
Japan
サイト内の現在位置
「世界モデル」がさらに進化
環境に適応して精密な動きをするロボットAI技術
NECの最先端技術 2024年2月19日

2023年3月、NECは最適な行動を自分で選択できる革新的なロボット動作の学習技術を発表しました。この技術の核となっていた技術が「世界モデル」です。これはAIを飛躍的に進化させ得るとして近年注目を浴びる技術で、AIがロボットや周囲の環境(世界)を学習する枠組みのことを指します。このモデルをAIに適用することで、AIは実世界で何が起こるかを予測、シミュレーションすることが可能になり、ロボットは自律的に動作を最適化できるようになります。
今回、NECではこの世界モデルを使ったロボット制御をさらに発展させることに成功。より柔軟で精緻な動きが可能になり、より幅広いシーンに適用することができるようになりました。具体的にどのようなことができるようになり、どのようにこれを実現したのか。詳細について、研究者に話を聞きました。
画像認識との連携で、さらに高精度な予測と動作が可能に

主任研究員
大山 博之
― まず、改めて世界モデルとは何か教えてください。
大山:世界モデルというのは、動作の結果や実世界の構造を予測・推定することができる技術です。実世界の構造というのは、例えば壁の陰に少し何か見えていたら裏に何かモノがあると予測するというようなことですね。私たち人間は普段何か行動するときに、そういった予測や推論をしながら動作しているものです。そういった人間の無意識の常識のようなものをロボットに導入していこうというのが、私たちNECが取り組んでいる試みです。これにより、ロボットは学習していない初見の環境でも適応的に動けるようになります。
― 今回の技術では、どのような点が進化したのでしょうか?
大山:より高度な予測のもとで複雑かつ多様な動きができるようになっています。前回の技術を発表後、多くのお客様からお問い合わせをいただきましたが、なかでも多かったのが「“詰め込み”はできるのか」「モノが雑然と置かれた状況にも対応できるのか」というものでした。“詰め込み”は箱の中にきっちりとモノを詰め込む作業のことですね。しかし、残念ながら前回の発表時では、まだ詰め込みやモノが雑然と置かれた状態での対応は難しかったのです。というのも、「押す」「引く」という動作ができなかったからでした。ロボットアームでは、正確に所望の位置まで押したり引いたりするということが、実は非常に難しいのです。
坂井:アームがモノの中心をとらえないとぐるっと回ってしまいますし、重心を把握しなければ倒れてしまいます。私たち人間は指の感覚を感じながら何気なくコントロールしてこなしてしまいますが、実はロボットで実行しようとすると、非常に難易度の高い動作なのです。
大山:そうですね。なので、今回は白石さんや坂井さんをはじめとした画像認識を専門とするチームと連携して研究を行いました。私たちのチームはロボットの制御を専門としていますが、それだけでは実現できることに限界があるとわかっていたので、早くから連携を進めていたのです。AI技術には、大きく分けて「可視化」「解析」「制御」という3段階がありますが、可視化~解析の部分と連携することで世界モデルをさらに深化させていきました。この結果、今回の技術では世界モデルの予測の精度が大きく向上しています。ロボットアームで一般的なピック&プレイスの動作に加え、「押す」「引く」といった繊細な動作もできるようにもなりました。詰め込み作業はもちろん、ロボット用に整理された環境ではない場所でもすぐに導入が可能です。例えばロボットが作業しやすいように、モノどうしの間隔を空けたり、特別な装置や設備を用意したりという準備は不要です。もちろん、ロボットに細かくプログラミングをして指示するティーチング作業も必要ありません。ロボットを現場に置けば、自ら環境に適応することができます。さらに、形状の異なるモノが加わったり物品が増えたりして環境が多少変化したとしても、うまく対応することが可能です。
世界モデルによるハンドリング作業自動化
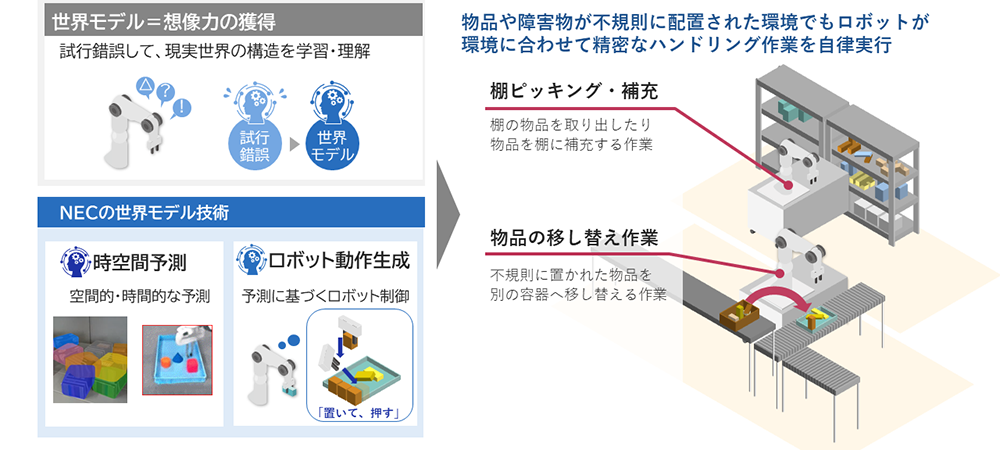
「イメージトレーニング」によって、未経験の事象にも対応可能に

研究員
坂井 亮介
― 具体的には、どのような工夫をしてこの技術を実現したのでしょうか?
白石:制御技術に加え、目の前の状況をより正しく理解するために画像認識をうまく連携させたことが大きいです。普段私たちが研究している一般的な認識技術は、私たち「人間」に向けて事前に与えられた正解どおりに結果を返すことを目的としています。つまり、これまでの技術は、人がいる、モノが置いてあるということを枠や座標などの人間がわかるかたちで示すことが求められていました。しかし、今回はロボットが動くための情報を渡さなければなりません。モノを認識後、今回の技術ではロボットアームがそれを触ったらどうなるか予測するのですが、その予測結果をロボット制御にうまく使えるようなかたちに料理して渡すところが、一つの大きな技術課題であり、これまでとは違うレイヤーのチャレンジでした。
坂井:ロボット動作によってモノを正確にコントロールするためには、認識した実環境の多くの情報を正確にロボットに渡す必要があります。これを実現するために、初めは座標やサイズなどの具体的な数値としてロボットへ渡すということを考えていたのですが、当然のことながら世の中にはさまざまな形状のモノが存在していますから、全てを数値化することは不可能です。そこで、うまく画像をエンコードして特徴量のようなかたちでロボットの制御に上手く活用するということを実現していきました。
大山:制御チームとしても、どういった情報をもらえれば制御できるかであるとか、動作の学習がしやすいかというところがキーになってくるので、そういった情報を共有しつつ緊密に議論して進めていきました。
白石:それに加えて、陰に隠れているモノの認識や正確な予測や実現するために大量のデータを学習させていったことも重要な点です。
坂井:予測精度を上げるためには、どう接触したらどう動くということをAIに教えなくてはいけないので、さまざまなぶつかり方や当たり方、モノの形状などの大量のパターンのデータが必要になります。そこには実機を使ってさまざまな動きをさせながら大量のデータを取得するという地味で泥臭い作業が発生します。ただし、それだけではなく、独自にシミュレーターを構築して併用することで多様なデータを学習させるようなデータ増強の工夫も行っており、これらの積み重ねが今回の技術を実現させています。
白石:これは、まさに人が何か新しいものを学ぼうとするときのプロセスと同じです。まずは成功例と失敗例をひたすら見て学習していく。すると、自分の頭の中にモデルができるので、「こうしたらこうなるだろう」ということを想像できるようになり、頭の中でどういう行動をすれば実現可能かということを脳内でイメージトレーニングできるようになります。これがまさしく世界モデルです。坂井さんが説明してくれた工夫などで良いモデルが作れればこそ、正確な想像ができますし、そのものズバリで学習したことがないモノや事態に対面しても、学習したデータから汎化して対応できるようになっています。
世界モデルによる時空間予測
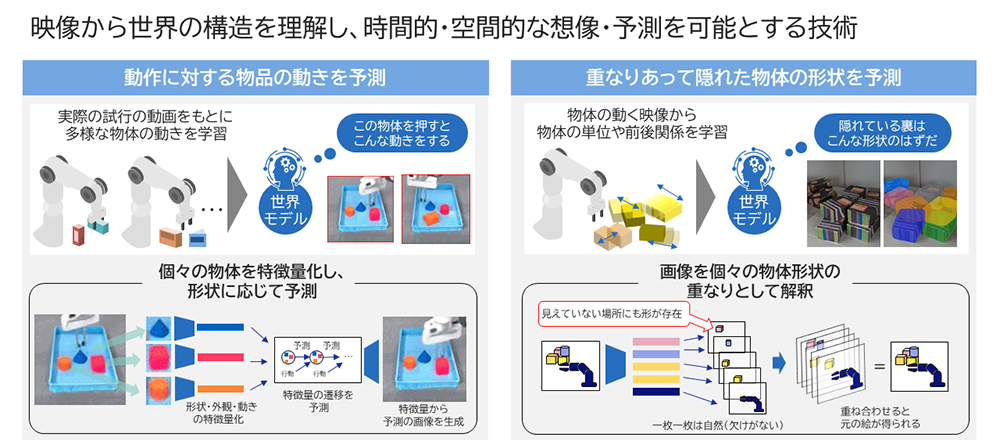
大山:こうして出力してもらった情報を制御側でも効率的に活用しています。最適な動作の順番や動きをAIが自分で決めることができるのは前回の技術から変わりませんが、今回はその計算をさらに高速化することに成功しました。具体的には生成AIの一種である拡散モデルという技術を活用して軌道を生成しています。また、拡散モデルで生成された軌道の精度を高めるために、先ほど述べたタスクの順番を自動最適化する技術を用いて上手く補正することで、効率的な軌道生成を実現しました。
世界モデルによるロボット動作生成
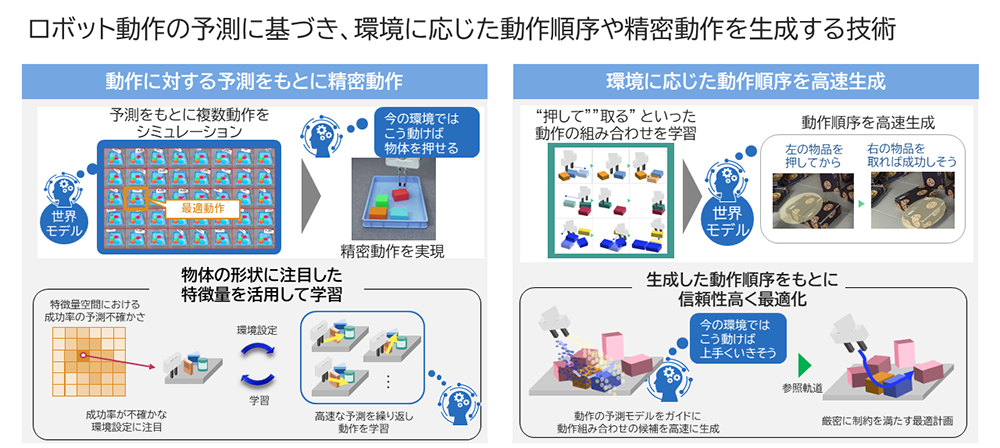
隠れた部分を想像することで、より効率的な制御が可能に

主任研究員
白石 壮馬
― 陰に隠れたモノを認識できるようになるとおっしゃいましたが、そのメリットは何なのでしょうか?
白石:「隠れた部分を想像する」という空間的な予測能力は、世界モデルにおける重要な機能の一つです。というのも、実環境においては物品同士が重なっていて、カメラから全体が見えない場合も多々あるからです。現場で適応的に制御を行うためには、不可欠な機能と言えるでしょう。私たちが開発する世界モデル技術では、事前に物体を動かす映像を大量に観測し、物体の境界や重なりを解釈することによって、重なりの裏の形状を推定できるようになります。人間は隠れた形状を無意識に想像して自然に物をとることができますが、本技術の活用によってロボットにも同じことができるようになります。
大山:隠れた部分の形状までロボットが考慮することができるようになると、「この裏に大きな物体があるから、まず手前の物体を一時的に動かそう」というように、より適切な計画も立てられるようになります。また、これまでは、隠れていた物品を新たに見つけるたびに再度計画を行うなどの非効率な動きが発生していましたが、本技術によってこれを改善できると考えています。
閉じた世界から、より広い世界に汎化させる

― 世界モデルを活用したプロジェクトは、今後も進めていくのでしょうか。
白石:はい。そのつもりです。私たち画像認識チームの観点からすると、今回の研究を通じて世界モデルは画像認識そのものの精度向上にもつながり得ると感じたので、そういったアプローチからも取り組んでみたいと考えています。より具体的に言うと、世界モデルを使って実世界の常識も考慮することで、非常識な認識結果を弾くことができるようになる可能性があるということです。例えば人が車の奥に隠れていて、顔だけが見えているときに「顔がある」と認識することと「人がいる」と認識できることは全く異なります。これまでの画像認識ではただ「顔がある(=顔が浮いている)」とだけ認識していましたが、それは現実的ではありません。顔の下には体が隠れていて、人がそこにいるのだというように常識に沿って判断できるようになることで、画像認識のレベルや実用性をさらに向上させることができると考えています。
坂井:私がいま興味を持っているのは世界モデルの汎化です。現在は必要なタスクに応じてデータを集めて学習させるということをしていますが、世界モデルがもう少し広い世界を想像できるようになると、こうした学習の手間も削減できるのではないかと考えています。
白石:そうですね。今まさに坂井さんや私たちのチームでは世界モデルをオンラインで更新していくという試みをしています。これが実現できれば、さまざまな現場での導入がさらに容易になります。例えば、ある倉庫で良いモデルができたとしても、それを他の現場に持っていくと、摩擦が強いだとか油で滑るなどの大きな環境変化によって予測がズレてしまうリスクがあります。こういった場合、従来の方法では再び学習をし直す手間が生じていました。しかし、オンラインで世界モデルを更新できれば、データを蓄積することで現場導入をさらに円滑化することができるはずです。データのセキュリティ確保は大前提ですが、こういった取り組みも進めているところです。
大山:LLM(Large Language Model:大規模言語モデル)やVLM(Vision-Language Model)との連携も進めていきたいと考えているところです。世界モデルとLLMやVLMは共通部分も多く、連携させることで生まれる将来性は大きいと感じています。特に環境の認識や理解という面では非常に有用でしょう。それこそモデルの汎化にとっても効果的だと考えていますし、ゆくゆくはロボットアームだけでなく他のロボットやさまざまなシステムにも適用できるような基盤モデルにまで発展させて、先ほど白石さんが言ったオンライン化と組み合わせていけたらという未来も描いています。
また、私たち制御側からするとロボット同士が協調して作業できる大規模システムの構築も取り組みたいと考えています。1台のロボット単体で作業するのではなく、複数のロボットが協調できればより作業を効率化できますから。ただ一方で、ロボット同士の協調だけでなく、人との協調という点も重視しています。ロボットが周囲の人の動きを認識して、うまく協力しながら作業できる現場の実現は、これから取り組んでいきたいテーマです。そういった面でも画像認識技術は引き続き重要になってきますので、引き続きチームの垣根を超えて連携しながらプロジェクトを進めて行きたいと考えています。


世界モデルを応用したロボット動作の学習技術は、限られたデータから背後にある要因を推測し、行動によって世界がどう変わるかを予測する世界モデルをロボティクスに応用する技術です。ロボットに逐一細かなルールを覚え込ませる必要がないので、ロボットは学習したデータやセンシングしたデータから最適な行動を判断して、自律的に動作できるようになります。
2023年3月にNECは既にロボット制御側の技術として、動作実行後の成否を予測するモデルを学習する技術と、精度向上に貢献するデータを選別して効率的に学習する技術を発表していました。今回の発表ではこれに画像認識を上手く連携させることで、予測精度の向上とより精密な動作を実現させています。世界モデルを応用したロボット制御の研究は近年注目を集めつつありますが、実世界に適用できるレベルまで高精度な予測を実現し、実際にロボットをアクチュエーションできているものは世界でも稀有な研究成果です。
- ※本ページに掲載されている内容は、公開時の情報です。
お問い合わせ