Japan
サイト内の現在位置
社会価値の創造を加速する
NECのAIスーパーコンピュータ


更新日:2023年7月24日
1. AI研究用スーパーコンピュータの概要
NECは、2023年3月に国内企業で最大規模(注1)の580PFLOPS超となるシステムの稼働を開始しました。NECの数百名の AI研究者が利用を開始しており、国内最高峰のAIに特化した研究開発環境による、より高度な先進AIの迅速な開発に役立てています。将来的には、お客様やパートナーとの共創により先進的な社会価値を産み出すAI研究のセンター・オブ・エクセレンスの実現を目指します。
2. AI研究用スーパーコンピュータのハードウェア構成
深層学習において計算機資源は競争力の源泉です。NECは、国内企業で最大規模のAI研究用スーパーコンピュータを自社のAI研究者数百名へ提供し、AIの研究開発を大幅に強化します。
2023年3月に稼働するAI研究用スーパーコンピュータは、コンピューティングとしてはエンタープライズGPUを928基、ネットワークには200GbEの超高速イーサネットスイッチ、ストレージは16PB超の大規模分散ストレージを備える、国内企業で最大規模のAIの研究開発環境です。
表 1 AI研究用スーパーコンピュータのシステム構成概要
| 分類 | 機種概要 | 規模 |
|---|---|---|
| コンピューティング | NVIDIA A100 80GB Tensor コア GPUをノード当たり8基搭載するGPUサーバーを96台 | 928GPU (580PFLOPS) |
| ネットワーク | 高速イーサネットスイッチNVIDIA Spectrum SN3700(200GbE) | 数千本の光ケーブルを接続 |
| ストレージ | DDN社の高速ストレージアプライアンスES400NVX | 16PB |
2.1. コンピューティングのスペック
GPUには、NVIDIA社の最新のAmpereアーキテクチャを採用した NVIDIA A100 80GB Tensor コアGPUを採用しています。本GPUは、TensorFloat-32(TF32)と呼ばれる新しい行列演算のモードをサポートしており、FP32と比較して多くのケースで精度劣化なく高速に学習することが可能です。また、GPU 1基あたり12本のNVLink接続をサポートし、合計帯域幅は600GB/secにも及ぶことから、高速なマルチGPUでの学習が可能です。NECでは、生体認証・画像認識・音声認識・データ分析・ロボット制御技術等の多種多様なAIの学習を行っており、NVIDIA社の本GPUは、学習を圧倒的に高速化できるその高速性とどのようなニューラルネットワークでも学習できるGPUメモリ量の多さの観点から、多様な先進AIを迅速に創出するのに最適であるため採用をしています。
また、GPUサーバーには、このNVIDIA A100 80GB Tensor コアGPUをサーバーあたり8基搭載しています。サーバーのフォームファクターにはSupermicro社の SYS-420GP-TNARを採用し、CPU/ストレージ/メモリの構成やBIOSの設定等をカスタマイズすることで、大規模な分散学習用途に最適化しています。

表 2 GPUサーバーのスペック
| 分類 | スペック |
|---|---|
| CPU | Intel Xeon Platinum 8358 (32core, 2.6GHz) x 2 |
| Memory | 1024GB |
| GPU | NVIDIA A100 80GB Tensor コア GPU x 8 |
| Local Storage | 1.9TB NVMe SSD + 7.6TB NVMe SSD x 4 |
| Interconnect (Servers) | NVIDIA ConnectX-6 (200Gb/s Ethernet) Single-Port x 5 |
| Interconnect (Storage) | NVIDIA ConnectX-6 (200Gb/s Ethernet) Dual-Port x 1 |
2.2. ネットワークのスペック
分散深層学習では、多量のパラメータをGPU間で通信する必要があることから、低レイテンシ・高バンド幅での通信が必要となります。そのため、200Gbpsの超高速イーサネットをサポートするNVIDIA社の高速イーサネットスイッチNVIDIA Spectrum SN3700を採用しています。
全てのサーバー間は、サーバーに搭載された低レイテンシのインターコネクトNVIDIA ConnectX-6と200GbEの高速イーサネットスイッチNVIDIA Spectrum SN3700で接続されています。ネットワーク構成にはSpine-Leafアーキテクチャを採用し、RoCEv2 (RDMA over Converged Ethernet)を用いて超高速・低レイテンシでの通信を行っているため、高速な分散学習を行えます。
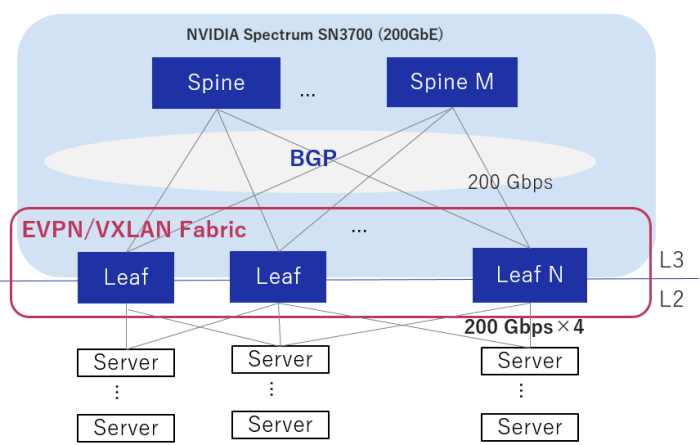
表 3 スイッチのスペック
| 分類 | スペック |
|---|---|
| Switch | NVIDIA Spectrum SN3700 (200Gbps Ethernet Switch) |
2.3. ストレージのスペック
ストレージには、DDN (データダイレクト・ネットワークス)社の並列ファイルシステムEXAScalerを搭載したストレージアプライアンスES400NVXを採用し、16PB超の大規模ストレージを構成しています。多数のNVMe SSDで構成される高速領域は、最高400GB/秒のシーケンシャル読み取り性能、最高320GB/秒のシーケンシャル書き込み性能にも及ぶ高性能ストレージです。
本ストレージは全GPUサーバーからのアクセスが可能で、数千万枚の画像等のデータセットでも高速にGPUサーバーから取得することができるため、高速な分散学習が可能です。NECでは、映像・画像・音声・テキスト等の多種多様なデータでAIの学習を行っており、様々なワークロードに耐えうる高性能ストレージが必要であることから、DDN社のストレージを採用しています。

表 4 ストレージのスペック
| 分類 | 機種 | 容量 |
|---|---|---|
| SSD | ES400NVX | 約 1.1 PB |
| HDD | ES400NVX + SS9012 | 約 14.6 PB |
3. AI研究用スーパーコンピュータのソフトウェア構成
NECのAI研究者が、複雑な環境を構築することなくAIの学習を行えるようにするため、Kubernetesをソフトウェアの中核に据えた分散学習環境を独自開発しています。それにより、研究者は、最新の深層学習フレームワークのコンテナを用いて、分散学習を行うことができます。また、Kubernetesのジョブスケジューラを独自開発し、ネットワークトポロジ等の物理構成に最適化し効率的にスケジューリングを行うことで、多数の研究者が利用できるようにしています。更に、MPI/NCCL等の通信ライブラリやOS等は、NEC独自の最適化を行うことで、RoCEv2を用いたGPUDirect RDMAで高速な分散学習を行うことが可能です。
サーバーのアーキテクチャやSpine-Leaf型のネットワーク構成等も含めたハードウェアアーキテクチャと先進的なソフトウェア群を密結合することで、高性能かつ利便性の高い先進的な深層学習環境を実現しています。Computer ArchitectureとSoftware Architectureを高いレベルで融合することでしか実現できない、世界でも有数のAI研究用スーパーコンピュータとなっています。
表 5 AIスーパーコンピュータのソフトウェアスタック
| 種別 | 説明 | 備考 |
|---|---|---|
| Operating System | Ubuntu 20.04 LTS Server | 深層学習でよく利用されており、研究者が馴染みやすいUbuntuを採用しています。 |
| Container | Kubernetes | デファクトのコンテナ技術を採用し、先端の深層学習環境を利用することが可能です。 |
| Job Scheduler | Kubernetesのスケジューラを拡張し開発 | ラック配置・NWトポロジ・HWトポロジ等に基づいた最適化を行うことで、多数のジョブを安定的かつ効率的に処理することが可能です。 |
| Communication Library | NCCL, OpenMPI | 多数のGPUを用いた分散学習を高速に行えるよう、NECで独自のチューニング・最適化をしています。 |
| Deep Learning | PyTorch, TensorFlow2 等 | 最新の深層学習フレームワークを、内部環境に合わせてコンテナを開発し、提供しています。 |
4. お知らせ
 研究開発 Linkedin
研究開発 Linkedin- 2023年3月22日 NVIDIA GTC 2023:
How to Design an AI Supercomputer for Fast Distributed Training, and its Use Cases - 2023年3月20日
NEC、国内企業で最大規模となるAI研究用スーパーコンピュータを稼働開始
~お客様・パートナーとの共創で先進的な社会価値を創出~  2022年12月9日
2022年12月9日
NECのAIスーパーコンピュータを支えるDDN Lustreを活用した大規模ストレージシステム- 2022年8月22日 AIsmiley
【特集インタビュー】NECが構築を開始した国内企業で最大規模のAI研究用スーパーコンピュータ - 2022年7月28日 You Tube
社会価値の創造を加速するNECのAI研究用スーパーコンピュータ~計算能力はAI時代の競争力の源泉~
5.採用の募集
NECのAI研究用スーパーコンピュータの技術開発責任者の北野 貴稔です。私は、デジタルテクノロジー開発研究所にて、このAIスーパーコンピュータの企画・設計・開発・運用を統括しています。本AIスーパーコンピュータは、既にNECの数百名のAI研究者が利用しており、日々新たな先進AIが開発され続けています。世界でもトップレベルのNECの先進AIをさらに強化し、NECの未来を共に作っていって頂ける方を募集していますので、是非NECへの入社をご検討頂けますと幸いです。
特に、国内企業で最大規模のAI研究用スーパーコンピュータの開発・運用に参加しイノベーションを生み出したい
の方を募集しています。また、日本最高峰のAIの研究開発環境を使うことで、新たな社会価値を創造したいAI研究者・エンジニアの方も募集しています。
公開日:2022年5月17日
お問い合わせ