Japan
サイト内の現在位置を表示しています。
Nuberu:共有プラットフォームによる高信頼性のRAN仮想化
Vol.75 No.1 2023年6月 オープンネットワーク技術特集 ~オープンかつグリーンな社会を支えるネットワーク技術と先進ソリューション~ PDFで閲覧する
PDFで閲覧するRANの仮想化は、次世代モバイルネットワークの鍵になるテクノロジーになるとみられています。しかし、無線ダイナミクスに特有なコンピュータ処理の揺らぎや、共有コンピューティングインフラにおけるリソース競合などにより、専用プラットフォームから共有プラットフォームへの移行には膨大な費用がかかる可能性があります。本稿では、Nuberuという、NECが共有プラットフォーム向けに設計した、4G/5G DU(分散ユニット)のための最新のパイプラインアーキテクチャを紹介します。Nuberuが目標とするのは、信頼性を高めることです。つまり、コンピューティング能力が不足している場合でも、DUとユーザーとの同期を維持する最小限の信号セットを保証し、そしてこの条件下でネットワークスループットを最大化できるようにします。そのために、厳格なデッドライン制御、ジッター吸収バッファ、予測的HARQ、輻輳制御などの手法を用います。
1. はじめに
これまで物理的に組み込まれたASICで実現されてきたRAN(無線アクセスネットワーク)を仮想化することは、5G以降の次世代モバイルシステムの先頭を行く取り組みになります。通信事業者が主導するO-RAN ALLIANCEなどの新たな構想は、市場と研究コミュニティーを触発して、NFV(ネットワーク機能仮想化)の柔軟性とコスト効率をモバイルネットワークの最先端の現場に持ち込める画期的なソリューションを探すように拍車をかけてきました。
図1にvRANのアーキテクチャを示します。BS(基地局)は、スタックの最上位層をホストするCU(中央ユニット)、PHY(物理層)をホストするDU(分散ユニット)、増幅やサンプリングなどの基本的な無線機能をホストするRU(無線ユニット)に分かれます。コスト削減のため、vRANはクラウドプラットフォームに頼ることがあります。このプラットフォームは、PHYなどの仮想化機能をホストするため、共有されたコンピューティングリソース(主にCPU、これに加え抽象化レイヤの仲立ちによるハードウェアアクセラレーターなども含む)のプールで構成されます。
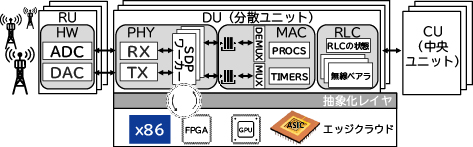
しかし、共有されたコンピューティングプラットフォームは、DUにとっては過酷な環境となってしまいます。なぜなら、専用プラットフォームが提供する予測可能性を、高い柔軟性及びコスト効率と引き換えにすることになるからです。CUの仮想化にはリージョンごとのクラウドが適している一方、仮想化されたDU(vDU)(ここではvPHY)は、エッジにおいて高速で予測可能な演算を必要とします。
説明を簡単にするために、周波数分割方式に焦点を当てることにします。この方式では、UL(アップリンク)とDL(ダウンリンク)の伝送が、5Gの基準ヌメロロジー (μ=0、3GPP TS 38.211準拠)において、異なる周波数帯で同時に発生します。1つのSF(サブフレーム)当たりに1つのTTI(送信時間間隔)が生まれ、SF1つの時間長は1msです。図2は、典型的な4G/5G DUプロセッサの基本動作を示したものです。各TTI nにおいて、ワーカーはタスクのパイプラインで構成されるDUジョブ(以下、DUタスク)を開始します。DUタスクは、次の(1)~(5)のとおりです。
- (1)データの処理
- (2)UL SF nで運ばれるチャネルの制御
- (3)DL SF n+Mで送られたUL/DL無線グラントのスケジューリング
- (4)データ処理
- (5)DL SF n+Mのチャネル制御
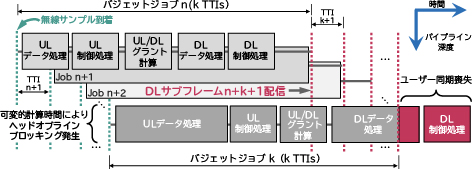
ワーカーは、タスクスケジューラーが割り当てたコンピューティングリソースを使用して、スレッドでDUジョブを実行します。そして図2に示すように、複数のワーカーが、1つのDL SFと1つのUL SFを各TTIで扱えるよう、DUジョブを並列処理します。3GPPでは、eMBBトラフィックにおけるUEとCUの間の片道遅延バジェットを4msに設定しています1)。したがって、Mに対して厳しい制約があり、各DUジョブを約M-1msで処理するというコンピューティング時間バジェットが課せられています(通常M=4)。
実際に、各TTI内でDUジョブを完了させることは、BSとユーザー間での同期を保ち、信頼性を確保するうえで極めて重要です。しかし、DUタスク内の大量の計算を要する操作のいくつか、例えばFEC(前方誤り訂正)などが課題となります。こうした操作には相当の処理時間と、現在市場で採用されているソリューション、すなわち専用のハードウェアによるアクセラレーションが必要となり、そもそも仮想化をRANにとって魅力あるものにしている、柔軟性とコスト効率という根拠が薄くなってしまいます。
2. Nuberuのデザイン
このような課題の解決に向けて、NECはNuberuを開発しました。Nuberuは共有コンピューティングプラットフォームに適した、4G/5G DU用の新しいパイプラインアーキテクチャです。Nuberuのデザインは1つの目標を追求しています。それは、同期のための重要な信号を備えたMVSF(ミニマムバイアブルサブフレーム)を構築し、コンピューティング能力が不足する間もまず信頼性を提供するためすべてのTTIを優先的に制御して、この条件が満たされた場合、ネットワークのスループットを最大化することです。
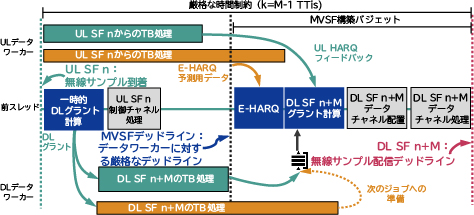
このために、データ処理タスクが完了していなくても、すべてのDUジョブにMVSFの構築を開始するデッドラインを設定しました。図3に黒の点線で示したこのデッドラインは、最終のジョブ完了デッドライン(赤の点線)までにMVSFの処理に十分な時間が確保できるよう設定しています。時間が確保できるのは、データ処理タスクと異なり、MVSFの構築に関連するタスクは処理に時間がほとんどかからないうえ、必要なおおよその時間を予測できるからです。構築関連タスクの処理を効率良く行うため、MVSFの構築に必要な情報が時間通りに準備され、コンピューティング能力が揺らいでいる間でもネットワークスループットが最大化されるように、データ処理タスクを切り離す必要があります。こうしたことから、次の技術を適用しています。
- (1)DLデータチャネルタスクを処理するための方針
- 1)2段階のDL無線スケジューリングというアプローチを採用しました。
- 図3に示すように、DUパイプラインのできるだけ早い段階で、一時的なDLグラントを発行します。専用ワーカーがこれらのグラントを別々のスレッドで処理(エンコードや変調など)し、結果のデータをバッファに保存します。
- MVSFデッドラインに来たら、その時点においてバッファのなかで利用可能な、正常に処理されているデータに基づいて、最終的なDLデータのグラントを計算します。ジョブで生成されたグラントのうち、処理の間に合わなかったものは、後のジョブで遅れて処理されます。
- 2)遅延するDLデータグラントの数を少なくするために、一時的なスケジューラーが許可するDLデータの量を、コンピューティングリソースの可用性に合わせてDLデータグラントの流れを適合させる輻輳コントローラーが調整します。このため、Nuberuの無線スケジューラーは、DLの輻輳ウィンドウ(
 )を使用して、DLグラントの流れを調整します。NuberuではAIMD(additive-increase/multiplicative-decrease)アルゴリズムを採用しており、輻輳が検出されないかまたは最大PRB(物理リソースブロック)容量に達しない限り、 はDUジョブ
)を使用して、DLグラントの流れを調整します。NuberuではAIMD(additive-increase/multiplicative-decrease)アルゴリズムを採用しており、輻輳が検出されないかまたは最大PRB(物理リソースブロック)容量に達しない限り、 はDUジョブ ごとにαPRBずつ増加します。輻輳が検出された場合、 はβ≤1として
ごとにαPRBずつ増加します。輻輳が検出された場合、 はβ≤1として ずつ乗算的に減少します。Nuberuは、エンコードされたTB(転送ブロック)のバッファに、vDUのPRB容量のλ>0倍以上データが入っている場合、輻輳があると推定します。
ずつ乗算的に減少します。Nuberuは、エンコードされたTB(転送ブロック)のバッファに、vDUのPRB容量のλ>0倍以上データが入っている場合、輻輳があると推定します。
- 1)
- (2)ULデータチャネルタスク処理のための方針
- 1)専用のワーカーが、各UL SFによって運ばれるULデータを分離されたスレッドで処理(復調、デコードなど)します。
- 2)MVSFのデッドライン上では、図3に示すように、E-HARQ(早期HARQ)メカニズムが、ワーカーからのフィードバックに基づいて、ULデータの復号可能性を推定します。これにより、ULデータ処理タスクが時間通りに完了していなくても、MVSFの構築に必要な無線情報を推定できます。E-HARQアプローチの鍵となる考え方は、ターボ符号とLDPC符号の両方で使用される確率伝搬アルゴリズムによって有機的に生み出される外部情報のコンセプトにあります。これらのコーディング手法に関する詳細な情報は、文献2)を参照してください。要約すると、確率情報は、LLR(対数尤度比)、
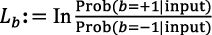 にエンコードされます。ここで、「input」は復号器内の各デコーディングノードiのすべての入力を指し、 bは情報シンボル(ビット)を表します。反復コーディングの鍵となるのは情報シンボルの事後LLRの配列であり、これは復号器のデコーディングノード間で反復kごとに交換され、各ノードは他のノードが計算した情報を活用することができます。反復ごとにビット推定を改善するために、異なるノードは自身から発生したものではない確率情報を交換する必要があります。外部情報のオリジナルコンセプトは、現行のコードにより導入された冗長な情報に依存した情報コンポーネントを識別するために考案されました。このような外部LLRは、事後LLRを、次の反復での入力として使う事前LLRに変換するために使用されます。反復デコーディング中に起きる外部情報の平均的大きさの変化により、復号可能なデータの識別が容易になります。したがって、外部情報のパターンを観察することにより、入力データを次の3つのタイプに分類するシンプルな予測器を構築できます。不確実性が高すぎる場合は「UNKNOWN」、データが正常にデコードされると予測器で確信できる場合は「DECODABLE」、データが正常にデコードされないと予測器で確信できる場合は「UNDECODABLE」となります。
にエンコードされます。ここで、「input」は復号器内の各デコーディングノードiのすべての入力を指し、 bは情報シンボル(ビット)を表します。反復コーディングの鍵となるのは情報シンボルの事後LLRの配列であり、これは復号器のデコーディングノード間で反復kごとに交換され、各ノードは他のノードが計算した情報を活用することができます。反復ごとにビット推定を改善するために、異なるノードは自身から発生したものではない確率情報を交換する必要があります。外部情報のオリジナルコンセプトは、現行のコードにより導入された冗長な情報に依存した情報コンポーネントを識別するために考案されました。このような外部LLRは、事後LLRを、次の反復での入力として使う事前LLRに変換するために使用されます。反復デコーディング中に起きる外部情報の平均的大きさの変化により、復号可能なデータの識別が容易になります。したがって、外部情報のパターンを観察することにより、入力データを次の3つのタイプに分類するシンプルな予測器を構築できます。不確実性が高すぎる場合は「UNKNOWN」、データが正常にデコードされると予測器で確信できる場合は「DECODABLE」、データが正常にデコードされないと予測器で確信できる場合は「UNDECODABLE」となります。 - 3)MVSFのデッドラインが来る前に完了(反復)した作業量に依存するE-HARQの予測性能を最大化するために、別の輻輳コントローラーが、UL無線リソースの配分を、利用可能なコンピューティング能力に適応させます。ダウンリンクの手順と同様に、DUユーザーに配分可能なUL PRBの数を制限する輻輳ウィンドウ
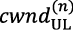 の定義を行います。ここでもシンプルなAIMDアルゴリズムを採用し、輻輳が推定されていない場合には、
の定義を行います。ここでもシンプルなAIMDアルゴリズムを採用し、輻輳が推定されていない場合には、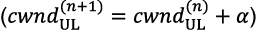 を加算しを増やしていきます。そして輻輳が推定される場合には、β<1として乗算的に
を加算しを増やしていきます。そして輻輳が推定される場合には、β<1として乗算的に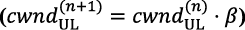 へ減少させます。ULのワークロードから輻輳を推定する一般的な手法は、MVSFデッドライン前にULデータワーカーの作業が完了しなかった場合は、毎回、合図を送るというものです。しかし、この方法では、はっきりとCRC確認をするかなり前にTBの復号可能性を推論できるという、E-HARQメカニズムが備える予測能力をうまく使い切れません。これとは逆に、NECのアプローチなら、E-HARQが確実な予測を提供できない、例えばUNKNOWNが出力されるような場合でも、いつでも輻輳を推定できます。UNKNOWNは、ULデータワーカーが十分な回数のデコーディング反復をデッドライン前に実行できず、その結果、予測の不確実性が大きくなりすぎる時に毎回発生します。
へ減少させます。ULのワークロードから輻輳を推定する一般的な手法は、MVSFデッドライン前にULデータワーカーの作業が完了しなかった場合は、毎回、合図を送るというものです。しかし、この方法では、はっきりとCRC確認をするかなり前にTBの復号可能性を推論できるという、E-HARQメカニズムが備える予測能力をうまく使い切れません。これとは逆に、NECのアプローチなら、E-HARQが確実な予測を提供できない、例えばUNKNOWNが出力されるような場合でも、いつでも輻輳を推定できます。UNKNOWNは、ULデータワーカーが十分な回数のデコーディング反復をデッドライン前に実行できず、その結果、予測の不確実性が大きくなりすぎる時に毎回発生します。
- 1)
3. 評価
次に、Nuberu試作機を実験で評価します。
最初に、2基のDUを用いて実験を設定します。このDUは、完全に3GPPに準拠した基地局のオープンソース実装であるvanilla srsRAN(M=4)を利用します。それぞれのDUは、srsUEで実装された1つのユーザーを関連付けし、5基のIntel Xeon x86コア(クロック1.9GHz)を共有するLinuxコンテナ上で仮想化しました。
この実験では、1基のDU(vDU 1)ができるだけ多くのデータを送受信します。一方、2基目のDU(vDU 2)は、異なるパラメータを用いたランダムなプロセスに従ってトラフィックを送受信します。このパラメータは、図4の下部に示した平均(線)と分散(網掛け部)で、正規分布に従うコンピューティング作業量を発生させます。vDU 2の負荷変化が大きいほど、vDU 1が利用可能なコンピューティング能力の変動も大きくなります。
図4上部では、vDU 2によって生成される作業量の関数として、vDU 1の相対的なネットワークスループットを黄色(「基準線」)で示しています。この図から、vDU 1のパフォーマンスがすぐに低下することがわかります。この理由は、両方のvDUが同じCPUプールを共有しているため、vDU 2の需要がピークに達した時に、vDU 1がCPUリソースの不足に陥ることがある、ということです。その結果、DUジョブを実行するvDU 1ワーカーが、対応するDL SFを送り出すデッドラインを乱してしまい、図2の下部に示すように、ユーザー側には同期の喪失やスループットの低下が生じます。
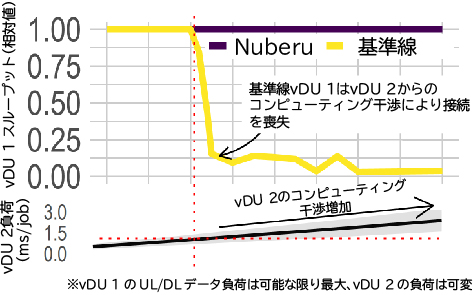
これに対して、図4の紫色の線が示すように、Nuberuではコンピューティング能力の激しい変動があるにもかかわらず、最大スループットの維持が可能です。
参考文献
- 1)3rd Generation Partnership Project (3GPP): 3GPP TR 38.913; Technical Specification Group Radio Access Network; Study on Scenarios and Requirements for Next Generation Access Technologies; (Release 17). Technical Report, 2022
- 2)Yang Sun and Joseph R Cavallaro: A flexible LDPC/turbo decoder architecture, Journal of Signal Processing Systems 64, 1–16, 2011
執筆者プロフィール
GARCIA-SAAVEDRA Andres
NEC Laboratories Europe
6G Networks
Principal Research Scientist
NEC Laboratories Europe
6G Networks
Principal Research Scientist
COSTA PEREZ Xavier
NEC Laboratories Europe
6G Networks
Manager
NEC Laboratories Europe
6G Networks
Manager

