Japan
サイト内の現在位置
【Oracle×生成AI 第5回】これからのAIアプリを支える「記憶管理」とは
生成AIを業務で使おうとすると「毎回同じ説明が必要になる」「前回のやり取りが引き継がれない」といった不便さを感じることがありませんか。このような使いにくさがあると、便利な生成AIも業務ではなかなか継続利用されません。そこで重要になるのが「記憶管理」です。本記事では、生成AI活用に必要な記憶管理について説明します。それを支える基盤としてOracle AI DatabaseやOCIがどう役立つのかについてご紹介します。
目次
1 はじめに
生成AI活用を進める企業は増えており、PoCを通じて効果が見え始めているケースも少なくありません。特に、FAQ対応や文書要約、問い合わせ一次対応といった比較的シンプルなユースケースでは、すでに一定の成果が表れ始めており、「生成AIは実務に使える」という手応えを得ている企業も増えているのではないでしょうか。
一方で、現場で継続的に活用したり、複数のAIエージェントが連携するような複雑なユースケースに踏み込んだりすると、PoCでは見えにくかった課題が浮かび上がってきます。単発のやり取りでは問題なくても、継続利用では文脈の引き継ぎや情報共有が不十分となり、期待した回答や使い勝手が得られない場面が出てきます。
こうした状態が続くと、手戻りや確認の重複が積み重なり、業務効率化どころか利用者の負担を増やしてしまうこともあります。その背景には、業務の前提、途中経過、判断理由といった情報──これを記憶と呼びます──を、生成AIアプリケーションが継続的に扱いきれていないという問題があります。
このような課題の根幹は生成AIそのものの性能や操作性の問題だけではなく、生成AIアプリケーションが業務に必要な情報を継続的に扱うことができる基盤設計になっていないことも一因です。業務に必要な情報として整理し、必要なときに取り出せる形で管理できる基盤を整備することが重要です。
本記事では、生成AIアプリケーションにおけるこうした「記憶の設計」に注目します。そして、記憶管理を支える基盤として、Oracle AI DatabaseやOCIがどのように有効かを見ていきます。
2 記憶が注目されている理由
まずは、ChatGPTといった生成AIを使ったアプリケーション(以後、生成AIアプリケーションと呼びます)において記憶管理が重要になる理由を、2つの典型的な課題から見ていきます。
典型課題①:会話が長くなると、過去の前提が引き継がれない
生成AIとの会話が続くにつれて、過去に共有した内容が十分に反映されなくなるケースです。
生成AIアプリケーションは直近の会話内容を踏まえて応答できるものが多い一方で、やり取りが長くなると、一定以上前の履歴を十分に考慮できないことがあります。その結果、ユーザーはすでに伝えた前提条件や要望をもう一度説明しなければならず、「会話がつながっていない」と感じやすくなります。
例えば、業務上の相談を段階的に進めているにもかかわらず、途中で以前の条件が抜け落ち、前提の異なる回答が返ってくるような状態です。こうした課題は、単発のやり取りでは問題なく見えても、継続的な利用の中で手戻りが増え、業務効率や利用体験を損なう要因となります。

典型課題②:AIエージェントの間で情報が共有されず、回答品質が低下する
複数のAIエージェントを組み合わせて業務を進める場合、それぞれのエージェントが役割に応じた処理を行えるだけでは十分ではありません。ユーザーの目的、確認済みの前提条件、途中経過、判断理由といった情報がエージェント間で適切に共有されていなければ、別のエージェントが同じ確認を繰り返したり、前のやり取りと整合しない回答を返したりすることがあります。その結果、ユーザーからは「連携しているようで連携していない」状態に見え、やり取りの手間が増えるだけでなく、最終的な回答の一貫性や品質も損なわれます。
例えば、売上データの分析支援をエージェントに依頼する場面を考えてみます。データの取得や要因分析といった複数のタスクに対して、各タスクを実行するためのエージェントが連携することで高度な分析を可能となるようなシステムを想定します。
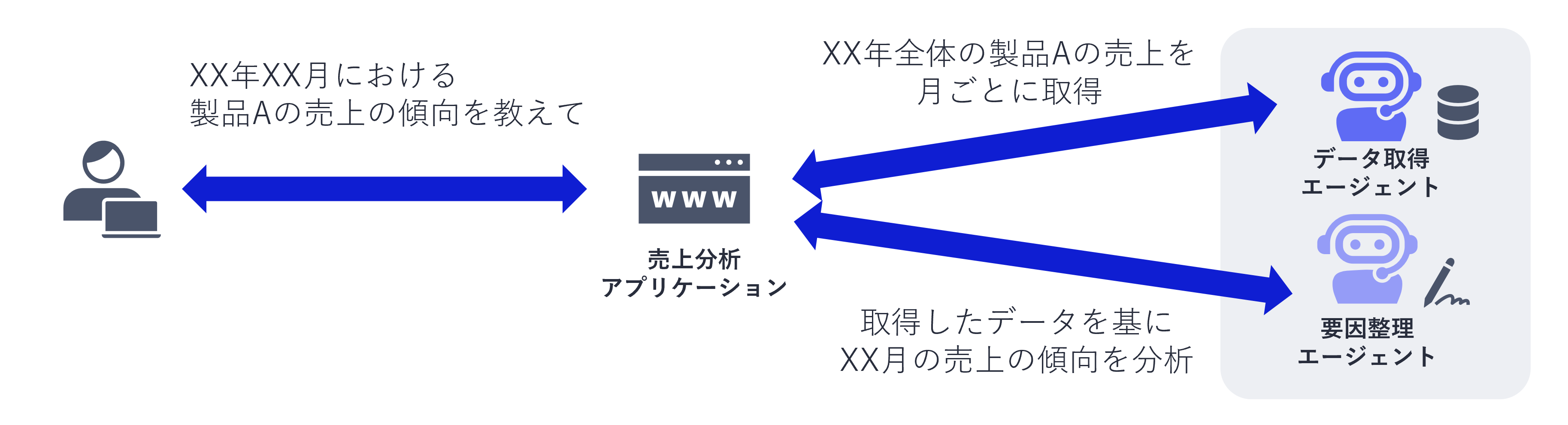
しかし、分析には前提条件があり、それが方向性を大きく左右します。たとえば、「どの指標を重視するのか」「前年同月比で見るのか、前月比で見るのか」「どの地域や商品カテゴリに注目するのか」といった情報が引き継がれなければ、毎回同じ説明や確認を繰り返すことになります。
また、データ取得エージェントがデータを取得しても、「そのデータが何なのか」「なぜそのデータを取得したのか」といった背景情報が次のエージェントに渡らなければ、文脈に沿った一貫性のある分析を行うことが難しくなります。
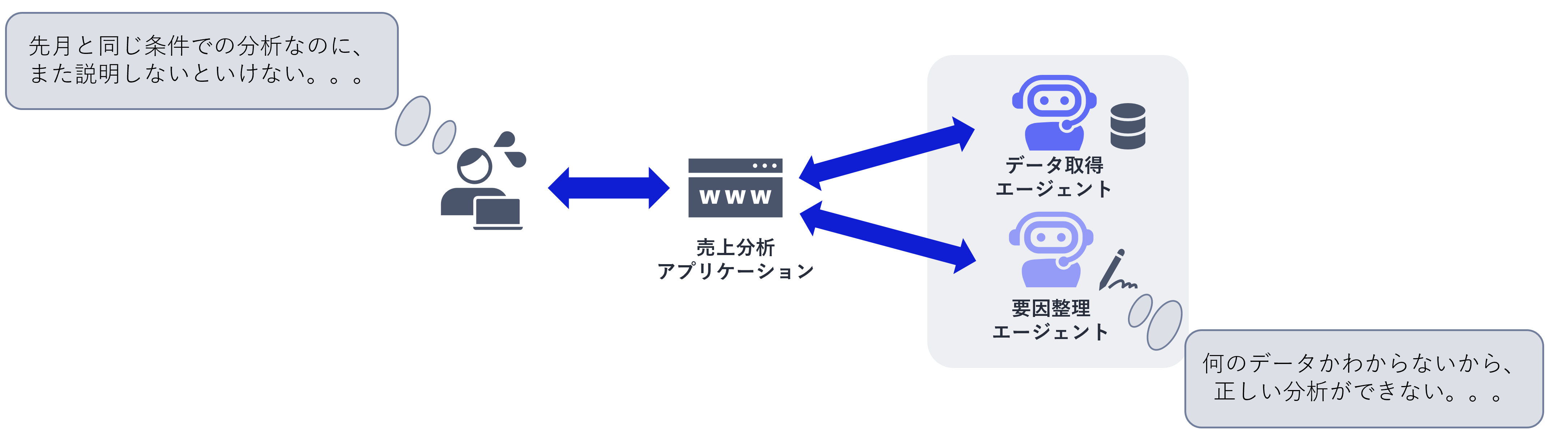
しかしながら、必要になりそうな情報をすべて残し、すべて共有すればよいというわけでもありません。古い条件や不要な途中結果まで参照すると、現在の業務にとってはノイズとなって回答の品質を低下させるだけでなく、処理時間や運用コストの面でも負担が大きくなります。
では、記憶管理があると、何が変わるのでしょうか。
記憶管理が適切に行われていれば、会話や処理の中で得られた情報を単に蓄積するのではなく、「現在有効な前提条件」「確認済みの事項」「途中経過」「判断理由」といった形で整理して保持できます。これを必要なエージェントが必要なタイミングで参照できれば、ユーザーが同じ説明を繰り返す場面は減り、各エージェントも共通の前提に基づいて一貫した処理を進められるようになります。
売上分析の例でいえば、重視する指標や比較の観点、注目する地域や商品カテゴリといった条件が引き継がれることで、データ取得から分析、示唆の整理までが文脈に沿ってつながります。その結果、確認の重複や分析の方向性のぶれが抑えられ、不要な履歴を参照し続けることによる回答品質の低下や無駄な処理負荷も避けやすくなります。
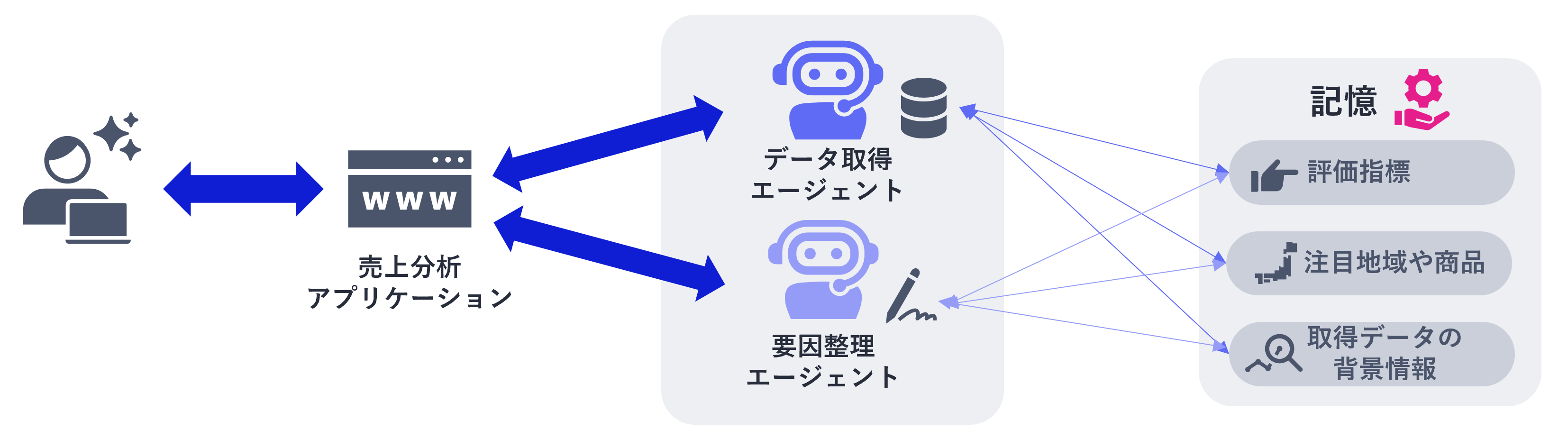
このように、記憶が「ない」ことだけではなく、必要な記憶と不要な記憶が整理されず、業務の中で活用できないことにあります。この問題は売上分析に限らず、問い合わせ対応、保守運用、契約審査、社内ナレッジ活用など、過去のやり取りや前提条件を引き継ぎながら進める業務全般で共通します。
次章では、この「記憶」をさらに掘り下げ、生成AIアプリケーションにとって何を記憶し、どのように扱うべきかを整理していきます。
3 生成AIアプリケーションにおける記憶とは?
記憶は単に「ある」だけでなく、必要なときに使えるよう「整理されている」ことが重要です。
では、生成AIアプリケーションにとって適切な記憶とはどのようなものなのでしょうか。
ここからは、以下の記事を参考に、生成AIアプリケーションにおける記憶の考え方を整理します。
【Developers Summit 2026】Memory Is All You Need:コンテキストの「最適化」から「継続性」へ ~RAGを進化させるメモリエンジニアリングの最前線~ - Speaker Deck
ここでは2つの観点から整理します。
・何を記憶として扱うのか
・その記憶をどのように扱うのか
3.1 何を記憶として扱うのか
まず、人の記憶を思い浮かべてみましょう。
業務上でのやり取りや学習を通じて、さまざまなことを覚えています。しかし一言一句正確に覚えているわけではありません。
重要なのは、次のような「要点」です。
・どこまで話が進んでいて、今の論点は何か
・何が確認済みで、次のステップは何か
・どんな前提や制約があるか
こうした情報を押さえることで、やり取りを中断しても、続きから仕事を進められます。
目的を達成するために必要な情報を、生成AIアプリケーション側で保存し、必要な場面で参照できるようにしたものを、ここでは「記憶」と呼びます。
なお、これはAIモデル自体が再学習することではなく、生成AIアプリケーションが必要な情報を管理する仕組みを指します。
記憶にはいくつかの種類があり、次のように整理できます。
| 記憶の種類 | 特徴 | 記憶の例 |
|---|---|---|
| 短期記憶 | 直近のやり取りや一時的な情報 | 直近の会話履歴 |
| 意味記憶 | 普遍的な知識や定義、ユーザー特有の情報など | 利用者の属性、評価指標 |
| エピソード記憶 | 過去の具体的な経験や出来事など | 過去の会話履歴や分析結果 |
| 手続き記憶 | タスクやプロセスの手順、ルールなど | 承認フロー、システム利用の手順書 |
また、こうした記憶は、種類ごとに適した持ち方が異なります。
たとえば、過去の会話履歴や操作履歴のようなエピソード記憶であれば、時系列を保った形で扱えることが重要です。
一方で、業務ルールや手順書のような手続き記憶であれば、ドキュメントやJSONなど、元の構造を保ったまま保存・参照できることが求められます。
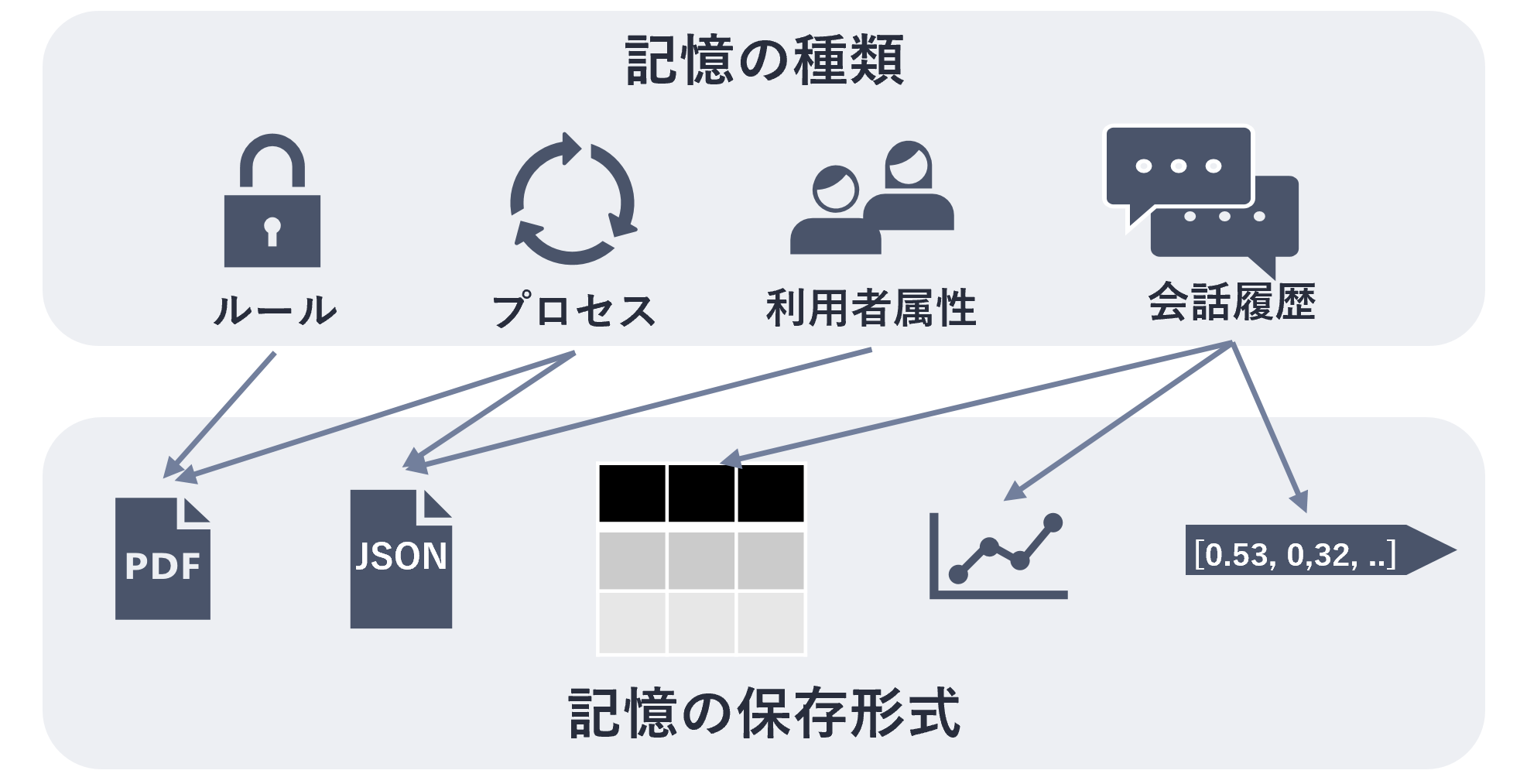
このように、生成AIアプリケーションが扱う記憶は一種類ではなく、形式や性質の異なる複数の情報から成り立っています。
3.2 記憶をどのように扱うのか
次に、記憶の扱い方を見ていきましょう。
ここでも人の記憶を例にすると理解しやすくなります。
私たちは、出来事や情報を記憶として保存し、必要なときに参照し、状況に応じて見直し、不要なものを整理することを無意識に行っています。
生成AIアプリケーションでもこのような記憶の「蓄積」「想起」「更新」「忘却」を行う仕組みが求められます。
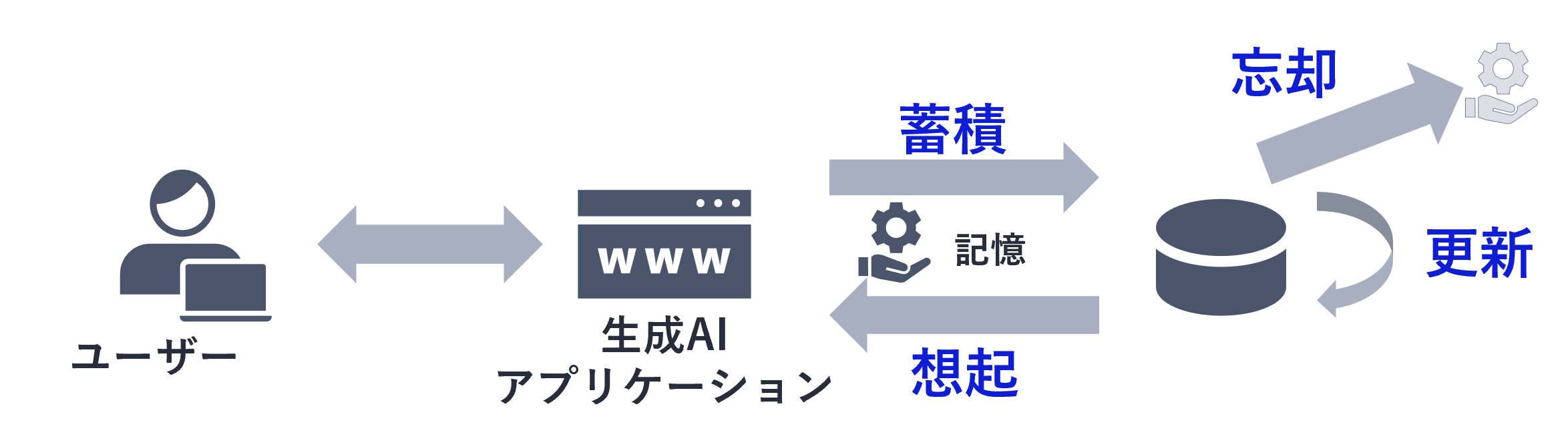
「蓄積」とは、業務にとって意味のある情報を記憶として残すことです。蓄積された記憶は、必要な場面で「想起」されることで、生成AIアプリケーション上で共有・活用されます。
また、蓄積された記憶は、そのままだと陳腐化してしまい、生成AIアプリケーションにとってはノイズになり得ます。
そこで、新しい情報へ「更新」する、もしくは「忘却」することで、今必要な情報を引き出しやすくすることが重要になります。
どの記憶を保持しておくべきかは、ユースケースや生成AIアプリケーションによって異なります。しかし、どの場面においても複数の記憶を横断して活用し、文脈に応じた応答や処理を行う必要があります。
一方で、記憶の種類ごとに管理基盤が分かれていると、必要な情報をまとめて参照しにくくなり、整合性のずれも起きやすくなります。
つまり、記憶管理においては異なる種類の記憶を一貫して扱いつつ、必要な記憶を文脈に応じて引き出せることが求められます。
次章ではこのような観点から、記憶管理基盤としてのOracle AI Databaseを見ていきます。
4 記憶管理基盤としてのOracle AI Database
ここからは、記憶を管理する基盤としてOracle AI Databaseを見ていきましょう
Oracle AI Databaseは、第2回で紹介したRAGや第3回で紹介したAIエージェントを実現することが可能な基盤になっています。
加えて、コンバージドデータベースとして、構造化データだけでなく、ドキュメントや履歴情報など、多様なデータ形式の保存が可能です。
このため、利用者情報、業務ルール、過去のやり取り、分析結果といった性質の異なる情報を分散させず、関係性を保ったまま一元的に管理しやすくなります。
さらに、記憶管理では、情報を保存するだけでなく、必要な情報を取り出し、内容を更新し、古くなった情報を整理する運用が求められます。
Oracle AI Databaseを活用することで、こうした「蓄積・想起・更新・忘却」の仕組みを、一つの基盤上で実装・運用しやすくなります。
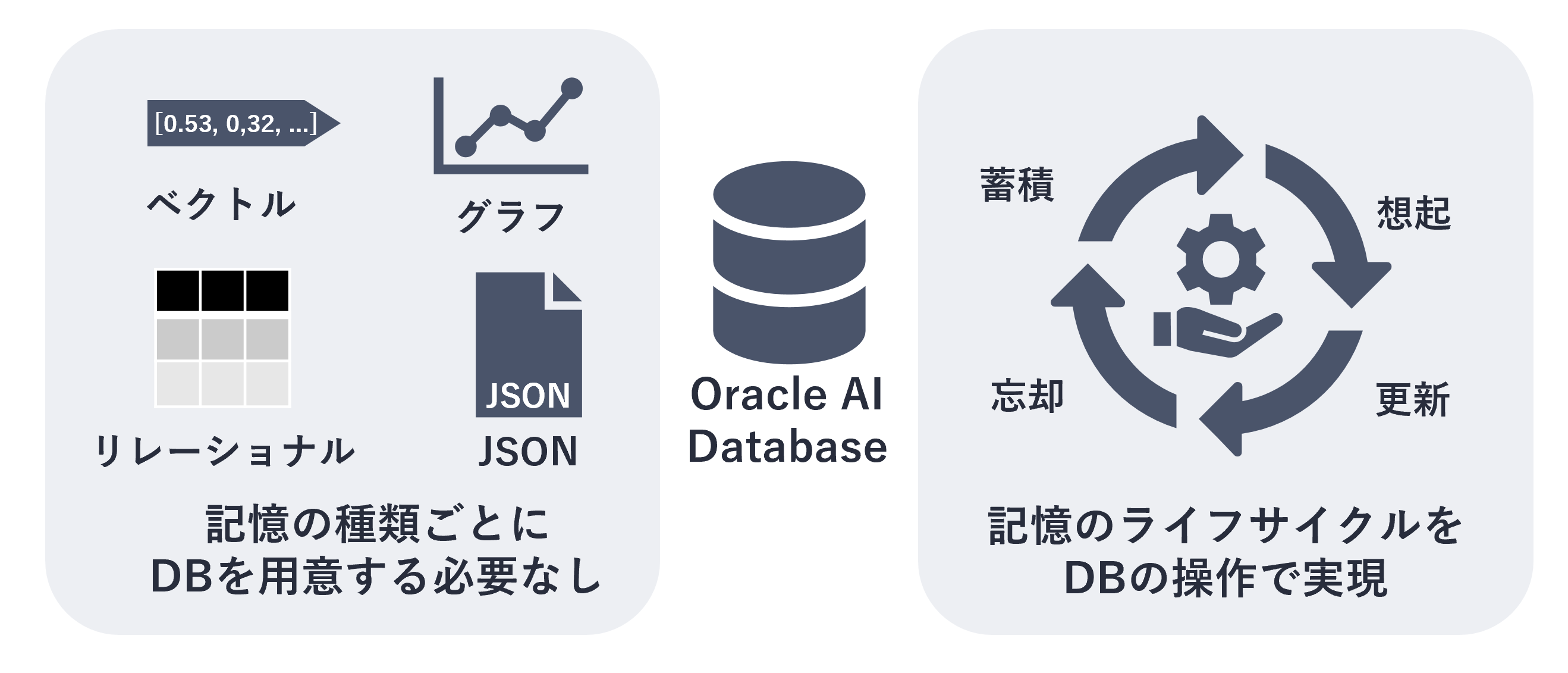
Oracle AI Databaseは、こうした記憶管理のライフサイクル全体を支える土台となります。
また、Oracle AI DatabaseはOCI上だけでなく、他社クラウド上でも利用できます。
そのため、OCI上で生成AIアプリケーションを構築する場合だけでなく、既存の他社クラウド環境で運用している生成AIアプリケーションに対しても、記憶基盤として組み合わせやすい選択肢となります。
5 おわりに
今回は、生成AIアプリケーションにおける「記憶」に注目しました。生成AIアプリケーションを継続的に利用していくには、記憶の設計が重要になっていきます。
さまざまな記憶を一元的に管理し、「蓄積・想起・更新・忘却」の仕組みを実装しやすくする基盤として、Oracle AI Databaseは有力な候補の一つになるのではないでしょうか。
NECでも検証を進めながら、業務への活用やお客様へ提供するサービスへの組み込みに向けて検討を進めていきたいと思います。
資料ダウンロード
NECでは、生成AIによる企業データ活用の第一歩をお手伝いするサービスとして、OCI上に生成AIのPoC基盤を構築し、技術支援を行うサービスを提供しております。詳しくは下記の資料をご覧ください。
Oracle Cloud 生成AI PoC環境構築サービス紹介資料

Oracle Cloud 生成AI PoC環境構築サービスでは、企業データの活用を検証するための生成AI基盤をお客様のOCI環境に迅速に導入します。また、導入した生成AI基盤での検証をサポートする技術支援オプションを提供します。
本サービスについての代表的なユースケースについてもご紹介します。