Japan
サイト内の現在位置
ペネトレーションテスターの視点で見る「AIセーフティに関するレッドチーミング手法ガイド」
NECセキュリティブログ2024年12月20日
NECサイバーセキュリティ戦略統括部セキュリティ技術センターの榊です。近年AI技術の進化と普及が進む中で、AIシステムに対するサイバー攻撃のリスクも高まっています。特に、大規模言語モデル(LLM)に対する攻撃は、データ窃取から予測の改ざん、システムの誤作動まで多岐にわたります。私のチームでは脆弱性診断やペネトレーションテストを実施していますが、診断対象システムにLLMが含まれるケースも出てきており、診断方法の検討に苦戦することがあります。このような状況において、IPAのAIセーフティ・インスティテュート(AISI)が公開した「AIセーフティに関するレッドチーミング手法ガイド」 [1]は、AIシステムに対して脆弱性診断やペネトレーションテストを実施する際の指針となり得ます。本ブログでは、このガイドをペネトレーションテスターの視点から解説します。
[1]は、AIシステムに対して脆弱性診断やペネトレーションテストを実施する際の指針となり得ます。本ブログでは、このガイドをペネトレーションテスターの視点から解説します。
目次
「AIセーフティに関するレッドチーミング手法ガイド」の全体像
「AIセーフティに関するレッドチーミング手法ガイド」は、構築したAIシステムのリスクを攻撃者の視点で評価する際の考慮事項を示すものです。本ガイドは、レッドチーミングの基本概念(目的や効果、種類等)から実践手法まで、レッドチーミングの全プロセスを具体的に解説しています。なお本ガイド内で扱われている「レッドチーミング」という単語は「攻撃者がどのようにAIシステムを攻撃するかの観点で、AIセーフティへの対応体制及び対策の有効性を確認する評価手法。」と説明されています[1]。
「AIセーフティに関するレッドチーミング手法ガイド」の各章の紹介
1章. はじめに
この章では、ガイドの目的や背景、想定読者について説明しています。特徴的に感じたのは、本ガイドがAIシステムの中でもLLMを構成要素とするものを対象としている点や、AISIが公開している「AIセーフティに関する評価観点ガイド」[2]で、「AIセーフティにおける重要要素」として紹介されている「人間中心」、「安全性」、「公平性」、「プライバシー保護」、「セキュリティ確保」、「透明性」の観点を取り入れている点です。また、本ガイドはAIセーフティの評価手法の一部であり、全体的な考え方を知りたいときは「AIセーフティに関する評価観点ガイド」が参考になります。個人的に「いいなぁ」と感じたのは「1.2 本書で使用する用語」です。レッドチーミングやAIのリスク評価に関連する基本的な用語の解説が記載されており、AIシステムのリスク評価を始める際の知識レベル合わせに大変有用だと感じました。
2章. レッドチーミングについて
この章では、レッドチーミングを実施する目的、効果、種類、注意点を解説しています。「実運用環境に対する悪意をもったエンドユーザーなどの攻撃者からの攻撃耐性を評価することができる」といった記載や「2.4レッドチーミングの種類」に記載されているブラック/ホワイト/グレーボックステストの分類などを読む限り、一般的なペネトレーションテストと同様の観点で実施することが記載されているように感じました。一方、「2.5 AIのレッドチーミングに固有の注意点」の後半に記載されている「再現性の欠如」については、一般的なペネトレーションテストと異なる点だと思いました。脆弱性診断やペネトレーションテストでは、診断結果を報告する際に再現手順を提示するのがセオリーです。ただしLLMは同じ入力に対して異なる出力をすることがあります。そのためAIレッドチーミングを実施する際は、攻撃の成功基準とともに実行回数も設定する必要があります。具体的な実行回数の推奨値は本ガイドに記載されていなかったので、AIシステムの重要度や評価期間に応じて適宜調整する必要がありそうです。
3章. LLMシステムへの代表的な攻撃手法
プロンプトインジェクションをはじめとする、LLMに対する代表的な攻撃手法が解説されている章です。保護すべき資産として「訓練データ」、「モデル」、「クエリ」、「ソースコード」、「リソース」、そして「LLMシステム」全体を取り上げ、それぞれに対する攻撃が例示されています。レッドチーミングを実施する際、診断対象のLLMに対して「何の評価を目的に何をするか」を策定する際に便利な情報がそろっています。プロンプトインジェクションやプロンプトリーキング、ポイズニング攻撃等の攻撃手法について、図を用いてわかりやすく解説されています。
4章. 実施体制と役割
AIレッドチーミングを実施する際の体制や役割について解説されている章です。ステークホルダーは以下の通り分類されています。
| レッドチーム | レッドチーミング全体を取りまとめる役割を担う。組織内の要員やサードパーティが想定される。 |
| 攻撃計画・実施者 | レッドチーミングの計画、実施、報告を実施する役割を担う。AIセーフティに関する高度な専門性(攻撃手法・事例、防御策に関する知見)が求められる。 |
| AIシステムに関連する有識者 | 対象のAIシステムに関連する知見、スキルを持つ有識者として、レッドチーミングの計画や報告に関して専門家の観点から検討・考察を行う役割として、レッドチームに参画する。 |
| AIシステムに関連する有識者 | 対象のAIシステムに関連する知見、スキルを持つ有識者として、レッドチーミングの計画や報告に関して専門家の観点から検討・考察を行う役割として、レッドチームに参画する。 |
| 対象AIシステムの開発・提供管理者 | レッドチーミングの対象となるシステムの開発や提供に関連し、レッドチームに対象システムの情報を提供する役割を担う。またレッドチームが指摘した脆弱性に対する改善計画の策定と実施の実行責任を負う。 |
| その他の関連ステークホルダー | 経営層もしくはこれに準ずる責任を持つもの |
とりわけ難しいのは、「攻撃計画・実施者」もAIセーフティに関する高度な専門性が求められる点だと私は感じました。一般的なペネトレーションテストのスキルを習熟するだけでも難易度が高いうえ、AIセーフティについても習熟する必要があります。これを一人で実現するのはなかなか難しいので、実際は一般的なペネトレーションテストの専門家と、AIセーフティの専門家を別々にアサインすることになると考えます。
5章. 実施時期及び実施工程
レッドチーミングを実施する際のプロセスが詳細に解説されている章です。リリース/運用開始前の実施を基本とすることや、リリース/運用開始後も定期的に実施すること等、全体通して一般的な脆弱性診断・ペネトレーションテストと同様のプロセスに見えました。LLMに特徴的な点としては、リリース後も定期的にレッドチーミングを実施することを推奨する理由です。一般的な脆弱性診断やペネトレーションテストにおいては、新規に発見された脆弱性や運用後の設定変更等を理由として定期的に実施することを推奨することが多い一方、LLMの場合はオンライン学習によるモデルの再学習のような、LLM固有の理由が挙げられています。
6章. 実施計画の策定と実施準備
章タイトルに記載の通り、レッドチーミングの実施計画の策定と実施準備を解説している章です。全体通して、一般的な脆弱性診断やペネトレーションテストと同様のプロセスを取っているように感じました。一方で「6.3.2.1 LLMの利用形態」や「6.3.2.3 導入済みの防御機構等」では、診断対象範囲や診断のアプローチを検討する際の情報整理に有用な分類が紹介されており、計画策定初期の情報収集フェーズで活用できそうです。
7章. 攻撃計画・実施
実際に攻撃を実施するフェーズについて解説されている章です。システム構成、AIセーフティの評価観点、保護すべき情報資産、システムの利用形態をもとにシナリオを作成し、実行フェーズに移っていきます。本ガイドに特徴的な点は、攻撃シナリオ作成の観点整理や、シナリオ例が提示されているところです。以下のような表形式で、利用形態に対する攻撃観点整理の例が掲載されています[1]。
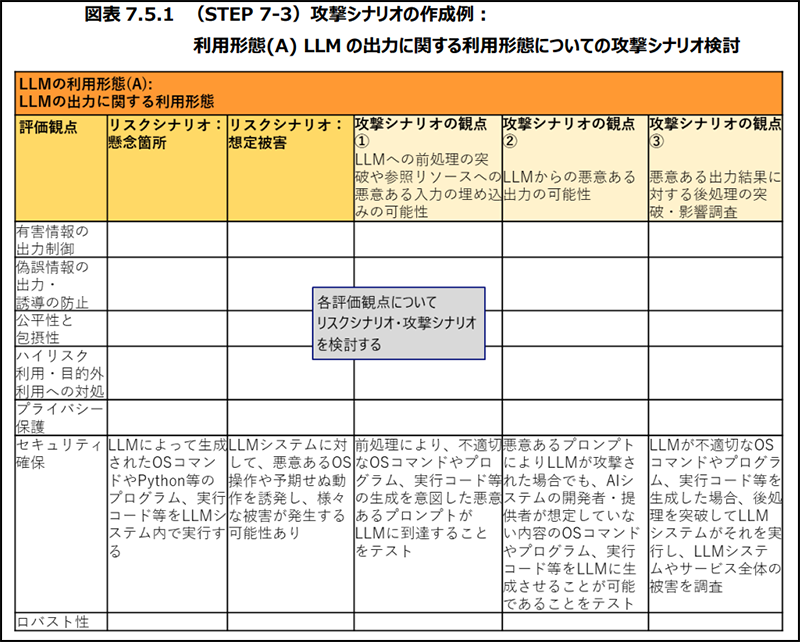
これらの観点ごとに作成したシナリオの例も掲載されています[1]。このあたりの情報は、実務者にとって非常に有益なツールになると感じました。
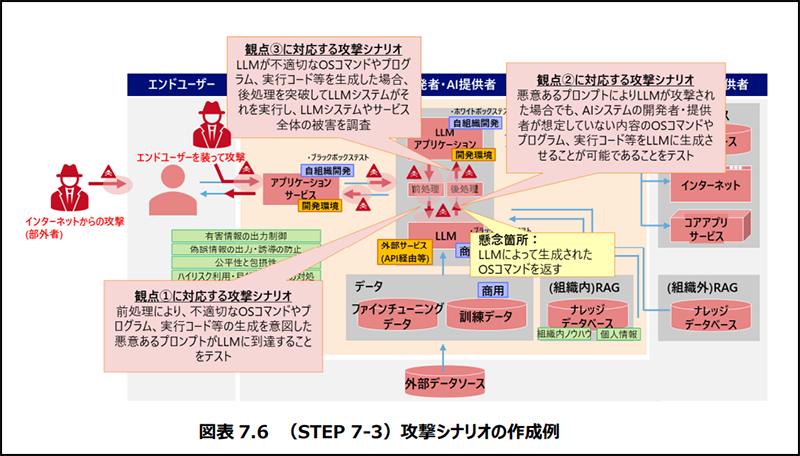
具体的に攻撃シナリオを実施する際の勘所としては、「7.3.4 ツール等による支援」が参考になります。自動化ツールによるレッドチーミング、手動によるレッドチーミング、AIエージェントを用いたレッドチーミングの3通りが示されています。「自動化ツールによるレッドチーミング」に関しては、p.55の「A.1 ツール一覧」に代表的なツールが掲載されているため参考になります。
また、攻撃シナリオの実施プロセスを3つのステップに分けている点も特徴的に感じました。まずはプロンプト単体での攻撃を実施し、その結果をもとにカスタマイズした攻撃シグネチャを作成して、最後にLLMシステム全体に対する攻撃をする、というステップです。プロンプト単体での攻撃においては自動化ツールが有用ですが、必要十分な診断をするためには単にツールを回して終わりではなく、ツールの診断結果を踏まえて(検出された脆弱性を組み合わせて)その後の攻撃シナリオを策定、実行することが重要である点が説明されています。
8章. 結果の取りまとめと改善計画の策定
実施した攻撃の結果をもとに報告書を作成し、改善計画を策定・実施する手順について解説されている章です。特徴的なのは、2章でも触れた「再現性の欠如」を考慮する必要がある点です。この点に対するアプローチとしては、6.3.2.3節で紹介されている防御機構を活用することが有効とされています。LLMへの入力、LLM内の処理、LLMからの出力それぞれにおいて防御機構を導入することと、入出力のユーザーフィードバックによる強化学習の4点です。どれか一つを採用するというより、複数の対策を組み合わせることで多層的に防御することが必要とされています。
まとめ
本ブログでは「AIセーフティに関するレッドチーミング手法ガイド」を、ペネトレーションテスターの目線で解説してみました。本ガイドは抽象的な概論だけでなく、具体的かつ実践的な手法が説明されているため非常に有用だと感じました。LLMに対するリスク評価に苦慮されている方は、まずこのガイドを読んでみることをお勧めします。現状の整理や今後の動き方の策定に一役買ってくれることと思います。
参考文献
- [1]AIセーフティに関するレッドチーミング手法ガイド(第1.00版)| IPA 独立行政法人情報処理推進機構https://www.ipa.go.jp/digital/ai/begoj90000004szb-att/ai_safety_rt_v1.00_ja.pdf
- [2]AIセーフティに関する評価観点ガイド(第1.01版)| AISI Japanhttps://aisi.go.jp/assets/pdf/ai_safety_eval_v1.01_ja.pdf
執筆者プロフィール
榊 龍太郎(さかき りゅうたろう)
セキュリティ技術センター リスクハンティング・アナリシスグループ
ペネトレーションテスト、脆弱性診断を通じたセキュリティ実装支援、インシデント対応、その他社内外向けのセキュリティ人材育成施策に従事。
2019年6月にIPA 産業サイバーセキュリティセンター中核人材育成プログラムを修了。
CISSP/CCSP/CISA/CISM/ISACA認定トレーナー/情報処理安全確保支援士(RISS) /GIAC GPEN/CEH/CCSE/AWS CLF・SAA・SOA・DVA・SAP・DOP・SCS・DAS・MLS・DBS・PASを保持。
趣味は家族サービス。

執筆者の他の記事を読む
アクセスランキング