Japan
サイト内の現在位置を表示しています。
AWSでEBSスナップショットを利用したミラーディスクのバックアップ・リストアを試してみました(Windows)
CLUSTERPRO オフィシャルブログ ~クラブロ~
はじめに
Amazon Web Services(以降、AWS)で、Amazon EBS スナップショット(以降、EBS スナップショット)を利用したミラーディスクのバックアップ・リストアを試してみました。
AWSでは、EBS スナップショットの機能で、Amazon EBS ボリューム(以降、EBS)のデータのバックアップが容易に取得できます。
今回は、ミラーディスクに使用するEBSに対して、EBS スナップショットによるバックアップ取得、また、リストアを試してみました。
この記事の内容
1. EBS スナップショットとは
EBS スナップショットとは、EBSのデータを Amazon S3 にバックアップする機能です。
スナップショットの取得は非同期に行われるため、EBSのスナップショットの取得を実行した後は、スナップショットの作成中でも、EBSをそのまま利用可能です。
ただし、スナップショットを作成する際はデータの整合性を保つため、静止点を設けることを推奨します。
スナップショットは増分バックアップで取得されるため、スナップショットの作成時間は最小限に抑えられ、また、ストレージコストを節約することが可能です。
また、Amazon S3に格納されたスナップショットから、データが存在する EBSを復元できます。スナップショットからEBSを復元すると、すべてのデータをそのままの状態で、過去の特定時点の状態が再作成されます。
復元されたEBSをEC2インスタンスにアタッチされていたものと置き換えることで、EBSのリストアをすることが可能です。
スナップショットからEBS を作成すると、 すぐに使用を開始できるよう、レプリケートされたボリュームはバックグラウンドで時間をかけてデータを読み込みます。
まだ読み込まれていないデータにアクセスした場合、ボリュームは要求されたデータを Amazon S3 から即座にダウンロードし、引き続きボリュームの残りのデータをバックグラウンドで読み込みます。このため、ボリュームの作成が完了する前にボリュームへのアクセスを行う場合、パフォーマンスが低下する場合がありますのでご注意ください。
【参考】
 Amazon EBS スナップショット
Amazon EBS スナップショット
2. HAクラスター構成
東京リージョンのVPC環境にWindowsで「VIP制御によるHAクラスター」を構築します。
今回は、1つのEBSに、クラスタパーティションとデータパーティションを作成して利用します。
今回の構成は以下の通りです。
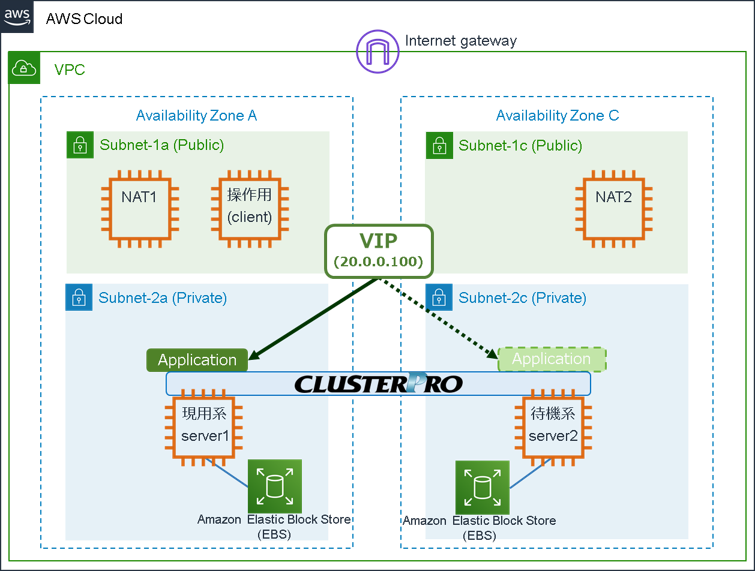
- VPC-1 (VPC ID:vpc-1234abcd)
- -CIDR:10.0.0.0/16
- -Subnets
- ■Subnet-1a (サブネット ID:sub-1111aaaa):10.0.10.0/24
- ■Subnet-2a (サブネット ID:sub-2222aaaa):10.0.110.0/24
- ■Subnet-1c (サブネット ID:sub-1111cccc):10.0.20.0/24
- ■Subnet-2c (サブネット ID:sub-2222cccc):10.0.120.0/24
- -RouteTables
- ■Main (ルートテーブル ID:rtb-00000001)
- >10.0.0.0/16 → local
- >0.0.0.0/0 → igw-1234abcd (Internet Gateway)
- >20.0.0.100/32 → eni-1234abcd (現用系server1のENI ID)
- ■Route-A (ルートテーブル ID:rtb-0000000a)
- >10.0.0.0/16 → local
- >0.0.0.0/0 → eni-1234efgh(NAT1のENI ID)
- >20.0.0.100/32 → eni-1234abcd (現用系server1のENI ID)
- ■Route-C (ルートテーブル ID:rtb-0000000c)
- >10.0.0.0/16 → local
- >0.0.0.0/0 → eni-1234ijkl(NAT2のENI ID)
- >20.0.0.100/32 → eni-1234abcd (現用系server1のENI ID)
- -EC2 instance
- ■Instance-1 (インスタンス ID:i-1XXXXXXXXXXXXXX):server1
- ・ルートデバイス:/dev/sda1
- ・ブロックデバイス:/dev/sda1
- ・ブロックデバイス:xvdb
- ■Instance-2 (インスタンス ID:i-2XXXXXXXXXXXXXX):server2
- ・ルートデバイス:/dev/sda1
- ・ブロックデバイス:/dev/sda1
- ・ブロックデバイス:xvdb
- ディスクの構成
- ■ディスク0
- ・システム:C:\
- ■ディスク1
- ・クラスタパーティション:R:\
- ・データパーティション:M:\
- CLUSTERPRO
- -フェールオーバーグループ (failover)
- ■ミラーディスクリソース
- ・クラスタパーティション:R:\
- ・データパーティション:M:\
設定手順については、CLUSTERPRO X 4.0 Amazon Web Services 向け HAクラスタ構築ガイド(Windows 版)を参照ください。
本手順ではEBS スナップショットの作成や、EBS スナップショットからEBSを作成、EBSを デタッチ・アタッチする際に、AWS CLIを使用するため、これらのアクションに対するアクセス許可を記述したポリシーをあわせて作成し、操作用EC2に付与しておきます。
以下の権限を追加します。
- ec2:CreateSnapshot
- ec2:CreateVolume
- ec2:DetachVolume
- ec2:AttachVolume
3. バックアップ手順
以下の手順で、ミラーディスクに使用しているEBSのバックアップを取得します。
- 1.現用系サーバーでミラーディスクリソースを停止します。
ミラーディスクの静止点を作成するため、一度ミラーディスクリソースを停止します。 必要に応じて、ミラーディスクリソースに依存するグループリソースなど、そのほかのグループリソースを停止します。 - 2.待機系サーバーをシャットダウンします。
CLUSTERPROから待機系サーバーをシャットダウンします。 - 3.現用系サーバーでミラーディスクリソースを起動します。
ミラーディスクリソースを起動して、業務を再開します。必要に応じて、ミラーディスクリソースと合わせて停止したグループリソースがあれば起動します。 - 4.待機系サーバーのミラーディスク用のEBSに対して、EBS スナップショットを取得します。
- 5.待機系サーバーを起動して、クラスターに復帰させます。
4. リストア手順
今回は、下記のケースを想定して、ミラーディスクのリストアを実行します。
【想定ケース】
現用系、待機系ともにデータが全て削除されてしまった場合
例) 現用系サーバーの操作ミスによりデータを全て削除してしまった。
操作ミスにより現用系サーバーのデータを全て削除した場合、待機系にもミラーリングされ、待機系サーバーのデータも全て削除されます。
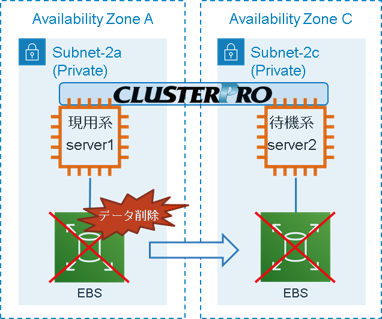
下記手順により、両サーバーに対してミラーディスクのリストアを実行することで、 フルコピーを実行することなく、 ミラーディスクを復旧することができます。
- ※現用系サーバーのみに対してミラーディスクのリストアした場合は、現用系サーバーから待機系サーバーへフルコピーによる復旧が必要になります。
- 1.CLUSTERPROの設定でミラーディスクリソースの設定を削除します。
必要に応じて、ミラーディスクリソースに依存するリソースの依存関係を変更します。 - 2.ミラーディスクのバックアップで取得したEBS スナップショットからEBS ボリュームを作成します。
- 3.既存のEBSを各サーバーからデタッチします。
事前に各サーバーのOS上でミラーディスク用のディスクをアンマウント(オフラインに変更)します。 - 4.新しく作成したEBSを各サーバにアタッチします。
各サーバーのOS上でミラーディスク用のディスクをマウント(オンラインに変更)します。
必要に応じて、ドライブ文字がEBSのデタッチ前と同様になるように設定します。 - 5.ミラーディスクリソースの設定を追加します。
ミラーディスクリソース追加時に、一部設定変更を伴います。
必要に応じて、その他のリソースをミラーディスクに依存するように依存関係を変更します。 - 6.ミラーディスクリソースを起動します。
5. 動作確認
5.1 バックアップの取得
待機系サーバーのミラーディスクからEBSスナップショットを取得する手順をご紹介します。
5.1.1 現用系サーバーでミラーディスクを停止
CLUSTERPROからミラーディスクリソースを停止します。
依存関係に応じてそのほかのグループリソースも停止する場合があるのでご注意ください。

5.1.2 待機系サーバーのシャットダウン
CLUSTERPROから待機系サーバーをシャットダウンします。

5.1.3 現用系サーバーでミラーディスクを起動
CLUSTERPROからミラーディスクを起動します。「5.1.1 現用系サーバーでミラーディスクを停止」でそのほかのリソースが停止した場合は、あわせて起動します。

5.1.4 EBSスナップショットの取得
待機系サーバーのミラーディスクのEBSスナップショットを取得します。これを①とします。
> aws ec2 create-snapshot --volume-id vol-11111111ccccccc(待機系サーバーのミラーディスクのボリュームID) --description "Mirror Volume Snapshot" ・・・①
AWSマネジメントコンソールなどで、スナップショットが作成されていることを確認してください。
作成したEBSスナップショットの[SnapshotId]は後で利用しますので控えておきます。
5.1.5 待機系サーバーを起動してクラスターに復帰
AWSのマネジメントコンソールなどで、待機系サーバーを起動します。
起動したサーバーが正常にHAクラスターに復帰することを確認します。
5.2 リストアの実施
両サーバーのミラーディスクに対して、EBSスナップショットからのリストアを実施する手順をご紹介します。
疑似障害として、ミラーディスク上のデータをすべて削除した状態からスタートします。
5.2.1 ミラーディスクリソース設定の削除
CLUSTERPROの設定からミラーディスクリソースを削除します。
ミラーディスクリソースに依存するリソースがある場合は、誤ってリソースを起動しないように設定を変更します。今回はグループ起動属性を手動起動にしておくことで対処します。
設定の変更後、WebManagerより設定の反映を行います。

5.2.2 EBSボリュームの作成
「5.1.4 EBSスナップショットの取得」で取得した、EBSスナップショットからEBSを作成します。
現用系サーバーを配置したAvailability Zones(以下、AZ)、待機系サーバーを配置したAZ、それぞれに対して作成します。それぞれ②と③とします。
> aws ec2 create-volume --region ap-northeast-1 --availability-zone ap-northeast-1a --snapshot-id snap-11111111ccccccc(①のスナップショットID) --volume-type gp2 ・・・②
> aws ec2 create-volume --region ap-northeast-1 --availability-zone ap-northeast-1c --snapshot-id snap-11111111ccccccc(①のスナップショットID) --volume-type gp2 ・・・③
> aws ec2 create-volume --region ap-northeast-1 --availability-zone ap-northeast-1c --snapshot-id snap-11111111ccccccc(①のスナップショットID) --volume-type gp2 ・・・③
AWSマネジメントコンソールなどから、EBSが作成されていることを確認してください。
作成したEBSの[VolumeId]は後で利用しますので控えておきます。
5.2.3 EBSのデタッチ
まず、OS上から、ディスク(ミラーディスク)をオフラインにします。ディスクの管理から対象のディスクを選択、右クリックしてディスクをオフラインにしてください。

各サーバーのミラーディスクのEBSをデタッチします。ミラーディスクのEBSをデタッチした際の[Device]の値は、EBSスナップショットから作成したEBS(②、③)をアタッチする際、[--device]の設定値とするため控えておきます。
> aws ec2 detach-volume --volume-id vol-11111111aaaaaaa(現用系サーバーのミラーディスクのボリュームID)
> aws ec2 detach-volume --volume-id vol-11111111ccccccc(待機系サーバーのミラーディスクのボリュームID)
> aws ec2 detach-volume --volume-id vol-11111111ccccccc(待機系サーバーのミラーディスクのボリュームID)
5.2.4 EBSのアタッチ
各サーバーに、「5.2.2 EBSボリュームの作成」で作成したEBSをアタッチします。
> aws ec2 attach-volume --volume-id vol-22222222aaaaaaa --instance-id i-11111111aaaaaaa --device /dev/sdx
> aws ec2 attach-volume --volume-id vol-22222222ccccccc --instance-id i-11111111cccccc --device /dev/sdx
- ■vol-22222222aaaaaaa :②で作成したEBSのボリュームID
- ■i-11111111aaaaaaa :現用系サーバーのインスタンスID
- ■/dev/sdx :デタッチの際に控えたDeviceの値
> aws ec2 attach-volume --volume-id vol-22222222ccccccc --instance-id i-11111111cccccc --device /dev/sdx
- ■vol-22222222ccccccc :③で作成したEBSのボリュームID
- ■i-1111111ccccccc :待機系サーバーのインスタンスID
- ■/dev/sdx :デタッチの際に控えたDeviceの値
OS上から、ディスク(ミラーディスク)をオンラインにします。ディスクの管理から対象のディスクを選択、右クリックしてディスクをオンラインにしてください。

このときドライブレターが元のミラーディスクのドライブレターから変更されるサーバーについては元のドライブレターに戻してください。
本検証においては、ディスクオンライン後に現用系サーバーにおいて、ドライブレターが下図のように(R:) > (D:)、(M:) > (E:)のように変更されたため、ドライブレターを元通りに修正しました。

OS上でデタッチ前と同様にディスクが認識されていること、データが復元されていることを確認します。
5.2.5 ミラーディスクの設定を追加
「5.2.1 ミラーディスク設定の削除」で削除したミラーディスクリソースの設定を再度追加します。このとき、ミラーディスクリソースのプロパティから[調整]ボタンをクリックし、[初期ミラー構築を行う]のチェックを外しておきます。
また、ミラーディスクリソースの削除時に、合わせて変更したグループ起動属性を手動起動にから自動起動に戻しておきます。
設定の変更後、WebManagerより設定の反映を行います。

5.2.6 ミラーディスクの起動
グループを起動してクラスターが正常に起動するかを確認します。
また、待機系に切り替えて動作を確認します。

さいごに
今回は EBSスナップショットを使用してミラーディスクのバックアップ・リストアを試してみました。
簡易的に、バックアップの取得、リストアが実施できる点は、非常に有用だと思います。
また、本手順により、両サーバーに対してミラーディスクのリストアを実行することで、 フルコピーを実行することなく、 ミラーディスクが復旧できますので、復旧時間の短縮にも活用できると思います。
本記事の構成をご検討の際は、CLUSTERPROの試用版を用いて検証した後、ご提案・構築ください。
お問い合わせ
本記事に関するお問い合わせは、お問い合わせ窓口までお問い合わせください。
お問い合わせ窓口までお問い合わせください。