
Japan
サイト内の現在位置
PostgreSQL
周辺OSSツール紹介
pg_hint_plan 機能概要
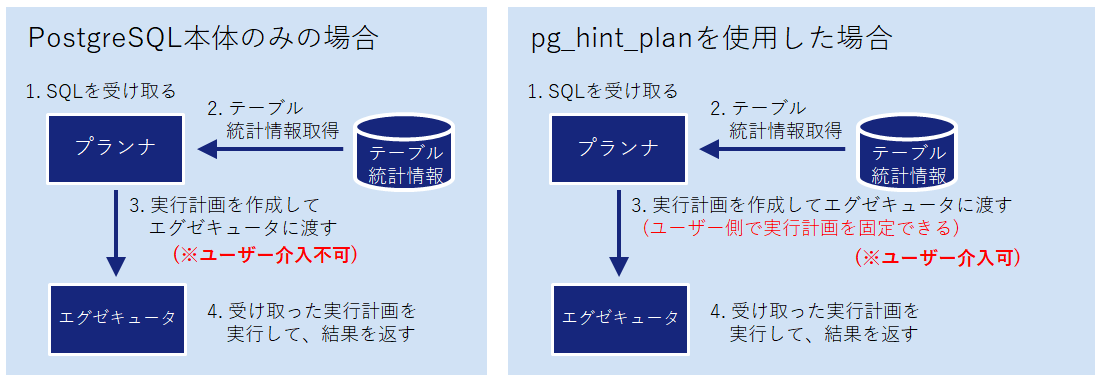
pg_hint_plan は PostgreSQLのプランナが作成するクエリ実行計画につき、ユーザー側で実行計画を差し替えて固定できるようにするツールです。
(※導入目的はDBパフォーマンスチューニングとなります)
PostgreSQLでは、クエリ実行時にプランナがテーブル統計情報を参照して最小コストとなる実行計画を作成しますが、必ずしも最速な処理時間とならない場合があります。
この場合において、ユーザーは一切介入できません。
pg_hint_planを使用することにより、ユーザー側で実行計画を固定できるため、ユーザーの環境に応じたクエリ実行の細かな最適化を実現できます。
(※ただし、ユーザーによる対象DBへの十分な知識と理解が必要です)
1. 実行計画の指定方法
pg_hint_planで実行計画を指定するには、コメント構文(/*~*/)の開始直後に(+)を付けて、以下のようにヒント句を指定します。
/*+ ヒント句 */
以下の例では、Hash JoinとSeqScanの使用を指示し、実際にそれらが用いられていることをEXPLAINコマンドで確認しています。
|
/*+ HashJoin(a b) SeqScan(a) */ |
ヒント句を指定しない場合、Nested LoopとIndexScanが使用されることがわかります。
|
EXPLAIN ANALYZE |
hint_plan.hintsテーブルにあらかじめSQL文とヒント句を登録しておくと、登録済みSQL文の実行時にヒント句を指定しなくてもヒントが自動で使用されます。
hint_plan.hintsテーブルの登録例: 特定のSQL文にHash JoinとSeqScanを適用させたい場合
|
SELECT * FROM hint_plan.hints ; |
上記の設定を行うことで、ヒント句を指定しなくても、Hash JoinとSeqScanが適用されます。
|
EXPLAIN ANALYZE |
※ヒント用テーブルに登録済みのクエリ文字列に対して、登録済みのヒントが自動で適用される
2. 利用可能なヒント句
PostgreSQLで利用可能なヒント句の一例を以下に示します。
PostgreSQLのヒント句と同等の意味を持つOracleのヒント句についても記載していますので参考にしてください。
| ヒント句グループ | ヒント句の内容 | Oracleのヒント句 | PostgreSQLの ヒント句 |
|---|---|---|---|
| スキャン方式 | 全表をスキャンする | FULL | SeqScan |
| 索引スキャンを使用する | INDEX | IndexScan | |
| 結合方式 | 指定した各表をハッシュ結合する | USE_HASH | Hashjoin |
| 結合順序 | ヒント句内に記述された順序のとおりに結合を行なう | LEADING | Leading |
| パラメータの一時的な変更 | 指定したパラメータを指定した値に変更する | OPT_PARAM | Set |
| Parallelヒント | 指定された数の同時サーバーをパラレル操作に使用する | PARALLEL | Parallel |
3. データベース製品ごとのヒント句の指定方法の違い
ヒント句の指定方法は、データベース製品ごとに異なります。
PostgreSQL、Oracle、SQL Serverのヒント句の記述例を以下に示します。
| ヒント句の記述例 | |
|---|---|
| PostgreSQL | explain /*+ IndexScan(e) */ select name, address from employee e where id > 2; |
| Oracle | explain plan for select /*+ INDEX(e) */ name, address from employee e where id > 2; |
| SQL Server | select name, address from employee e with (INDEX(e) ) where id > 2; |
pg_hint_planでは、比較的Oracleに近い方法でヒント句を指定することができます。
Microsoft SQL Serverではいくつかの例外を除き、テーブル ヒントは、FROM 句で WITH キーワードを用いて指定します。
各データベース製品のヒント機能については以下を参照してください。
PostgreSQLのヒント一覧
https://github.com/ossc-db/pg_hint_plan/blob/master/docs/hint_list.md
Oracleのヒント一覧
https://docs.oracle.com/cd/E82638_01/sqlrf/Comments.html
SQL Serverのヒント一覧
https://learn.microsoft.com/ja-jp/sql/t-sql/queries/hints-transact-sql-query?view=sql-server-ver16
