
Japan
サイト内の現在位置
130億パラメータで世界トップクラスの日本語性能を有する軽量なLLMを開発
記者会見資料
130憶パラメータで世界トップクラスの日本語性能を有する軽量な日本語大規模言語モデル(Large Language Model、以下LLM)の開発について説明します。

NECのLLMの開発は完了し、社内でも利用を開始しています。
このLLMは、ファウンデーションモデルと呼ばれるもので特長は2つあります。
1つ目は日本語能力が非常に高いこと、もう1つは軽量です。

日本語の能力、知識量や文章読解力で海外トップのLLMに匹敵する性能であり、さらに性能を改善してゆきます。

サイズは、海外トップの代表的なトップのLLMと比べて13分の1で実現しています。
なぜ小さいサイズで性能が上がるのかについては後で詳しく説明します。
軽量化のメリットは4つあります。
-
運用時のサーバコスト・消費電力が下がる
-
レスポンスが早い
-
サイズが小さいので、オンプレミス化のハードルが低く、秘匿性の高い領域などでも使える
-
ファウンデーションモデルにお客様さまのクローズなデータを入れて追加学習することでカスタマイズしたLLMを提供できる
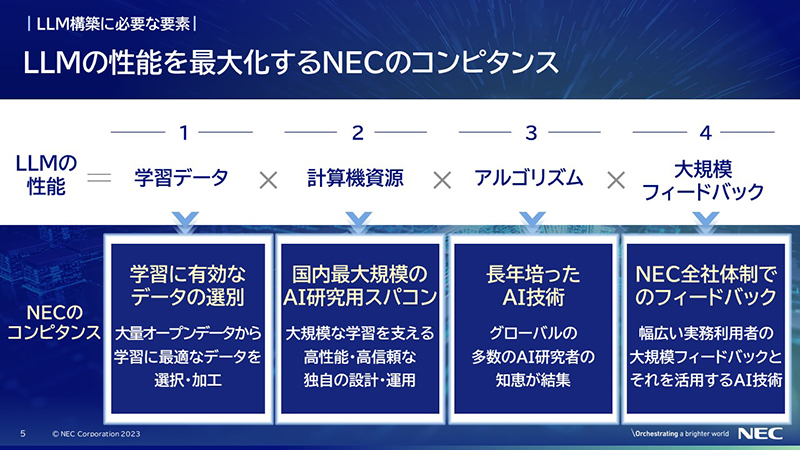
LLMの性能は、学習データ、計算機資源、アルゴリズム、大規模フィードバックの4要素で決まると言われていますが、NECは、それぞれ独自のコンピタンスを有しています。

計算機資源に関しては、NECは国内企業で最大規模のAI研究用スーパーコンピュータを持っており、2023年3月に全面稼働しました。
これを使うことでファウンデーションモデルを1カ月で構築できました。
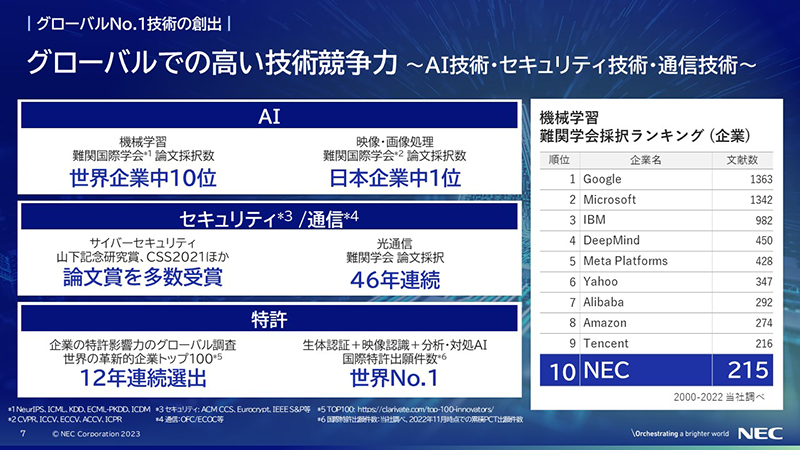
AI技術の点では、NECは難関国際学会の論文採択ランキングでベスト10に入っている唯一の日本企業であり、世界中のメンバーが活躍しました。
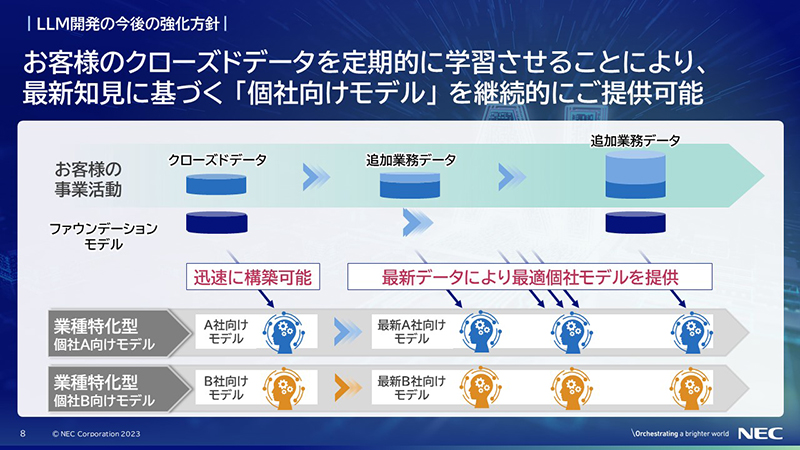
今後NECは、ファウンデーションモデルの改良を続けるとともに、お客様のデータをファウンデーションモデルにマージすることにより、お客様独自の個社向けのLLMを作っていきます。個社向けLLMをリリースした後もお客さんの新しいデータを入れて改良していきます。
このように業種特化型個社モデルを優れたものにしていくことが、お客様の競争力につながっていくと考えています。
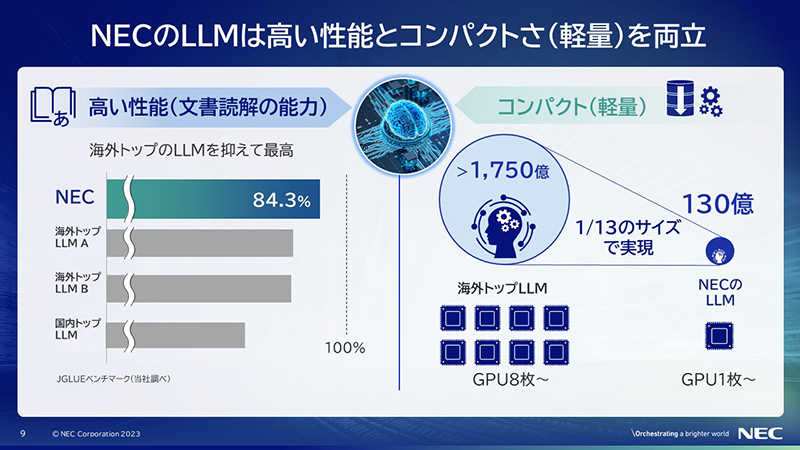
ここからは、今回のLLMがなぜコンパクトさと高い性能を両立できたかについて紹介します。
高い性能について。
業務できちんと使っていただけるLLMを作りたいと考え、日本語の文章を読み解く力と、日本語に関する知識を特に重視して開発を進めました。
文章読解能力とは、例えば1000件の文書があったら1000件の文書に対して質問をして、LLMがその文書を読み込んで正解を出せた割合を計測しています。
NECは1000問に対して843件正解しています。NECが調べた結果、840問を超えるLLMはなく、文章読解能力については、今のところトップを達成できています。
これ以外にも知識量も比較しており、そちらは海外トップと互換の性能が出ています。
コンパクト(軽量)について
海外のトップLLMは1個動かすのに最低でもGPUが8枚必要です。コンシューマPCではGPUは2枚が限度ですし、サーバであってもGPUを8枚搭載したものを作るのは大変です。
一方で我々の技術を駆使して開発したLLMは、GPUが1枚あれば動きます。業務用の標準的なサーバでも動きますし、所謂ゲーミングPCで動きます。
なぜこのようなことができたのかを紹介します。
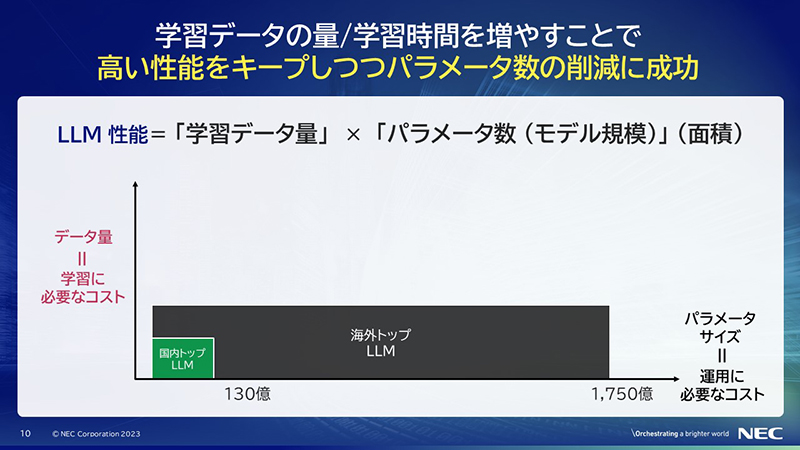
LLMの性能は、学習に使ったデータの量とパラメータの規模とそれぞれ比例関係にある(これらの掛け算で決まる)と、3年前に学会で報告されました。これにより、パラメータ規模を大きくすることで全体的な性能を上げようと試みられてきました。
学習データの量とパラメータの掛け算で決まるということは、横軸がパラメータサイズ、縦軸がデータの量としたとき、それらを掛け合わせた面積が性能を大体近似しているといえます。
海外トップのLLMは、1750億のパラメータを持っており、その中にどれくらいのデータを入れたかは論文で公開されているので、上の図の黒いグラフで表すことができます。
最近、国内でもLLMが盛り上がっており、70億とか130億というものが出てきており、入れたデータ量を可視化すると図の緑の部分になります。

NECのLLM開発も、最初は700億~800億ぐらいでデータ量はトップに合わせようと考えました。これを図で示すと赤い部分になります。
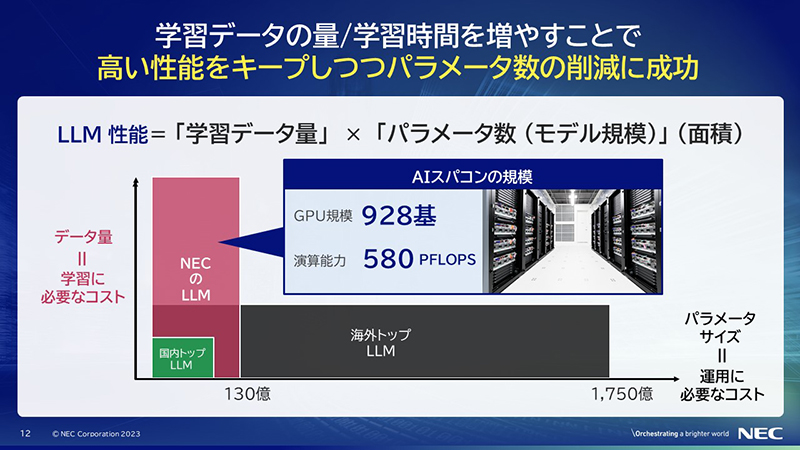
検討を進める中ででNECは、業務で使うなら普及させなければいけないので、もっとLLMを小さくできないか、要は、性能を維持するために面積をキープしつつパラメータを削減したいと考えました。パラメータを抑え、データ量と計算量を大きく増やしたのです。(横長だった赤い部分を立て向きに変更した)
データ量を増やすためにNECは独自に日本語のデータを用意しました。さらに、日本語だけでなく英語をはじめ様々な言語のデータを入れています。それによって言語と言語の間のある種のトランスファーが起こり、日本語の能力が例えば英語を入れることで高まるということが実際に起きています。
NECは、このように圧倒的な量のデータと、圧倒的な計算時間(日本でトップクラスのAIスパコン)、この2つを組み合わせることによって、非常に高い性能を現実的なパラメータサイズのLLMを実現することができました。
<プレスリリース>
<プレゼンテーション資料>
 プレゼンテーション資料ダウンロードリンク
プレゼンテーション資料ダウンロードリンクお問い合わせ