Japan
サイト内の現在位置
dotData Feature Factory
特徴量をアセット化し全てのAI/BIを強化dotData Feature Factoryとは
dotData Feature Factoryは、dotData独自の特徴量自動設計技術を中心に、データエンジニアリングを圧倒的に効率化する機能を提供する製品です。熟練データサイエンティストは仮説検証業務の効率化を、データエンジニアはデータプロダクト(データマート)の構築業務の効率化を実現できます。
また、本製品はPythonライブラリとして提供が可能なため、既存のPython環境、Pythonエコシステムと簡単に統合できます。これにより既存システムとの親和性を保ちながら、ご利用いただけます。



Point1:データエンジニアリングを圧倒的に効率化
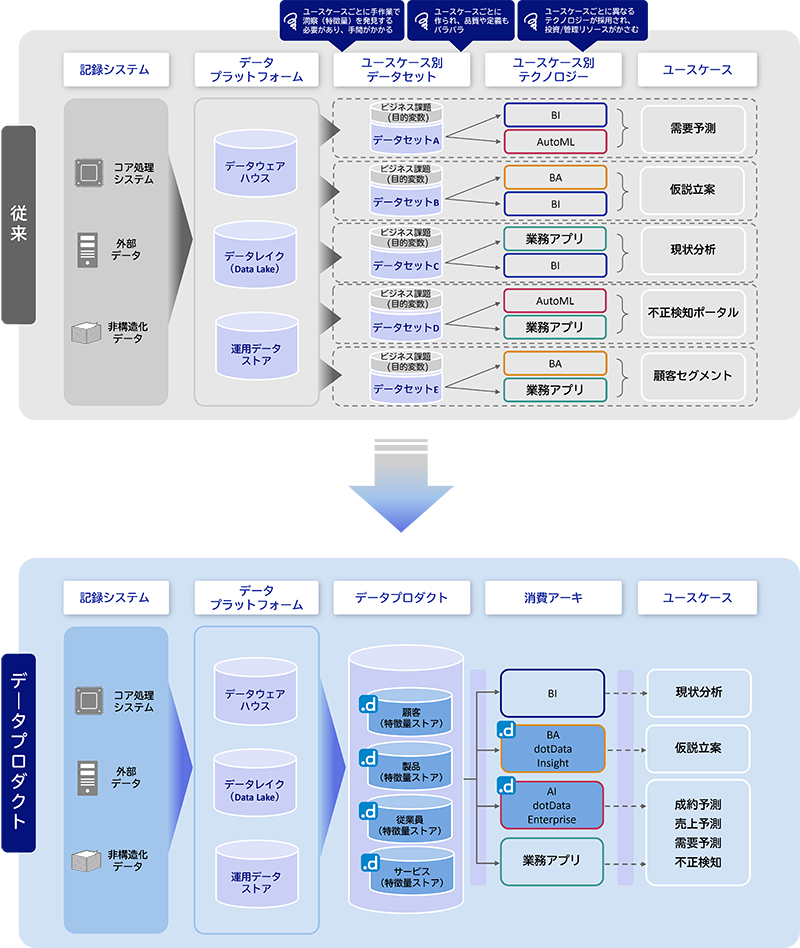
良質なデータ活用を実現するには、業務システム都合でモデル化された蓄積データから、ビジネス的に意味のある特徴量データへ変換し、消費アーキ(BI/BA/AI)で分析する必要があります。この変換は、ビジネス面とデータエンジニアリング両面を理解したデータエンジニアが多大な工数を費やして実施してきました。
dotData独自の特徴量自動設計技術は、これらの変換処理を圧倒的に効率化します。この技術では、大規模で複雑な関連性を持つデータの関係性を自動で分析し、人間のバイアスに捉われることなく透明性の高い特徴量をわずか数時間で抽出します。
dotData Feature Factoryは、プログラム的に特徴量空間を定義することで、手作業では不可能な広い範囲の特徴量仮説を自動生成し、データ中心のアプローチを可能にします。dotDataの技術によって、データエンジニアリングを圧倒的に効率化するとともに、高度なデータ活用の拡大を実現することが可能になります。
Point2:すべてのAI/BIを強化
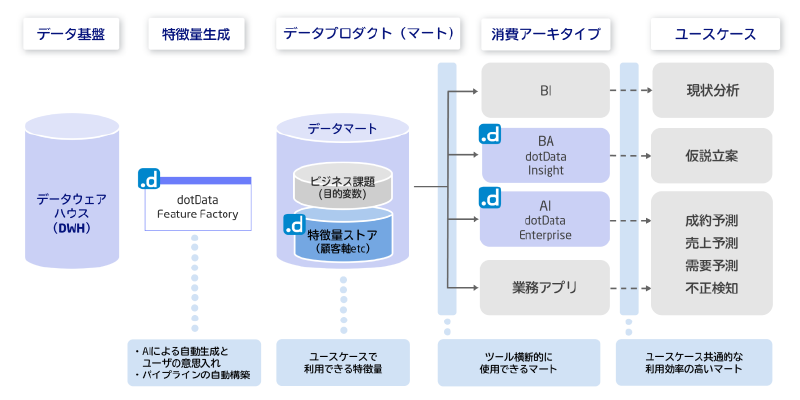
新しい特徴量を、本番環境で利用可能な特徴量パイプラインを自動生成し、目的別に加工されたデータ(特徴量)を供給するハブとして、データ活用、AI、ビジネスインテリジェンス(BI)、ビジネスアナリティクス(BA)といった、全てのデータアプリケーションを強化します。
Point3:特徴量をアセット化
特徴量設計は、簡単なSQLクエリを書くだけではなく、ETLやデータクレンジング、特徴量変換など、複雑なデータ操作と変換を繰り返し作業によって導き出すプロセスです。発見した特徴量はデータマートや特徴量ストアに蓄積することができますが、特徴量設計のプロセスは、ほとんどのケースで蓄積、管理されずに、捨てられてしまいます。
dotData Feature Factoryは、特徴量設計のプロセスを蓄積し共有することで、属人化しやすいデータ変換や特徴量抽出のノウハウを再利用可能なアセット化します。このアセットは各分析で共通的に利用できる特徴量データ(データプロダクト)として、企業内外における分析の効率化とともにユースケースの拡大を強力に支援します。
主な特長
複数ソース、複数テーブルの特徴量設計
dotData独自の特徴量自動設計技術が、ターゲットテーブル(目的変数)、ソーステーブル(入力テーブル)、テーブル間の関係(エンティティリレーション)を指定するだけで、数値、カテゴリ、時系列、地理空間などのマルチモーダルなデータセットから、機械学習モデルの予測力を高め、ビジネスインサイト(洞察)をもたらす新しい特徴量を発見します。
特徴量設計を再利用可能なアセット化
スキーマやエンティティリレーションといったデータのメタ情報、データクレンジングなどの前処理、データ加工と特徴量変換の全てのステップを分析データベースへ記録し、特徴量に関する「ノウハウ」を再利用可能なアセットとして蓄積し、組織やチームでのデータ活用やAI開発の生産性を圧倒的に向上します。
データ加工&データクレンジング
不正なデータ値、欠損値、外れ値、カテゴリ値の正規化、レコードの重複などを自動的に検出し、ソースデータをクレンジングします。これにより、時間がかかり、またエラーが発生し やすいデータ加工の作業を最小化し、特徴量と予測の品質を最大化します。
既存のPython環境、Pythonエコシステム上で利用可能
dotData Feature Factoryは、Jupyter Notebook、Databricks、Azure Machine Learning Studioなど、ユーザーが利用しているPython環境上にインストール可能で、データフレームなどの標準的なインターフェースを通じて、既存の分析環境を変更せずに利用できます。
企業データにおけるスケーラビリティ
dotData Feature Factoryは分散計算技術によって、大規模データに対するスケーラビリティを備えて構築されています。これにより、数十のテーブル、数千の列、数十億の行を処理することができます。企業の大量のデータを処理する際に、高度な分散計算技術で通常必要となる煩雑な設定や調整は必要ありません。
本番品質の特徴量パイプラインを自動生成
dotData Feature Factoryで設計された特徴量は、本番品質・スケーラビリティをもった特徴量パイプラインを自動生成可能です。分析環境で発見した価値のある特徴量を、直ちに本番環境で運用することができます。
dotData Feature Factoryの関連サービス
データ管理基盤アジャイル構築サービス(DPAS)
モデルの精度改善や新たな知見発見などを目的とした分析の試行錯誤過程にあわせてデータを整備しながら、アジャイルでAIデータ管理基盤を構築するサービスです。
dotDataのAI・データ分析プラットフォーム
企業におけるAIとデータの活用において最も重要かつ難易度が高いのは、ビジネスの課題を解決するための洞察、すなわちデータから「特徴量」を見出すことです。dotDataの製品は、世界をリードする特徴量自動設計技術を核に、AIによる特徴量の導出がビジネスに新たな洞察をもたらし、企業のDXを推進します。