Japan
サイト内の現在位置を表示しています。
LLMエクスプレーナーによる生成AI出力結果の検証
Vol.77 No.1 BluStellar特集 BluStellarが牽引するDXの未来 ~AI・セキュリティ・データマネジメント・モダナイゼーションで拓く価値創造モデル~企業における大規模言語モデル(Large Language Model、LLM)の活用を進める動きは、業務効率の向上を目的として加速していますが、一方で、その出力の正確性を検証することは、依然として、大きな課題であり続けています。本稿で紹介するLLMエクスプレーナーは、AIが生成した回答とその根拠となるソース文書を紐付けることで、AI出力への信頼性と透明性の向上を支援するソリューションとなります。これにより、AI出力の迅速かつ効率的な検証が可能となり、特に高リスク領域での活用に有効です。LLMエクスプレーナーは、自動データ生成及び高効率な帰属モデルの訓練によってこの仕組みを実現します。本技術の有効性評価の結果、従来の大規模モデルに比べて計算コストを70分の1に抑えながら、高い精度を達成することが確認されました。本技術は、LLMの利用を潜在的なリスク要因への対応から解放し、ミッションクリティカルなインテリジェントシステムにおける信頼性の強化を通して、戦略的な能力へと転換させるものです。
1. はじめに
大規模言語モデル(Large Language Model 、以下、LLM)は、「業務の自動化」「知見の創出」「顧客エンゲージメントの高度化」を推進する、企業活動の中核的なコンポーネントとして急速に浸透しつつあります。しかし、その導入が拡大する一方で、信頼性・透明性・コンプライアンスといった重要な課題も同時に顕在化しています。なかでも最も喫緊な課題の1つが、いわゆる「ハルシネーション」と呼ばれる不正確または誤解を招く出力の防止です。こうした出力は、信頼の失墜や業務プロセスの混乱を招くだけでなく、法規制上またはレピュテーション上のリスクにもつながる恐れがあります。企業がLLMを意思決定などの高リスク領域で活用しようとするなかで、AIが生成するコンテンツの検証可能性を確保することは、説明責任、業務の健全性、そしてステークホルダーの信頼を維持する上で不可欠となっています。
本研究では、LLMの回答を特定のソース文書に紐付けることで、この課題に対応しました。これにより、LLMの出力結果を効率的に検証できるようになり、AIによる出力に透明性・監査性・信頼性を求める組織にとって不可欠な機能が提供可能となりました。
今回、新たに開発したLLMエクスプレーナーは、先進的なLLMを活用して高品質な合成訓練データを自動生成し、小型で効率的なモデルによるリアルタイムかつ高精度な文単位のコンテキストアトリビューションを実現します1)。コンテキストアトリビューションとは、LLMが生成した文書を、それを裏付けまたは反証するソース文書と紐付けるタスクです。従来手法のように文書全体レベルの粗い証拠や、高コストな推論処理に依存することなく、LLMエクスプレーナーは迅速かつ正確なアトリビューションを提供し、高コストな手動アノテーションの必要性を大幅に削減し、多様な分野でのスケーラブルな運用が可能です。
本技術は、NECのお客様である政府機関、通信事業者、金融機関、輸送分野の組織にとっての具体的なメリットを提供します。AI生成コンテンツの信頼性向上に加え、AI生成回答の迅速かつ正確な検証による業務効率化、そして透明性と説明責任が求められる厳格な規制への対応が可能です。ユーザースタディの結果からは、LLMエクスプレーナーのアトリビューションモデルは、エンドユーザーによるAI生成回答の検証をより迅速かつ高精度に実現し、手作業による負担を最大50%削減できることが確認されています。
LLMエクスプレーナーを用いたコンテキストアトリビューションにより、ユーザーは自動質問回答の信頼性を高め、ミッションクリティカルな意思決定プロセスを支援する堅牢かつスケーラブルなツールを利用できます。このような技術革新により、複雑な規制要件を有する産業分野や公共機関においても、「安全性・透明性・信頼性」を備えたAI技術の提供が可能となります。
図1に示したとおり、「質問」「LLMが生成した回答」「(手動入力または検索による)コンテキスト」を入力すると、アトリビューションモデルはコンテキスト内からLLMの生成回答を裏付ける文書セクションを特定します。この裏付け情報の提示により、ユーザーはLLMの生成回答をより迅速かつ正確に検証できることがユーザースタディにおいて確認されています。
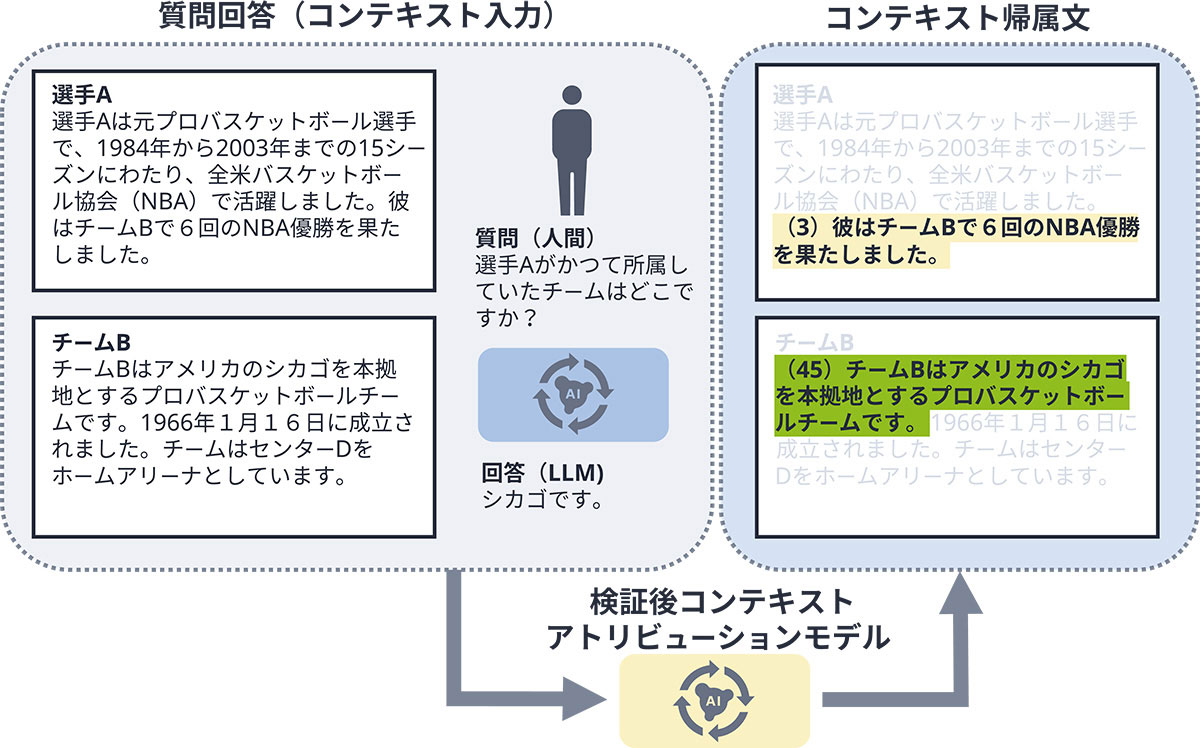 拡大する
拡大する2. システム概要
本ソリューションは、AIが生成したテキスト回答のリアルタイム検証を可能にしつつ、運用効率も維持する革新的な自動ソースアトリビューションシステムです。本システムは、各AI生成回答を裏付ける具体的なソース文書を自動的に特定・引用することで、迅速なトレーサビリティを提供します。
本技術は、AIの生成コンテンツを出力後に分析する「検証後方式」を採用しており、既存のAIシステムや業務フローを変更することなく導入可能です。コアとなるアーキテクチャは、次の3つの統合コンポーネントで構成されています。
- (1)訓練データ生成エンジン:高度なAI技術を活用し、高品質な検証用訓練データを自動生成することで、高コストな手動アノテーションへの依存を排除します。
- (2)軽量アトリビューションモデル:ソース検証タスクに特化してファインチューニングされた、高効率かつコストパフォーマンスの高いAIモデルを展開します。
- (3)リアルタイム検証インタフェース:根拠となる証拠を明確に可視化することで、即時にソースアトリビューションを提供します。
3. LLMエクスプレーナー
従来のソースアトリビューションシステムでは、AIが生成した回答を裏付ける参照文書のどの部分が根拠となるかを正確に特定するため、大量の訓練データを必要とするのが一般的です。従来手法では、高コストな手動アノテーション作業が必要なため、大規模環境で検証システムを展開しようとする組織にとって大きな導入障壁となっていました。本ソリューションは、訓練データを自動生成することで、手動アノテーションを不要としつつ、従来手法を上回る高品質な結果を実現し、この課題を解決します。
ソースアトリビューションとは、信頼できるドキュメント群のなかで、AIが生成した質問回答ペアを裏付ける部分を特定するための技術です。具体的には、ビジネス上のクエリ、AIが生成した回答、複数の文書セクションからなる組織内コンテキストドキュメントを与えると、AIが生成した回答を完全に裏付け(または反証)する具体的な文書セクションを特定する技術となります。この検証モデルを高コストな人的監督なしに効率的に学習させるため、本研究では先進的なAIシステムを活用した自動データ生成手法を開発しました。
自動訓練データ生成には2つの手法を実装しています。1つ目は、ベースライン手法として識別的アプローチを用います。既存の質問回答ペアとその関連ドキュメントコンテキストをAIシステムで処理し、回答を裏付ける文書セクションを特定します。これを基に知識移転によって小型の検証モデルを訓練します。2つ目の手法であるSynQA(Synthetic Question Answering)手法では生成的アプローチを採用しています。選択した文書セクションをAIシステムに入力し、それらを十分に裏付ける質問回答ペアを自動生成します。この手法は、AIの自然文生成能力をより有効に活用しつつ、訓練データ内に明確な根拠のトレイル(証拠の流れ)を確保できる点が特長です。
3.1 訓練設定
LLMエクスプレーナーの訓練データ生成は、「コンテキスト選択」「質問回答生成」「ディストラクター(無関係情報)統合」の3つの統合コンポーネントを通して実行されます。この包括的なアプローチにより、関連情報とは無関係な情報源を検証システムで除外しなければならない実際のエンタープライズ環境を忠実に反映した訓練データの作成が可能となりました。
- (1)コンテキスト収集戦略:特定のビジネス領域に関連する一貫した情報が網羅的に記載されたナレッジリポジトリをデータソースとして活用しました。本システムでは、エンタープライズの用途に最適化された2つの収集戦略を採用しています。カスタマーサービスやサポートのシナリオでは、各ドキュメントからその内容セクションをコンテキストとして選択し、対話志向のデータ生成を行います。一方、複数ソースにまたがる推論が必要な複雑な分析タスクの場合は、相互参照を含む文書セクションを特定し、これらのつながりをたどることで、文書間にインフォメーションチェーン(情報の連鎖)を構築します。これにより、意味的な一貫性を保ちながら、実世界の企業意思決定プロセスを模倣した高度な推論パターンにも対応可能となりました。
- (2)質問回答生成プロセス:選択されたコンテキストを用いて、高度なAIシステムが実世界のシナリオを反映した、現実的な質問回答ペアを生成します。コンテキストが単一ドキュメントの場合、前のコンテキストを踏まえて質問が展開される対話志向の質問回答シーケンスを作成し、カスタマーサービスや社内相談におけるやりとりをシミュレートします。一方、相互参照された複数ドキュメントの場合は、複数の情報源を統合することが求められる質問を生成し、規制対応分析や技術的なトラブルシューティングに必要な多ソース推論を促します。本システムには、完全な推論チェーン(根拠となる情報の連鎖)が裏付け証拠として与えられ、そこから証拠によってのみ答えられる質問回答ペアが生成されます。これにより、複数のエンタープライズドキュメントをまたいで情報統合が必要な訓練サンプルが作成され、従業員が多様な組織内情報源を統合して正確な回答を提供する実際の現場状況を忠実に反映します。
- (3)ディストラクター統合:検証システムが、複数の類似ドキュメントが存在する実際のエンタープライズ環境を訓練データに反映させるために、各訓練サンプルにはディストラクタードキュメントが追加されます。高度な埋め込み技術を用いて、訓練コレクション内の各ドキュメントに対し、ソースドキュメントと高い意味的類似性を持つ最大3つのディストラクタードキュメントを選定します。これらのディストラクタードキュメントは、ソースドキュメントとテーマ的な要素を共有していますが、質問に答えるために必要な具体的な情報は含んでいません。このディストラクタードキュメント追加プロセスにより訓練データの複雑性が向上し、検索結果や文書リポジトリ内で、関連文書や非関連文書が同時に出現する多様なシナリオにも対応できる、より堅牢な検証モデルの構築が可能となります。
3.2 戦略的優位性
本手法は、エンタープライズ向けAI検証システム導入において、次の3つの重要な優位性を提供します。
- (1)AIの強みを最大限に活用:AIシステムに本来得意でない分類タスクを強いるのではなく、その優れたテキスト生成能力を活用します。これにより、より高品質な訓練データを自動生成でき、より信頼性の高い検証モデルの構築が可能となります。
- (2)包括的な訓練シナリオの構築:本システムは、対話型のやりとりから複数情報源を用いた分析的推論まで、多様な訓練サンプルを自動生成します。これにより、エンタープライズにおけるAI活用の幅広い用途をカバーした訓練データの構築が実現します。
- (3)エビデンスのトレーサビリティを保証:生成される質問は、特定の文書セクションに基づいて作成されるため、根拠の所在が常に明確です。これにより、訓練された検証モデルでは、企業の説明責任やコンプライアンス要件で求められる正確な出典提示が実現できます。
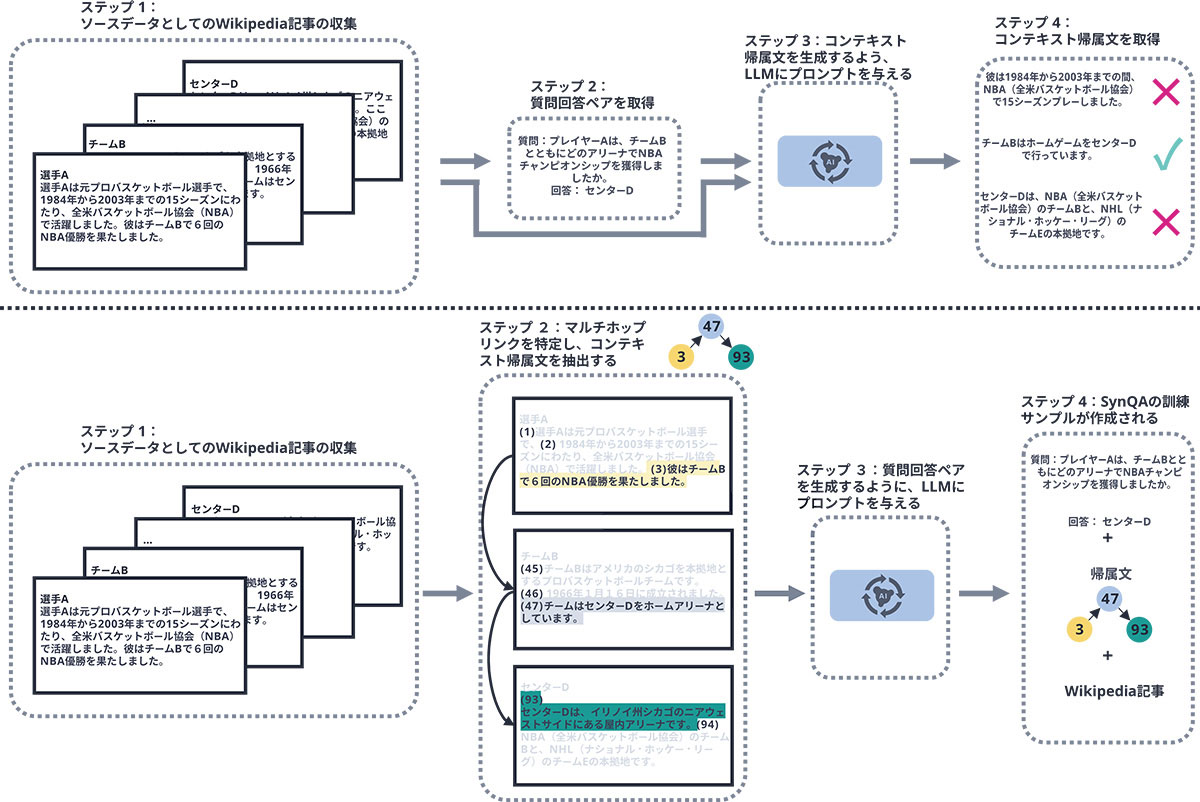
図2の上部は、 ベースライン手法による合成帰属データ生成フローのイメージです。コンテキスト及び質問回答ペアを入力して、LLM に回答を裏付ける文を特定させ、それを用いてより小規模なアトリビューションモデルを訓練します。しかし、この判別的アプローチでは、LLM が分類タスクを苦手とするため、ノイズの多い訓練データになりやすいという課題がありました。一方、図2の下部は、データ生成パイプラインが次の4ステップでLLMの生成能力を活用する本手法のフローのイメージであり、これによりこれらの課題を解決しました。
- (1)ソースデータとしての記事の収集
- (2)文間の連鎖(ホップ)を作って複数記事をまたぐコンテキストアトリビューションを抽出
- (3)これらコンテキスト帰属文のみをLLMにプロンプトして質問回答ペアを生成
- (4)生成された質問回答ペア、そのコンテキスト帰属文、関連するディストラクターを追加した元記事を含む最終的な訓練サンプルの作成
 拡大する
拡大する4. LLM エクスプレーナーの適用と評価
本研究では、LLMエクスプレーナーのソースアトリビューション技術について、その実用性と性能上の利点を明らかにするため、複数のシナリオで包括的な検証を実施しました。評価では、LLMエクスプレーナーモデルを主要な2つの代替手法と比較しました。
- (1)大規模ゼロショットAIシステム:これは現在の業界標準を代表する手法であり、Llama 70B2)のようなパラメータ数700億規模の巨大AIモデルを、特別な追加訓練なしにそのまま利用します。この方法は汎用性が高い一方で、非常に大きな計算資源を必要とします。
- (2)手動アノテーションによる訓練手法:従来の方法であり、高コストな人的監督のもと訓練データを作成します。アノテーションに充てる予算が豊富な組織において確立されたアプローチです。
4.1 評価フレームワークと指標
エンタープライズ向けAI検証システムでは、「正しい情報源の識別精度」「関連するエビデンスの網羅性」「全体的な信頼性」という3つの重要な性能要素のバランスが求められます。本研究では、ソースアトリビューション(根拠帰属)に適応した標準的な評価指標を用いてシステム性能を測定しました。
- (1)精度(Precision):AIが特定したソースのうち、実際にAI生成コンテンツを裏付けているものの割合を示します。システムの信頼性を示す指標であり、ユーザーの時間を浪費する誤った根拠提示(偽陽性)を減らすのにも役立ちます。
- (2)再現率(Recall):システムによって正しく特定された関連ソースの割合を示します。網羅性を測定する指標であり、エビデンスを包括的にカバーできていることを保証します。
- (3)F1スコア:精度と再現率を組み合わせたバランスの取れた指標であり、エンタープライズでの導入意思決定に向けてシステムの総合的な有効性を評価します。
4.2 自動評価の結果
タスクごとに結果を説明します。
- (1)直接的な質問回答の検証:大規模ゼロショットシステムと比較した場合、NECの10億パラメータモデルは、Llama 70Bの95.5%に対して96.1%のF1スコアを達成しました。この際、必要とする計算資源はLlama 70Bの70分の1で済みます。これにより、帰属クエリ実行時の非常に大きなコスト削減効果が見込まれます。
- (2)会話型サポートシステム:マルチターン対話シナリオにおいて、LLMエクスプレーナーのアトリビューションモデルは91.3%のF1スコアを達成しました。これは、70倍大きいゼロショットシステムの88.1%を上回っており、リアルタイムでのお客様対応アプリケーションでも高い有効性を示しています。
- (3)クロスドメイン汎用化:LLMエクスプレーナーは、訓練データとは異なる種類のコンテンツに対しても高い汎用化性能を示しました。これはエンタープライズにおける用途において重要な要件です。会話シナリオにおいて、LLMエクスプレーナーは91.3%のF1スコアを記録し、70倍大きいLlama 70Bモデルの88.1%を上回りました。更に、本研究での自動データ生成アプローチにより、高速かつ高精度なLLMエクスプレーナーモデルを、特定のビジネス領域向けに容易に作成することが可能です。
4.3 ユーザースタディの結果
- (1)ユーザースタディの設計:ソースアトリビューション技術がエンドユーザーの生産性に与える実際の効果を検証するため、12名の参加者を対象とした対照実験を実施しました。参加者には質問、AI生成の回答、及びそれを裏付けるドキュメントが提示され、回答の正誤判定を行ってもらいました。本スタディでは、(1)アトリビューションなし(アライメントなし)での手動検証、(2)基本的なゼロショットアトリビューションのハイライト(Llama 70B)による検証、(3)LLMエクスプレーナーのアトリビューションシステム(SynQA)による検証、という3つのシナリオを比較しました。学習効果を防ぐために順序を調整した厳密な被験者内デザインを適用することで、すべての条件において検証のスピードと精度の両方を測定し、AI生成コンテンツの検証における実運用上の有用性を評価しました。
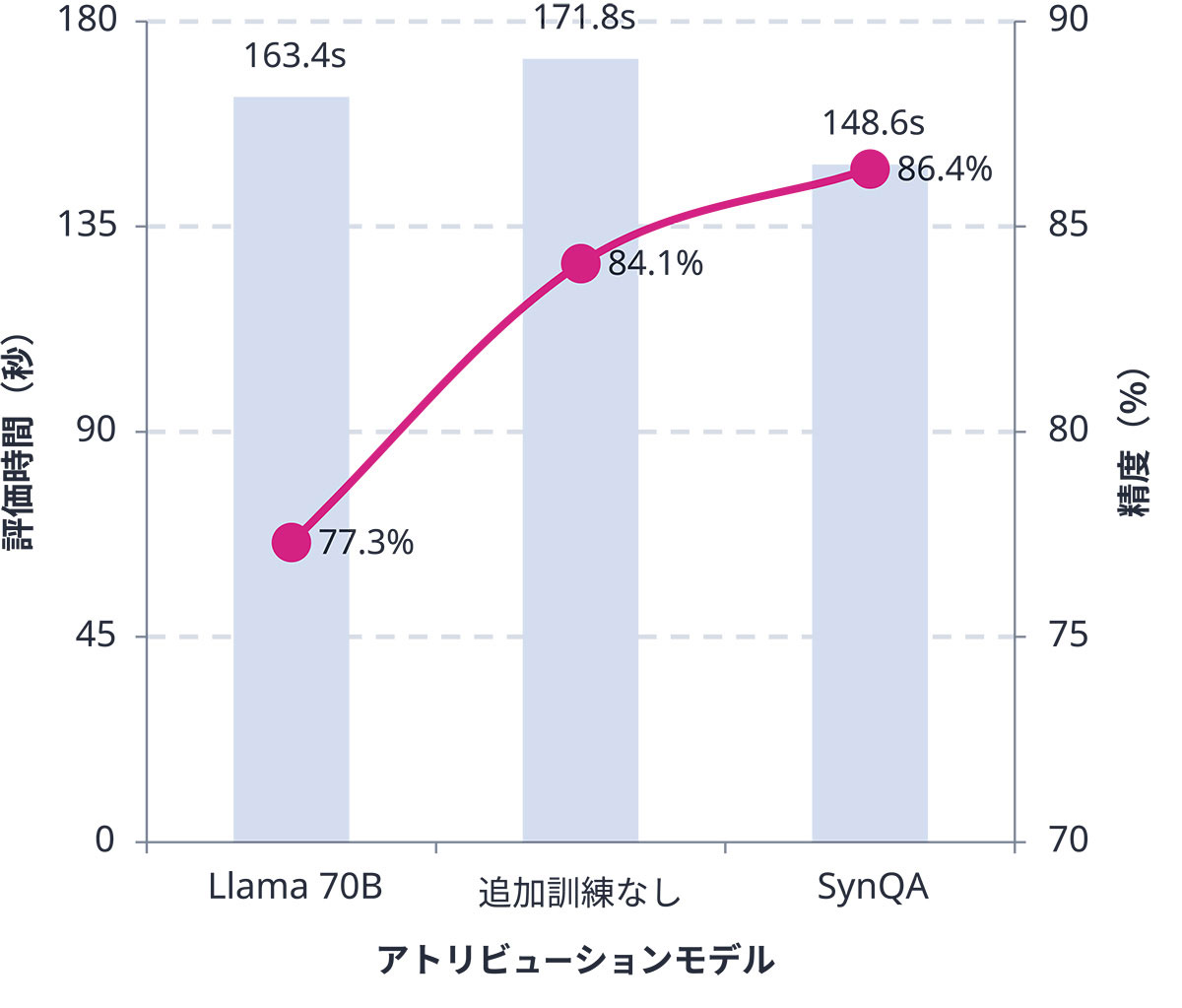
- (2)顕著なパフォーマンス向上:LLMエクスプレーナーを利用することで、検証作業を行うユーザーの生産性が大幅に向上しました。LLMエクスプレーナーを使った場合の平均検証時間は148.6秒で、支援のない手動検証(171.8秒)よりも13%短縮され、大量処理が求められるエンタープライズ環境において大きな効率化が実現できました。更に、検証の正確性もLLMエクスプレーナーでは86.4%と、手動検証(84.1%)や基本的なゼロショットアトリビューション(77.3%)を上回りました(図3)。このような検証時間の短縮と精度向上の両立により、企業はより多くの検証業務を効率的かつ確実にこなし、コンプライアンス上の問題や業務上のミスのリスクも減少させられるという、明確なビジネス価値が示されました。
 拡大する
拡大する4.4 LLMエクスプレーナーのエンタープライズ価値
信頼性の高い検証結果は、ソースアトリビューション技術を導入する組織にとって、明確で測定可能なビジネス上のメリットに直結します。LLMエクスプレーナーは、従来のLLMと比較して計算コストを98%以上削減しながら、高精度を維持します。この効率性により、特別なインフラを必要とせず、標準的な業務用ハードウェアでの導入が可能です。また、訓練データを自動生成する機能により、これまで多大な費用と数カ月を要していた手動アノテーション作業が不要となります。こうした仕組みによって、法規制対応から技術文書の検証まで、さまざまなエンタープライズでの用途において高いパフォーマンスを維持しつつ、コストと工数を大幅に削減できます。
5. むすび
LLMエクスプレーナーによる自動化されたソースアトリビューション技術は、企業がAIによる生産性向上のメリットを享受しつつ、ミッションクリティカルな運用に必要な説明責任や検証基準も維持できるよう支援することで、エンタープライズ向けAI導入における重要な課題を解決します。自動学習データ生成や高効率なLLMエクスプレーナーモデルの開発を通じて、従来のAI検証システムで問題となっていたコストや複雑さの障壁を排除し、現実的なソリューションを実現できます。本技術は、従来の高コストな大規模AIソリューションや手動アノテーション手法と比較して、標準的なエンタープライズ向けハードウェア上でも効率的に動作し、優れた性能を発揮します。
LLMエクスプレーナーは、70倍規模のゼロショットシステムと比較して一貫して高いパフォーマンスを示し、幅広いコンテンツタイプや業務プロセスを持つ組織にとって不可欠なクロスドメイン汎用化能力も実証しています。更に、システムが高品質な学習データを自動生成するため、手動アノテーションを必要とせず、各部門や新たなコンテンツ領域への迅速な展開も可能です。これらの特長により、規制された環境、お客様対応領域、検証や説明責任が重視されるミッションクリティカルな業務へのAIシステム導入が容易となります。
参考文献
 Gorjan Radevski et al.: On Synthesizing Data for Context Attribution in Question Answering, the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025.7
Gorjan Radevski et al.: On Synthesizing Data for Context Attribution in Question Answering, the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025.7執筆者プロフィール
シャバス サイード
NEC Laboratories Europe
Senior Research Engineer
NEC Laboratories Europe
Senior Research Engineer
キャロリン ローレンス
NEC Laboratories Europe
Manager & Chief Research Scientist
NEC Laboratories Europe
Manager & Chief Research Scientist
キリル ガシュテオヴスキ
NEC Laboratories Europe
Senior Research Scientist
NEC Laboratories Europe
Senior Research Scientist
岩井 孝法
NEC Laboratories Europe
Assistant General Manager
NEC Laboratories Europe
Assistant General Manager
伊東 邦大
セキュアシステムプラットフォーム研究所
セキュアシステムプラットフォーム研究所
荒木 俊則
AIテクノロジーサービス事業部門
シニアマネージャー
AIテクノロジーサービス事業部門
シニアマネージャー


