Japan

Japan
各製品の各機能のサポートの有無についてはこちらをご覧ください。
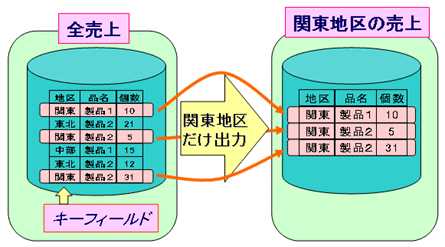
特定の条件を満たすレコードのみ処理します。
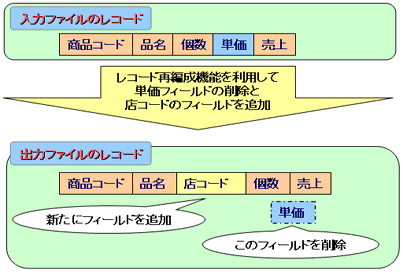
レコードのフィールド構成を変更します。
あるキーにしたがってソートしようとすると、大小の順位の決定がつかない(同値キー)レコードが出て来ることがあります。このときにレコードを削除したり、出力順を指定することができます。選択できる指定は以下の3つです。
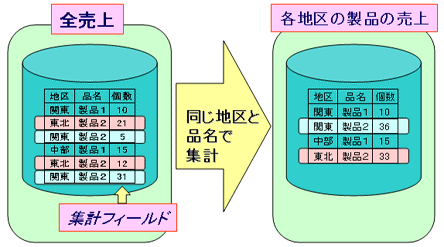
同値キーレコード集計機能は、同値キーレコードの指定されたフィールドの総計を1レコードに集約して出力する機能です。その他の同値キーレコードは削除されます。
レコード累計機能は、出力する全レコードの指定されたフィールドの値を加算し、その結果を実行レポートに出力します。
入力レコードを共通の性質を持った複数のレコードクラスに分割し、レコードクラスごとに比較/編集を行います。
具体的には、各レコードクラスのレコードは、レコードクラスに属するための条件で規定し、キー、レコードの再編成などをレコードクラスごとに指定します。
キーはレコードクラスごとに指定しますが、各レコードのキーを指定順に連結してまとめたものを共通のキーとして比較することにより、異なるクラスのレコードの比較もできます。
また、フォーマットの異なるレコードが混在する場合に、フォーマットごとにクラス分けした後、編集処理により同じフォーマットに統一してソート/マージすることもできます。
レコードを指定した長さに変換します。対象レコードが、指定レコード長より短い場合は、指定パディング文字で不足分を埋めます。また、指定レコード長より長い場合は、レコードの超えてる部分を切り捨てます。
複数のファイルのレコード長が、それぞれ異なる場合に便利です。
キー比較時の文字比較順序(コレーティングシーケンス)を変更できます。例えば、ASCIIコードのデータをEBCDICコードの文字順序でソートする時にこの機能を使用します。定義済みの文字比較順序指定の他、ユーザ定義による任意の文字比較順序の指定も可能です。Windows版では1バイト文字、Linux版では1バイト文字/2バイト文字の指定が可能です。
キーを西暦年下2桁の数値として比較します([yy]又は[mmddyy])。比較する基準年を任意に指定できます。
フィールドの開始位置と終了位置の指定において、0オリジン、または、1オリジンを選択できます。
0オリジン:レコード/フィールドの先頭を0とする数え方
1オリジン:レコード/フィールドの先頭を1とする数え方
オリジンの指定がない場合は、0オリジンとして処理されます。
出力ファイルごとに別々のレコード操作の処理を指定できます。指定できる機能は以下のとおりです。
入出力ファイルを一時ファイルとして扱うことができます。BATファイル中で複数のアプリケーションやユーティリティを組み合わせ、その中でデータを受け渡しながら一連の処理を行う場合に便利です。一時ファイルはBATファイル実行中に自動的に作成され、終了時に削除されます。
一時ファイルを利用するには、アプリケーション実行環境が必要です。
COBOL のファイルマップ機能を利用して、SORTKITで扱う以下のファイルについて、COBOL ファイルマッパーで関連付けされているファイル名(内部ファイル名)で指定できます。
ファイルマップ機能を利用することで、パラメータ記述とファイルの所在を分離でき、システムの保守性向上や、開発環境から実行環境への移行などの移行性向上に効果があります。
ファイルマップ機能を利用するには COBOL 製品が必要です。詳細はこちらをご覧ください。
IFAS索引順編成ファイルのレコードをインデックスの順に読み込みます。
自動で、適切なメモリサイズを計算し、ソートを行う機能です(ソート処理のみに有効です)。
ソートを実行したファイルやレコードの情報をファイルに出力することができます。先頭にはタイトルを入れることができます。
COBOL で作成された サーバコンポーネントの整列・併合処理に対応しておりますので、COBOLで開発された Web/分散システムの整列・併合処理としてご利用いただけます。
シーケンシャルに行っていたソート実行処理をマルチスレッド化してパラレルに実行させることによりソート処理性能を向上します。シーケンシャル実行時との比較データは下記のリンクよりご覧ください。
64bitネイティブ対応製品は、以下の特徴があります