw-1234abcd (Internet Gateway)
- >20.0.0.200/32 → eni-1234abcd (ENI ID)
- ■Route-A (ルートテーブル ID:rtb-0000000a)
- >10.0.0.0/16 → local
- >0.0.0.0/0 → eni-1234abcd(NAT1のENI ID)
- >20.0.0.200/32 → eni-1234abcd (ENI ID)
- ■Route-C (ルートテーブル ID:rtb-0000000c)
- >10.0.0.0/16 → local
- >0.0.0.0/0 → eni-1234efgh(NAT2のENI ID)
- >20.0.0.200/32 → eni-1234abcd (ENI ID)

3.2 VIP制御によるHAクラスターの構築
構築手順の詳細については、AWS構築ガイドをご参照ください。
【参考】
CLUSTERPRO X 4.0 ソフトウェア構築ガイド
- > Linux
- > Amazon Web Services HAクラスタ構築ガイド
- > 第 4 章 VIP 制御によるHA クラスタの設定
今回の構成ではAWS構築ガイドの構成から変更し、NP解決リソース、強制停止スクリプトを設定します。
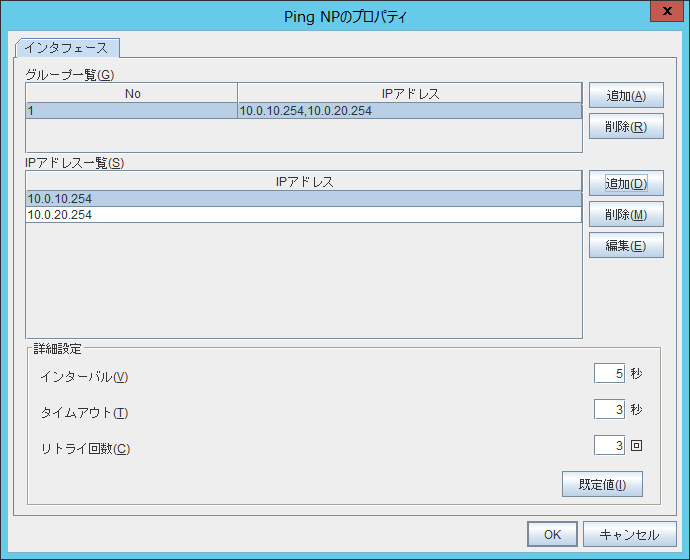
AWS構築ガイドでは、NP解決の設定としてIPモニタリソースを利用していますが、今回の構成ではPing NP解決リソースを設定します。Ping NP解決リソースによる確認対象として、各Availability Zone(AZ)で起動しているNATインスタンスを設定します。どちらかのNATインスタンスへのping疎通が通れば正常であるように設定します。
- ※Pingターゲットには、環境に合わせて適宜設定ください。(ゲートウェイ、クライアントのIPアドレスなど)

Ping NP解決リソースは、以下のように設定します。
強制停止スクリプトは、以下のように設定します。
- 1.「クラスタのプロパティ」の「拡張」タブにて、「強制停止スクリプトを実行する」をチェックし、「スクリプト設定」をクリックします。
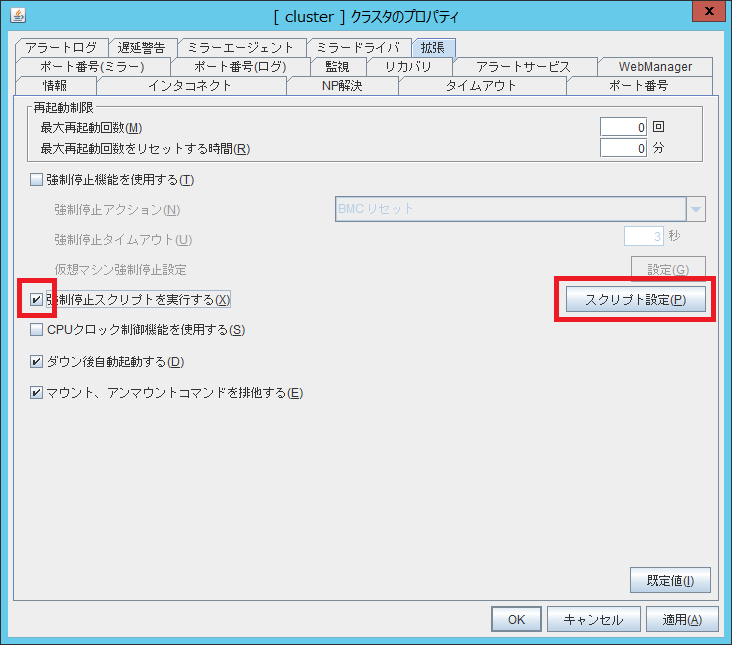
- 2.「スクリプトの編集」で「タイムアウト」を設定し、「編集」をクリックします。 今回は強制停止スクリプトでダウンしたサーバーの停止完了の待ち合わせを実施するため、タイムアウトを180秒に設定しています。
なお、CLUSTERPRO X 4.1以降では、[実行失敗時にグループのフェイルオーバを抑制する]の設定項目が追加されています。こちらの設定を有効化することで、強制停止スクリプトが失敗した場合に、フェイルオーバが抑制されるため、より確実に両系活性を防止することが可能です。

強制停止スクリプトの設定後に、OSの起動時間を調整します。
強制停止スクリプト実行中に対向サーバーでOS再起動などが実行された場合に、両系活性が発生することや、クラスター起動処理中に強制停止が実行されることを防止します。
OSの起動時間を以下となるように設定します。
OSの起動時間 >= 強制停止スクリプトのタイムアウト + ハートビートタイムアウト + ハートビートインターバル
OS起動時間の調整手順の詳細については、インストール&設定ガイドをご参照ください。
【参考】
CLUSTERPRO X 4.0 システム構築ガイド
- > Linux
- > インストール&設定ガイド
- > 第 1 章 システム構成を決定する
- > ハードウェア構成後の設定
- > 5. OS 起動時間を調整する (必須)
また、DISK方式によるNP解決を行う場合や共有ディスクを利用する場合はOS起動時間の計算について、別の観点での考慮が必要です。
詳細については、【2024年版】サービス起動遅延時間設定機能の紹介も併せて参照ください。
詳細については、
【2024年版】サービス起動遅延時間設定機能の紹介も併せて参照ください。 - ※リンク先の記事はCLUSTERPRO X 5.0から追加されたサービス起動遅延時間設定機能について解説していますが、サービス起動遅延時間の考え方とOS起動時間を調整する(遅延させる)考え方は同じものです。
また、リンク先の記事では強制停止スクリプトではなく、CLUSTERPRO X 5.0から追加された強制停止リソースを利用しています。リンク先の記事の「強制停止リソースの強制停止タイムアウト時間 + 強制停止リソースの停止完了待ち時間」の部分は本記事の「強制停止スクリプトのタイムアウト」と読み替えてください。
3. 起動したテキストエディタで、以下のスクリプトを入力します。
※以下のスクリプトはサンプルであり、動作を保証するものではありません。
※★部分の変数の値は環境に合わせて設定してください。
#! /bin/sh
#***********************************************
#* forcestop.sh *
#***********************************************
# AWS CLIの絶対パス
AWS_CLI=”/usr/local/bin/aws” ★ AWS CLIのパス
# 1ノード目の設定情報
SERVER1_NAME="server01" ★ サーバー1のホスト名
SERVER1_INSTANCE="i-11111111111111111" ★ サーバー1のインスタンスID
# 2ノード目の設定情報
SERVER2_NAME="server02" ★ サーバー2のホスト名
SERVER2_INSTANCE="i-22222222222222222" ★ サーバー2のインスタンスID
# インスタンス停止の最大試行回数
STOP_LOOP_MAX=2 ★ 停止処理の最大試行回数
# インスタンス状態確認の最大試行回数
CHECK_LOOP_MAX=120 ★ 確認処理の最大試行回数
echo "START"
echo "DOWN SERVER NAME : ${CLP_SERVER_DOWN}"
echo "LOCAL SERVER NAME: ${CLP_SERVER_LOCAL}"
if [ "${CLP_SERVER_DOWN}" = "${SERVER1_NAME}" ]; then
INSTANCE="${SERVER1_INSTANCE}"
elif [ "${CLP_SERVER_DOWN}" = "${SERVER2_NAME}" ]; then
INSTANCE=${SERVER2_INSTANCE}
else
echo "DOWN SERVER is not found."
echo "EXIT 1" exit 1
fi
# シャットダウン要求
STOP_LOOP_COUNT=0
while [ ${STOP_LOOP_COUNT} -lt ${STOP_LOOP_MAX} ]
do
${AWS_CLI} ec2 stop-instances --instance-ids ${INSTANCE} --force
ret=$?
if [ ${ret} -eq 0 ]; then
echo "succeeded to stop instance. (${INSTANCE})"
break
fi
echo "failed to stop instance. (${INSTANCE}, ret=${ret})"
sleep 1
let STOP_LOOP_COUNT=${STOP_LOOP_COUNT}+1
done
if [ ${ret} -ne 0 ]; then
echo "EXIT ${ret}"
exit ${ret}
fi
# サーバーダウン確認
# サーバーの停止を確認できなくても、CHECK_LOOP_MAXを超えた場合は停止が
# 完了したものとして待ち合わせ処理を終了する
CHECK_LOOP_COUNT=0
while [ ${CHECK_LOOP_COUNT} -lt ${CHECK_LOOP_MAX} ]
do
${AWS_CLI} ec2 describe-instances --instance-ids ${INSTANCE} --filters "Name=instance-state-name,Values=stopped" | grep ${INSTANCE}
if [ $? -eq 0 ]; then
echo "${INSTANCE} has been stopped."
break
fi
sleep 1
let CHECK_LOOP_COUNT=${CHECK_LOOP_COUNT}+1
done
echo "EXIT 0"
exit 0
4. 動作確認
強制停止スクリプトを実行する構成、また、実行しない構成で、ネットワークパーティション状態を起こして、HAクラスターの動作を確認します。
ネットワークパーティション状態を起こすため、ネットワークACLの設定によりHAクラスターを構成するサーバーのAZ間をまたぐ通信を全て遮断するようにしました。これにより、サーバー間のハートビートが途絶えますが、同じAZに属するNATインスタンスへのping通信は可能であるため、それぞれのサーバーが「相手サーバーで問題が発生した」と判断してフェールオーバーグループを起動しようとします。
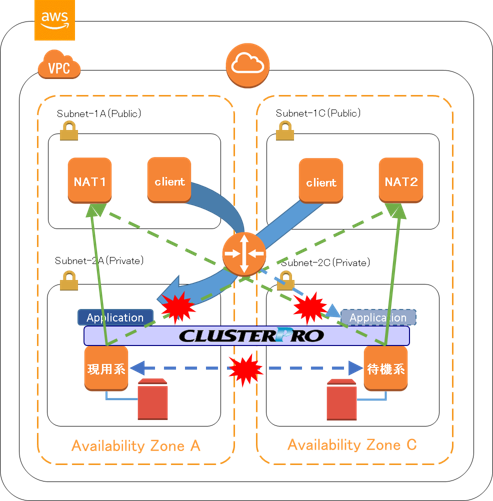
4.1 強制停止スクリプトを実行しない場合
強制停止スクリプトを実行しない場合、それぞれのサーバーがフェールオーバーグループを起動するため、両系活性状態となってしまいます。
それぞれのサーバーでHAクラスターの起動状態を確認すると以下となります。それぞれのサーバーでフェールオーバーグループが起動していることが確認できます。
[サーバー1のクラスターの起動状態]
サーバー1でフェールオーバーグループが起動しています。
[[root@server01 ~]# clpstat
======================== CLUSTER STATUS ===========================
Cluster : cluster
<server>
*server01 ........: Online ←server01は起動中
lankhb1 : Normal Kernel Mode LAN Heartbeat
pingnp1 : Normal ping resolution
server02 ........: Offline ←server02は停止中
lankhb1 : Unknown Kernel Mode LAN Heartbeat
pingnp1 : Unknown ping resolution
<group>
failover ........: Online
current : server01 ←server01でフェールオーバーグループが起動中
awsvip : Online
md : Online
<monitor>
awsvipw1 : Normal
mdnw1 : Error
mdw1 : Error
userw : Normal
=====================================================================
[root@server01 ~]#
[サーバー2のクラスターの起動状態]
サーバー2でフェールオーバーグループが起動しています。
[[root@server02 ~]# clpstat
======================== CLUSTER STATUS ===========================
Cluster : cluster
<server>
server01 ........: Offline ←server01は停止中
lankhb1 : Unknown Kernel Mode LAN Heartbeat
pingnp1 : Unknown ping resolution
*server02 ........: Online ←server02は起動中
lankhb1 : Normal Kernel Mode LAN Heartbeat
pingnp1 : Normal ping resolution
<group>
failover ........: Online
current : server02 ←server02でフェールオーバーグループが起動中
awsvip : Online
md : Online
<monitor>
awsvipw1 : Normal
mdnw1 : Error
mdw1 : Error
userw : Normal
=====================================================================
[root@server02 ~]#
4.2 強制停止スクリプトを実行する場合
強制停止スクリプトを実行する場合、待機系サーバーはフェールオーバーグループを起動する前に強制停止スクリプトを実行して現用系サーバーを停止させます。そのため、両系活性を防ぐことができます。
待機系サーバーが現用系サーバーのダウンを検出した後のsyslogの出力は以下のようになります。フェールオーバーグループの起動前に強制停止スクリプトを実行していることが確認できます。
Jun 14 05:05:24 server02 clusterpro: [E] <type: rm><event: 9> Detected an error in monitoring mdnw1. (31 : The network is disconnected.)
Jun 14 05:05:57 server02 clusterpro: [I] <type: nm><event: 4> Resource lankhb1 of server server01 has stopped.
Jun 14 05:05:57 server02 clusterpro: [I] <type: nm><event: 2> Server server01 has been stopped. ★現用系サーバーのダウンを検出
Jun 14 05:05:58 server02 clusterpro: [I] <type: rc><event: 411> Script for forced stop has started. ★強制停止スクリプトを実行開始
Jun 14 05:07:50 server02 clusterpro: [I] <type: rc><event: 412> Script for forced stop has completed. ★強制停止スクリプトの実行完了
Jun 14 05:07:50 server02 clusterpro: [I] <type: rc><event: 60> Failover group failover has started. ★フェールオーバーグループの起動を開始
Jun 14 05:07:50 server02 clusterpro: [I] <type: rc><event: 10> Activating group failover has started.
Jun 14 05:07:50 server02 clusterpro: [I] <type: rc><event: 30> Activating awsvip resource has started.
フェールオーバー完了後、現用系サーバーのEC2インスタンスの起動状態を確認するとstoppedとなっており、現用系インスタンスが停止していることを確認できます。
[root@server02 ~]# aws ec2 describe-instances --instance-ids i-11111111111111111 --query 'Reservations[0].Instances[0].[InstanceId, State.Name]'
[
" i-11111111111111111",
"stopped"
]
[root@server02 ~]#
さいごに
今回は強制停止スクリプトを利用したHAクラスターの構築手順をご紹介しました。
AWS上でネットワークパーティション発生時に両系活性をより確実に防止することができますので、強制停止スクリプトの利用をご検討ください。
お問い合わせ
本記事に関するお問い合わせは、お問い合わせ窓口までお問い合わせください。
お問い合わせ窓口までお問い合わせください。- ※本記事で紹介しているスクリプトの内容についてのお問い合わせ、および、お客様環境に合わせたカスタマイズにつきましてはCLUSTERPRO導入支援サービスにて承っておりますので、上記窓口の"ご購入前のお問い合わせ"フォームまでお問い合わせください。
