Japan
サイト内の現在位置を表示しています。
AWSにおけるDataSpider ServistaのHAクラスター構築 ~AWSのサービス間でデータ連携~ (Windows)
CLUSTERPRO オフィシャルブログ ~クラブロ~はじめに
Amazon Web Services(以降、AWS)において、データ連携ツールであるDataSpider Servista(以降、DataSpider)を冗長化する手順をご紹介します。
DataSpiderは異なるシステムの様々なデータやアプリケーションを、豊富なアダプタを使って自由につなぐ、データ連携ツール(EAIソフトウェア)です。
例えば、データベースのテーブル情報をファイル形式に変換し、ストレージに保存することが可能です。
今回はDataSpiderでAmazon Relational Database Service(以降、RDS)のデータをAmazon Simple Storage Service(以降、S3)に保存するシステムを冗長化します。
この記事の内容
1. HAクラスター構成
今回はDataSpiderのミラーディスク型HAクラスターを構築します。
クライアントとなるDataSpider Studio(以降、Studio)をインストールした操作用インスタンスは、HAクラスターを構成するインスタンスと同じVPC内に配置します。
StudioはDataSpiderの統合開発環境です。StudioではGUIベースでスクリプトの開発、運用の設定、サーバーの管理を一元的に行うことができます。
HAクラスターに接続するクライアント(Studio)をHAクラスターを構成するインスタンスと同じVPC内に配置するため、HAクラスター構成はAWS仮想IPリソースを用いた「VIP制御によるHAクラスター」がベースとなります。
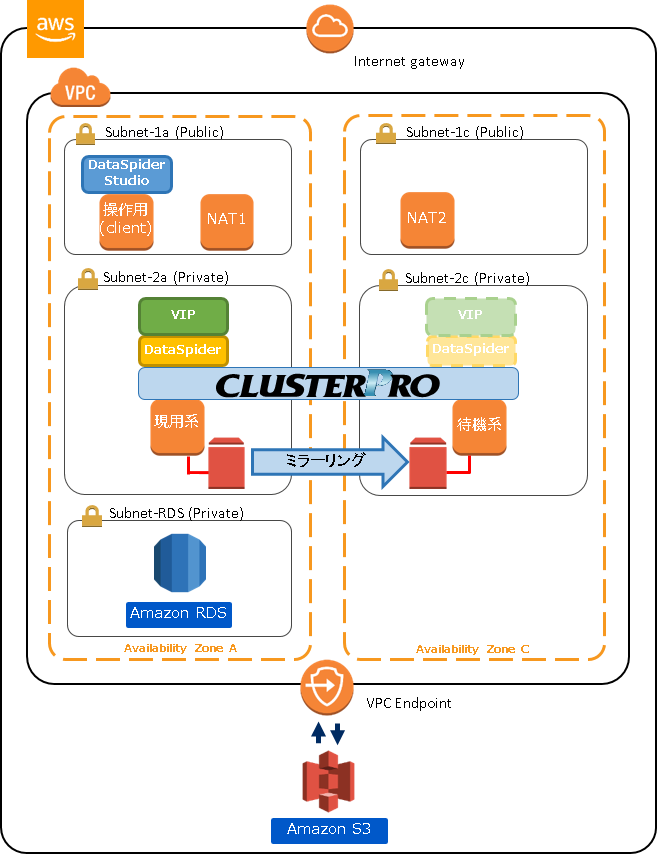
また、今回はDataSpiderの接続先としてRDSとS3を利用します。
RDSはクラウドでリレーショナルデータベースを簡単にセットアップし、運用・拡張することのできるウェブサービスです。リレーショナルデータベースの機能をDBインスタンスとして利用することができます。
S3はインターネットを経由して利用できるストレージサービスです。データのバックアップやログファイルの保存先などとして利用することができます。
今回はRDSのDBインスタンスから取得したテーブル情報をファイル形式(CSV)に変換し、S3のバケットへ保存するデータの連携を行います。
※DataSpiderにはDataSpider Servista 4.1 SP2、RDSのDBインスタンスのDBエンジンにはOracle Standard Edition Two 12.1.0.2.v11を利用しています。
2. HAクラスター構築手順
2.1 VIP制御によるHAクラスターの作成
DataSpiderを冗長化する際のベースとなる「VIP制御によるHAクラスター」を作成します。
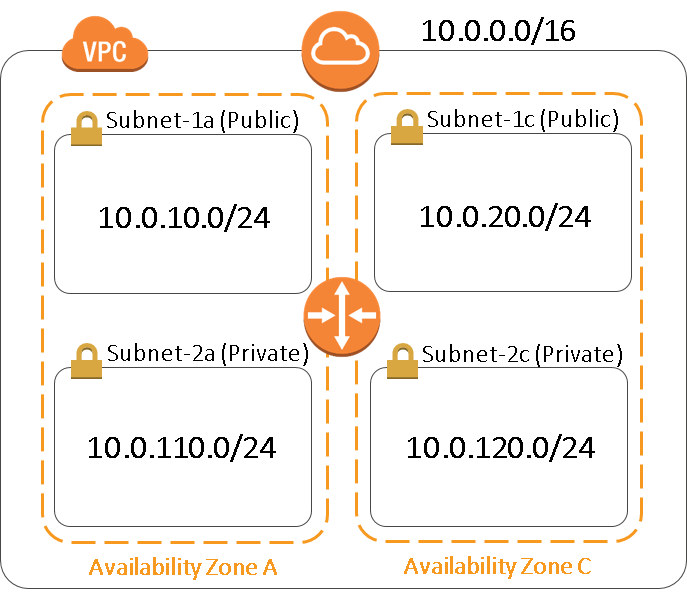
VPCおよびCLUSTERPROの構成は下記のとおりです。CLUSTERPROのフェールオーバーグループには「AWS仮想IPリソース」と「ミラーディスクリソース」のみを登録します。
- VPC(VPC ID:vpc-1234abcd)
- -CIDR:10.0.0.0/16
- -Subnets
- ■Subnet-1a (サブネット ID:sub-1111aaaa):10.0.10.0/24
- ■Subnet-1c (サブネット ID:sub-1111cccc):10.0.20.0/24
- ■Subnet-2a (サブネット ID:sub-2222aaaa):10.0.110.0/24
- ■Subnet-2c (サブネット ID:sub-2222cccc):10.0.120.0/24
- -RouteTables
- ■Main (ルートテーブル ID:rtb-00000001)
- >10.0.0.0/16 → local
- >0.0.0.0/0 → igw-1234abcd(Internet Gateway)
- >20.0.0.200/32 → eni-1234abcd(ENI ID)
- ■Route-A (ルートテーブル ID:rtb-0000000a)
- >10.0.0.0/16 → local
- >0.0.0.0/0 → nat-1234abcd (NAT1)
- >20.0.0.200/32 → eni-1234abcd (ENI ID)
- ■Route-C (ルートテーブル ID:rtb-0000000c)
- >10.0.0.0/16 → local
- >0.0.0.0/0 → nat-5678efgh (NAT2)
- >20.0.0.200/32 → eni-1234abcd (ENI ID)
- CLUSTERPRO
- -フェールオーバーグループ(failover)
- ■AWS仮想IPリソース
- >IPアドレス:20.0.0.200
- ■ミラーディスクリソース
- >データパーティション:Mドライブ
- >クラスターパーティション:Rドライブ
フェールオーバーグループにAWS仮想IPリソースとミラーディスクリソースを登録したら、各インスタンスでフェールオーバーグループが正常に起動できることを確認します。

【参考】
 CLUSTERPRO X ソフトウェア構築ガイド
CLUSTERPRO X ソフトウェア構築ガイド
- Windows > クラウド > Amazon Web Services > HAクラスタ構築ガイド
2.2 RDS DBインスタンスとS3 バケットの作成
DataSpiderの接続先として、RDSのDBインスタンスとS3のバケットを作成します。
今回はDataSpiderでRDSのDBインスタンスから取得したテーブル情報をCSV形式に変換し、S3のバケットに保存します。
RDSのDBインスタンスはHAクラスターを構成するインスタンスと同じVPC内に作成します。また、HAクラスターを構成するインスタンスからRDSにアクセスするため、ネットワーク、セキュリティグループを設定します。
S3のバケットはHAクラスターを構成するインスタンスと同じリージョン内に作成します。また、HAクラスターを構成するインスタンスからS3のバケットにアクセスするためにネットワーク、セキュリティグループを設定します。今回はVPCエンドポイントを作成し、S3のバケットにアクセスします。別途、バケットにアクセスするためのアクセスキー、シークレットキーを作成します。
2.3 DataSpiderのインストールと設定
2.3.1 DataSpiderのインストール
HAクラスターを構成する各インスタンスにDataSpiderをインストールします。
まず、フェールオーバーグループが起動している現用系インスタンスにインストールします。
今回、インストール時の設定は基本的にデフォルトを選択しますが、下記の設定項目はデフォルトの設定から変更しています。
- 接続先情報の設定
ホスト名/IPアドレス :20.0.0.200 ← VIPを入力する
- インストール先の設定
インストール先のパス:M:\Program Files\DataSpiderServista ← データパーティション(Mドライブ)配下を入力する
インストールが完了したら、DataSpiderのサービスのスタートアップの種類を手動に設定します。
サービスが停止状態であることを確認し、サービスのスタートアップの種類を「自動」から「手動」に変更します。
※インストール完了直後はサービスが起動状態になっているため、サービスを停止してください。
C:\Users\Administrator>sc stop "DataSpider_Servista"
SERVICE_NAME: DataSpider_Servista
TYPE : 10 WIN32_OWN_PROCESS
STATE : 3 STOP_PENDING
(NOT_STOPPABLE, NOT_PAUSABLE, IGNORES_SHUTDOWN)
WIN32_EXIT_CODE : 1077 (0x435)
SERVICE_EXIT_CODE : 0 (0x0)
CHECKPOINT : 0x1
WAIT_HINT : 0x0
C:\Users\Administrator>sc query "DataSpider_Servista"
SERVICE_NAME: DataSpider_Servista
TYPE : 10 WIN32_OWN_PROCESS
STATE : 1 STOPPED ← 停止状態
WIN32_EXIT_CODE : 1077 (0x435)
SERVICE_EXIT_CODE : 0 (0x0)
CHECKPOINT : 0x0
WAIT_HINT : 0x0
C:\Users\Administrator>sc config "DataSpider_Servista" start= demand
[SC] ChangeServiceConfig SUCCESS
次に、フェールオーバーグループを移動して待機系インスタンスでDataSpiderをインストールします。既存のDataSpiderに対する上書きインストールができないため、インストール時に「インストール先のパス」で指定したフォルダ(今回はM:\Program Files\DataSpiderServista)を削除し、インストールできる状態にします。
インストール時の設定には現用系インスタンスへのインストールと同じ設定を指定してインストールを行います。
インストールが完了したら、サービスが停止状態であることを確認し、サービスのスタートアップの種類を「手動」に変更します。
今回の構成では、DataSpiderがOracleと連携するため、連携用のアダプタを追加でインストールします。
※一部のアダプタを利用する際には、別途ライブラリのインストールや設定ファイルの編集などが必要な場合があります。詳細はDataSpiderのオンラインヘルプをご参照ください。
※ライブラリのインストールや設定ファイルの編集はDataSpiderを停止した状態で行ってください。
※今回利用するAmazon RDS for Oracle 12c アダプタにはライブラリのインストールが必要です。
また、操作用インスタンスにStudioをインストールします。インストール時の設定は基本的にデフォルトを選択しますが、下記の設定項目はデフォルトの設定から変更しています。
- インストール対象の選択
インストール対象:クライアントのみ
- 接続先情報の設定
ホスト名/IPアドレス:20.0.0.200 ← VIPを入力する
2.3.2 DataSpiderの設定
各インスタンスでDataSpiderのインストールが完了したら、DataSpiderの「死活確認用スクリプト」の作成を行います。
DataSpiderでは、外部アプリケーションからスクリプトを実行するためのScriptRunnerという機能があります。ScriptRunnerで「死活確認用スクリプト」を実行することで、Windowsサービスの実行状況やネットワーク疎通確認に加え、DataSpiderの実行状況の観点でも死活確認を実施することができます。
作成した「死活確認用スクリプト」をCLUSTEPROから実行することによりDataSpiderを監視します。
フェールオーバーグループを現用系インスタンスで起動し、DataSpiderのサービスを手動で起動します。
Studioから「ホスト名/IPアドレス」にVIPを指定してDataSpiderに接続します。
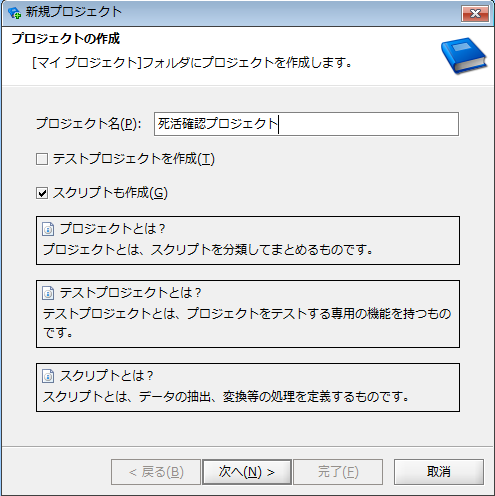
Studioの「新規プロジェクト」アイコンより「プロジェクト作成ウィザード」を開きます。プロジェクト名、スクリプト名に任意の名称を入力し、プロジェクト、スクリプトを作成します。
例)
プロジェクト名:死活確認プロジェクト
スクリプト名 :死活確認スクリプト
「デザイナ」ツールより、スクリプトの処理内容を作成します。今回は[Start]から[End]までフローを引きます。
フローを引いたら、Studio上部の「メニュー」から[スクリプトの実行]を選択し、スクリプトの実行が成功することを確認します。

Studio上部の「メニュー」から[ファイル]-[プロジェクトをサービスとして登録]を選択して、「死活確認用スクリプト」をサービスに登録します。
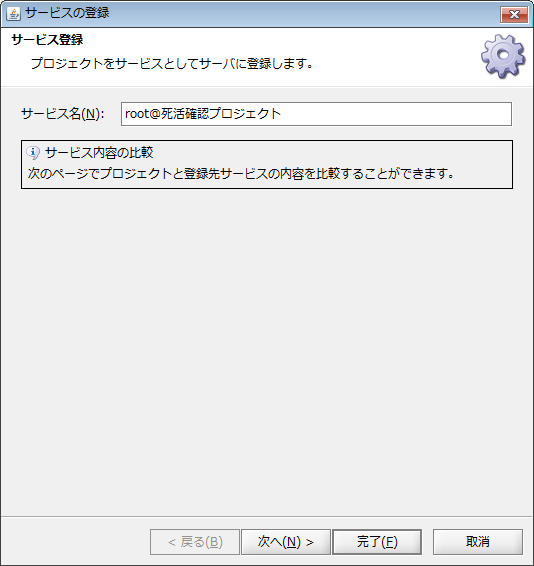
「死活確認用スクリプト」をサービスに登録したら、ScriptRunnerの設定を行います。
ScriptRunnerから死活確認スクリプトを実行するために起動設定ファイルを作成します。
ScriptRunnerの設定方法の詳細については、DataSpiderのオンラインヘルプ [ScriptRunner]の項をご参照ください。
作成する起動設定ファイルのサンプルは下記です。
起動設定ファイルの格納先:M:\Program Files\DataSpiderServista\server\bin
起動設定ファイル名 :test.xml
<?xml version="1.0" encoding="Shift_JIS"?>
<scriptrunner>
<connection>
<host>20.0.0.200</host>
<port>7700</port>
<description></description>
<user>root</user>
<password>xxxxxxxxxx</password>
</connection>
<params>
<param project="root@死活確認プロジェクト" script="死活確認スクリプト">
<input key="var">value</input>
<option key="ENABLE_XML_LOG">true</option>
</param>
</params>
</scriptrunner>
<scriptrunner>
<connection>
<host>20.0.0.200</host>
<port>7700</port>
<description></description>
<user>root</user>
<password>xxxxxxxxxx</password>
</connection>
<params>
<param project="root@死活確認プロジェクト" script="死活確認スクリプト">
<input key="var">value</input>
<option key="ENABLE_XML_LOG">true</option>
</param>
</params>
</scriptrunner>
ScriptRunnerの設定が完了したら、DataSpiderのサービスを手動で停止します。
2.4 DataSpiderのHAクラスターへの組み込み
CLUSTERPROによるDataSpiderの起動・停止制御はCLUSTERPROのサービスリソースにより実現できます。
フェールオーバーグループに「サービスリソース」を追加する際、サービス名には「DataSpider Servista」を選択してください。

次に、監視リソースを登録します。
サービス監視リソースの設定を変更し、また、カスタム監視リソースを追加します。
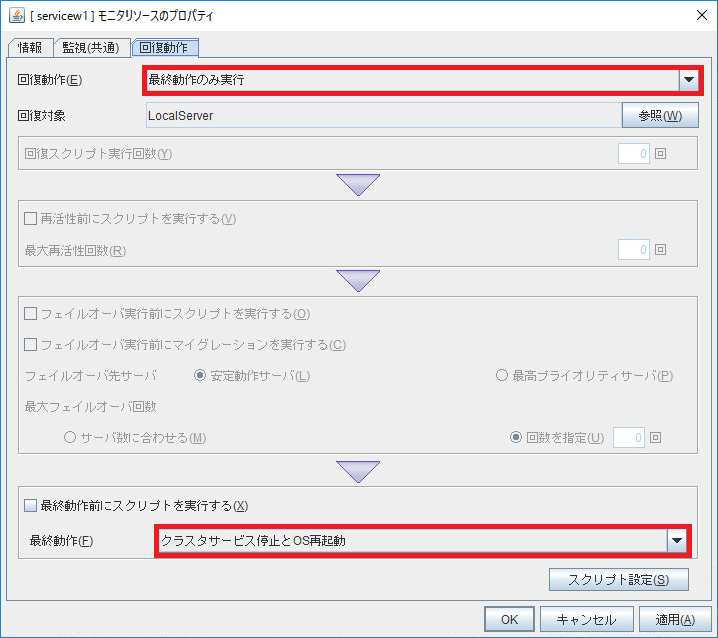
監視リソースの回復動作は「最終動作のみ実行」を選択し、最終動作は「クラスタサービス停止とOS再起動」を選択します。
まず、サービス監視リソースの回復動作を変更します。
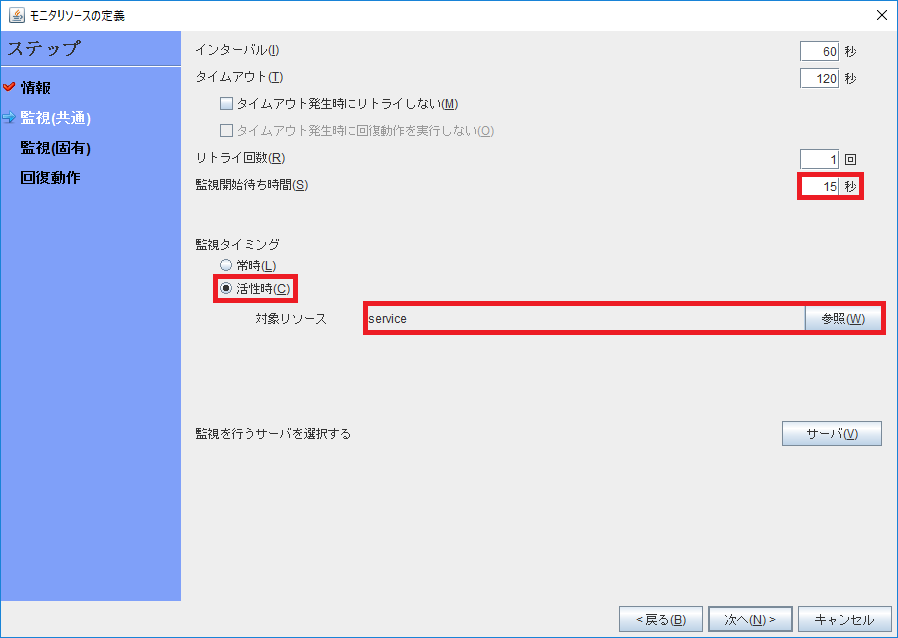
次にDataSpiderを監視するリソースを登録します。モニタリソースのタイプは「カスタム監視」を選択します(今回の検証ではモニタリソース名に「dataspiderw」を設定します)。
監視タイミングは「活性時」を選択し、対象リソースにはDataSpiderの制御を行うサービスリソースを設定します(今回の検証では対象リソースに「service」を設定します)。また、監視開始待ち時間にはDataSpiderのサービスが実行中になってから実際に動作を始めるまでの時間を入力してください(今回の検証では監視待ち時間に15秒を設定します)。
「編集」を選択し、監視スクリプトを登録します。

監視スクリプトのサンプルは下記です。監視はDataSpiderのScriptRunnerで行います。
ScriptRunner.exeの引数に、ScriptRunnerの設定で作成したxmlファイル(今回の検証では、M:\Program Files\DataSpiderServista\server\bin\test.xml)を指定して、実行します。
rem ***************************************
rem * genw.bat *
rem ***************************************
echo START
"M:\Program Files\DataSpiderServista\server\bin\ScriptRunner.exe" "M:\Program Files\DataSpiderServista\server\bin\test.xml" > nul 2>&1
exit %errorlevel%
回復動作は「最終動作のみ実行」を選択し、最終動作は「クラスタサービス停止とOS再起動」を選択します。

リソースの追加が完了したら、設定の反映を行います。

3. 動作確認
現用系インスタンスでフェールオーバーグループを起動します。Studioから「ホスト名/IPアドレス」にVIPを指定してDataSpiderに接続します。StudioでAWSのサービスに対するデータの連携用のスクリプトを作成します。
今回作成するデータの連携用のスクリプトでは下記のデータの流れを実現します。
今回作成するデータの連携用のスクリプトでは下記のデータの流れを実現します。
- 1.DBインスタンスからテーブル情報を取得
- 2.取得したテーブル情報をCSV形式に変換
- 3.S3へCSVファイルを保存
使用する各コンポーネントに対して用いる接続先情報やテーブル名、バケット名などには環境に合わせて適切な設定を行います。
プロジェクト名:sample
スクリプト名 :sample_script
コンポーネント:クラウド - Amazon RDS for Oracle - テーブル読み取り
変換 - 基本 - マッピング
ファイル - CSV - CSVファイル書き込み
クラウド - Amazon S3 - ファイル/フォルダ書き込み
ファイル - ファイル操作 - ファイル/ディレクトリ削除
プロジェクト名:sample
スクリプト名 :sample_script
コンポーネント:クラウド - Amazon RDS for Oracle - テーブル読み取り
変換 - 基本 - マッピング
ファイル - CSV - CSVファイル書き込み
クラウド - Amazon S3 - ファイル/フォルダ書き込み
ファイル - ファイル操作 - ファイル/ディレクトリ削除

Studio上部の「メニュー」から[スクリプトの実行]を選択して、スクリプトを実行します。
スクリプトの実行が成功するとその旨を伝えるダイアログが表示されます。

RDSのDBインスタンスから取得したテーブル情報がS3のバケットにCSVファイルとして保存されていれば成功です。
スクリプトの実行が確認できたら、DBインスタンスのテーブル情報を更新しコミットします。また、現用系インスタンスから待機系インスタンスへフェールオーバーグループを手動で移動します。
フェールオーバーグループの移動が完了したら、DataSpiderへ再接続します。Studio下部の「Studio」から[サーバへの再接続]を選択してDataSpiderに再接続し、現用系インスタンスで作成したデータの連携用のスクリプトを再度実行します。
S3のバケットに保存されているCSVファイルが更新されていれば、スクリプトの実行は成功です。
さいごに
今回はAWS上でDataSpiderを冗長化する手順をご紹介しました。
HAクラスターの構築に関する疑問点や気になる点などがございましたら後述の窓口までお問い合わせください。
お問い合わせ
本記事に関するお問い合わせは、お問い合わせ窓口までお問い合わせください。
お問い合わせ窓口までお問い合わせください。- ※本記事で紹介しているスクリプトの内容についてのお問い合わせ、および、お客様環境に合わせたカスタマイズにつきましてはCLUSTERPRO導入支援サービスにて承っておりますので、上記窓口の"ご購入前のお問い合わせ"フォームまでお問い合わせください。
