Japan
サイト内の現在位置
Frovedisによるグラフ解析(GraphXとの処理速度比較)
no.0172022.3.4 今回はグラフ解析におけるFrovedisとNetworkXのアルゴリズム実行時間を比較します。
使用するデータセットはGraph partitioning and graph clustering : 10th DIMACS Implementation Challenge Workshopで用意されたものの一部をダウンロードしたものです。なお、 DIMACSはRutgers Universityをはじめとする大学や企業研究機関により共同運営されている離散数学に関する各種問題を取り扱うプロジェクトです。過去のImplementation Challengesはここから確認することができます。
DIMACSはRutgers Universityをはじめとする大学や企業研究機関により共同運営されている離散数学に関する各種問題を取り扱うプロジェクトです。過去のImplementation Challengesはここから確認することができます。
8種類のデータセットは論文における引用文献や共著者としての関係性を示すもの、インターネットのネットワーク形態をグラフデータ化したものなどを含んでいます。
サンプルコードでは、初めにこれら8種類のグラフデータセットをロードする際に要する時間をFrovedisとNetworkXで比較します。
続いて、Single Source Shortest Path (SSSP)、PageRank、Breadth First Search (BFS)、そしてConnected Components (CC)アルゴリズム実行時間を同様に比較していきます。
使用するデータセットについて¶
次のURLからデータセットのダウンロードが行えます。 https://sparse.tamu.edu/MM/DIMACS10/preferentialAttachment.tar.gz¶
グラフデータ化について。5つの接続されたノードからなる集まりを起点として、各ノードについてさらに隣接する5つのノードをエッジを通して接続します。こうすることで均等性を持った接続ノード選択の確率を高めています。¶
caidaRouterLevel:¶
ダウンロード先 https://sparse.tamu.edu/MM/DIMACS10/caidaRouterLevel.tar.gz¶
無方向ネットワーク。¶
coAuthorsDBLP:¶
ダウンロード先 https://sparse.tamu.edu/MM/DIMACS10/coAuthorsDBLP.tar.gz¶
"Co-Authorship Network" 共著ネットワークは少なくとも一つの論文の共同執筆者のネットワーク。¶
dblp-2010:¶
ダウンロード先 https://sparse.tamu.edu/MM/LAW/dblp-2010.tar.gz¶
"DBLP " 無方向ネットワーク。各ノードは研究者を表し、最低一つの共同研究を行った研究者同士をエッジで接続。¶
citationCitesee:¶
ダウンロード先 https://sparse.tamu.edu/MM/DIMACS10/citationCiteseer.tar.gz¶
"Citation network dataset published by DIMACS10" 各ノードは論文を表し、ある論文から引用される論文をエッジで接続。¶
coPapersDBLP:¶
ダウンロード先 https://sparse.tamu.edu/MM/DIMACS10/coPapersDBLP.tar.gz¶
"Citation network dataset published by DIMACS10" 各ノードは研究者を表し、ある研究者の論文が引用する論文を執筆した研究者をエッジで接続。¶
coPapersCiteseer:¶
ダウンロード先 https://sparse.tamu.edu/MM/DIMACS10/coPapersCiteseer.tar.gz¶
論文同士の引用関係に基づいた無方向ネットワーク。¶
as-Skitter:¶
ダウンロード先 https://sparse.tamu.edu/MM/SNAP/as-Skitter.tar.gz¶
"Internet Topology datasets" コンピュータネットワークの配線に端末や各種機器の接続形状を表すネットワークデータ。¶
In [1]:
import os
import sys
import time
import numpy as np
import pandas as pd
import networkx as nx
import frovedis.graph as fnx
from collections import OrderedDict
In [2]:
input_graph_files = {
'preferentialAttachment' : './preferentialAttachment.mtx',
'caidaRouterLevel' : './caidaRouterLevel.mtx',
'coAuthorsDBLP' : './coAuthorsDBLP.mtx',
'dblp' : './dblp-2010.mtx',
'citationCiteseer' : './citationCiteseer.mtx',
'coPapersDBLP' : './coPapersDBLP.mtx',
'coPapersCiteseer' : './coPapersCiteseer.mtx',
'as-Skitter' : './as-Skitter.mtx'
}
In [3]:
from frovedis.exrpc.server import FrovedisServer
FrovedisServer.initialize("mpirun -np 8 " + os.environ["FROVEDIS_SERVER"])
Out[3]:
'[ID: 1] FrovedisServer (Hostname: handson02, Port: 43571) has been initialized with 8 MPI processes.'
グラフデータをロード¶
In [4]:
# -------- Graph loading demo --------
frov_data_loading_time = []
nx_data_loading_time = []
frov_graph = []
frov_graph_dir = []
nx_graph = []
nx_graph_dir = []
nnodes = []
nedges = []
for dataset, path in input_graph_files.items():
dl_start_time = time.time()
fgraph = fnx.read_edgelist(path, nodetype=np.int32, delimiter=' ')
# pagerank等において良好なランキング結果を得るため有方向グラフを使用
fgraph_dir = fnx.read_edgelist(path, nodetype=np.int32, delimiter=' ', \
create_using=nx.DiGraph())
frov_data_loading_time.append(round(time.time() - dl_start_time, 4))
frov_graph.append(fgraph)
frov_graph_dir.append(fgraph_dir)
dl_start_time = time.time()
ngraph = nx.read_edgelist(path, nodetype=np.int32, delimiter=' ')
# pagerank等において良好なランキング結果を得るため有方向グラフを使用
ngraph_dir = nx.read_edgelist(path, nodetype=np.int32, delimiter=' ', \
create_using=nx.DiGraph())
nx_data_loading_time.append(round(time.time() - dl_start_time, 4))
nx_graph.append(ngraph)
nx_graph_dir.append(ngraph_dir)
nnodes.append(ngraph.number_of_nodes())
nedges.append(ngraph.number_of_edges())
In [5]:
data_details = pd.DataFrame(OrderedDict({ "dataset": list(input_graph_files.keys()),
"num_nodes": nnodes,
"num_edges": nedges,
"frov_loading_time": frov_data_loading_time,
"nx_loading_time": nx_data_loading_time
}))
data_details["frov_speed_up"] = data_details["nx_loading_time"] / data_details["frov_loading_time"]
data_details
Out[5]:
| dataset | num_nodes | num_edges | frov_loading_time | nx_loading_time | frov_speed_up | |
|---|---|---|---|---|---|---|
| 0 | preferentialAttachment | 100000 | 499985 | 0.4608 | 7.4924 | 16.259549 |
| 1 | caidaRouterLevel | 192244 | 609066 | 0.5125 | 9.2107 | 17.972098 |
| 2 | coAuthorsDBLP | 299067 | 977676 | 0.8225 | 15.4249 | 18.753678 |
| 3 | dblp | 300647 | 807700 | 0.7369 | 13.5638 | 18.406568 |
| 4 | citationCiteseer | 268495 | 1156647 | 0.8324 | 17.3037 | 20.787722 |
| 5 | coPapersDBLP | 540486 | 15245729 | 11.8188 | 191.2986 | 16.185958 |
| 6 | coPapersCiteseer | 434102 | 16036720 | 12.0383 | 198.0150 | 16.448751 |
| 7 | as-Skitter | 1696415 | 11095298 | 9.3662 | 162.8126 | 17.382994 |
Single Source Shortest Path (SSSP)¶
In [6]:
src = 5
frov_sssp_time = []
nx_sssp_time = []
dist_matched = []
for i in range(len(frov_graph)):
start_time = time.time()
fpath, fdist = fnx.single_source_shortest_path(frov_graph[i], \
src, return_distance=True)
frov_sssp_time.append(round(time.time() - start_time, 4))
start_time = time.time()
npath = nx.single_source_shortest_path(nx_graph[i], src)
nx_sssp_time.append(round(time.time() - start_time, 4))
ndist = {k: float(len(v)-1) for k, v in npath.items()}
dist_matched.append("Yes" if fdist == ndist else "No")
In [7]:
sssp_df = pd.DataFrame(OrderedDict ({ "dataset": list(input_graph_files.keys()),
"frov_sssp_time": frov_sssp_time,
"nx_sssp_time": nx_sssp_time,
"result_matched": dist_matched
}))
sssp_df["frov_speed_up"] = sssp_df["nx_sssp_time"] / sssp_df["frov_sssp_time"]
sssp_df
Out[7]:
| dataset | frov_sssp_time | nx_sssp_time | result_matched | frov_speed_up | |
|---|---|---|---|---|---|
| 0 | preferentialAttachment | 0.0449 | 0.4507 | Yes | 10.037862 |
| 1 | caidaRouterLevel | 0.0873 | 0.6527 | Yes | 7.476518 |
| 2 | coAuthorsDBLP | 0.1059 | 17.0259 | Yes | 160.773371 |
| 3 | dblp | 0.0963 | 0.7958 | Yes | 8.263759 |
| 4 | citationCiteseer | 0.1022 | 1.1725 | Yes | 11.472603 |
| 5 | coPapersDBLP | 0.2262 | 4.5493 | Yes | 20.111848 |
| 6 | coPapersCiteseer | 0.1935 | 4.2283 | Yes | 21.851680 |
| 7 | as-Skitter | 0.5913 | 23.5207 | Yes | 39.777947 |
PageRank¶
In [8]:
frov_pr_time = []
nx_pr_time = []
order_matched = []
#pagerankにおいて良好なランキング結果を得るため有方向グラフを使用
for i in range(len(frov_graph_dir)):
start_time = time.time()
frov_ranks = fnx.pagerank(frov_graph_dir[i])
frov_pr_time.append(round(time.time() - start_time, 4))
df1 = pd.DataFrame({ "node": list(frov_ranks.keys()),
"rank": list(frov_ranks.values())
}) \
.sort_values(by = ["rank", "node"]) \
.head(10)
start_time = time.time()
nx_ranks = nx.pagerank(nx_graph_dir[i])
nx_pr_time.append(round(time.time() - start_time, 4))
df2 = pd.DataFrame({ "node": list(nx_ranks.keys()),
"rank": list(nx_ranks.values())
}) \
.sort_values(by = ["rank", "node"]) \
.head(10)
order_matched.append("Yes" if list(df1.node.values) == list(df2.node.values) else "No")
In [9]:
pagerank_df = pd.DataFrame(OrderedDict ({ "dataset": list(input_graph_files.keys()),
"frov_pr_time": frov_pr_time,
"nx_pr_time": nx_pr_time,
"ranking_order_matched": order_matched
}))
pagerank_df["frov_speed_up"] = pagerank_df["nx_pr_time"] / pagerank_df["frov_pr_time"]
pagerank_df
Out[9]:
| dataset | frov_pr_time | nx_pr_time | ranking_order_matched | frov_speed_up | |
|---|---|---|---|---|---|
| 0 | preferentialAttachment | 0.0243 | 12.1571 | Yes | 500.292181 |
| 1 | caidaRouterLevel | 0.0444 | 12.4950 | Yes | 281.418919 |
| 2 | coAuthorsDBLP | 0.0658 | 16.3090 | Yes | 247.857143 |
| 3 | dblp | 0.0672 | 13.4622 | Yes | 200.330357 |
| 4 | citationCiteseer | 0.0563 | 18.9184 | Yes | 336.028419 |
| 5 | coPapersDBLP | 0.1246 | 141.2854 | Yes | 1133.911717 |
| 6 | coPapersCiteseer | 0.1089 | 125.0252 | Yes | 1148.073462 |
| 7 | as-Skitter | 0.3258 | 106.4397 | Yes | 326.702578 |
Breadth First Search (BFS)¶
In [10]:
source = 1
distance = 4
frov_bfs_time = []
nx_bfs_time = []
result_matched = []
for i in range(len(frov_graph)):
start_time = time.time()
frov_res = fnx.descendants_at_distance(frov_graph[i], source, distance)
frov_bfs_time.append(round(time.time() - start_time, 4))
start_time = time.time()
nx_res = nx.descendants_at_distance(nx_graph[i], source, distance)
nx_bfs_time.append(round(time.time() - start_time, 4))
result_matched.append("Yes" if len(frov_res - nx_res) == 0 else "No")
In [11]:
bfs_df = pd.DataFrame(OrderedDict ({ "dataset": list(input_graph_files.keys()),
"frov_bfs_time": frov_bfs_time,
"nx_bfs_time": nx_bfs_time,
"result_matched": result_matched
}))
bfs_df["frov_speed_up"] = bfs_df["nx_bfs_time"] / bfs_df["frov_bfs_time"]
bfs_df
Out[11]:
| dataset | frov_bfs_time | nx_bfs_time | result_matched | frov_speed_up | |
|---|---|---|---|---|---|
| 0 | preferentialAttachment | 0.0186 | 0.4020 | Yes | 21.612903 |
| 1 | caidaRouterLevel | 0.0196 | 0.0842 | Yes | 4.295918 |
| 2 | coAuthorsDBLP | 0.0112 | 0.0026 | Yes | 0.232143 |
| 3 | dblp | 0.0094 | 0.0006 | Yes | 0.063830 |
| 4 | citationCiteseer | 0.0119 | 0.0057 | Yes | 0.478992 |
| 5 | coPapersDBLP | 0.0204 | 0.0407 | Yes | 1.995098 |
| 6 | coPapersCiteseer | 0.0158 | 0.0178 | Yes | 1.126582 |
| 7 | as-Skitter | 0.2090 | 3.2832 | Yes | 15.709091 |
Connected Components (CC)¶
In [12]:
frov_cc_time = []
nx_cc_time = []
frov_ncomponents = []
nx_ncomponents = []
result_matched = []
for i in range(len(frov_graph)):
start_time = time.time()
tmp = fnx.connected_components(frov_graph[i])
set_cc_frov = set()
for elem in tmp:
set_cc_frov.add(frozenset(elem))
frov_cc_time.append(round(time.time() - start_time, 4))
frov_ncomponents.append(len(set_cc_frov))
start_time = time.time()
tmp = nx.connected_components(nx_graph[i])
set_cc_nx = set()
for elem in tmp:
set_cc_nx.add(frozenset(elem))
nx_cc_time.append(round(time.time() - start_time, 4))
nx_ncomponents.append(len(set_cc_nx))
result_matched.append("Yes" if set_cc_frov == set_cc_nx else "No")
In [13]:
cc_df = pd.DataFrame(OrderedDict ({ "dataset": list(input_graph_files.keys()),
"frov_cc_time": frov_cc_time,
"nx_cc_time": nx_cc_time,
"frov_ncomponents": frov_ncomponents,
"nx_ncomponents": nx_ncomponents,
"result_matched": result_matched
}))
cc_df["frov_speed_up"] = cc_df["nx_cc_time"] / cc_df["frov_cc_time"]
cc_df
Out[13]:
| dataset | frov_cc_time | nx_cc_time | frov_ncomponents | nx_ncomponents | result_matched | frov_speed_up | |
|---|---|---|---|---|---|---|---|
| 0 | preferentialAttachment | 0.1196 | 0.3603 | 1 | 1 | Yes | 3.012542 |
| 1 | caidaRouterLevel | 0.2830 | 0.5640 | 308 | 308 | Yes | 1.992933 |
| 2 | coAuthorsDBLP | 0.3208 | 0.8330 | 1 | 1 | Yes | 2.596633 |
| 3 | dblp | 2.8838 | 0.7636 | 22954 | 22954 | Yes | 0.264790 |
| 4 | citationCiteseer | 0.3080 | 1.0395 | 1 | 1 | Yes | 3.375000 |
| 5 | coPapersDBLP | 0.6026 | 3.5409 | 1 | 1 | Yes | 5.876037 |
| 6 | coPapersCiteseer | 0.5083 | 3.3178 | 1 | 1 | Yes | 6.527248 |
| 7 | as-Skitter | 1.9541 | 5.8195 | 756 | 756 | Yes | 2.978097 |
In [14]:
FrovedisServer.shut_down()
なお、今回取り上げたグラフアルゴリズムについては前回のブログの中でも使用していますので、そちらもご参照ください。
最後に、データセットロード、グラフアルゴリズム実行時間の比較結果を以下の各アルゴリズムに分けてグラフにまとめます。
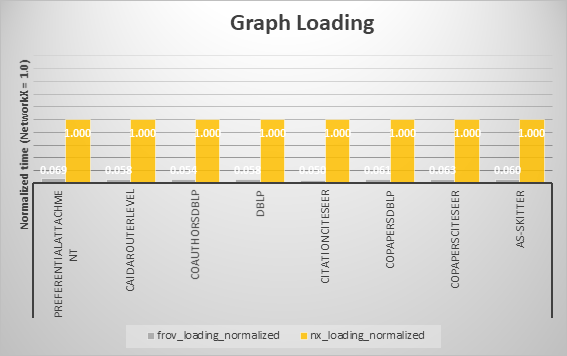
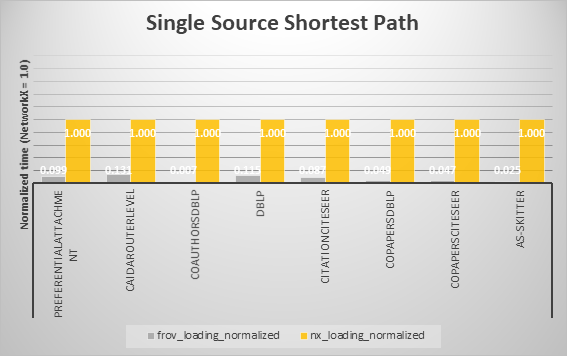
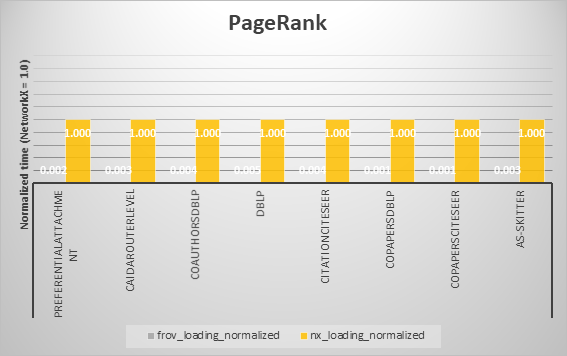

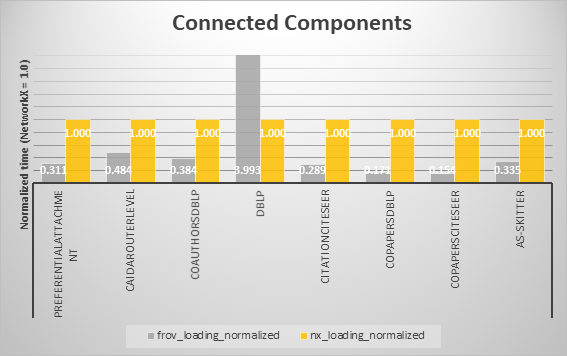
各アルゴリズムにおいて、概ねFrovedisの方が高速であることが確認できました。ただしBreadth First SearchとConnected Componentsでは一部のデータにおいてFrovedisで多く時間がかかっています。しかし、時間の絶対値で見るとそれらほとんどは、およそ0.001~0.010secの範囲内での比較であり、総括的にはFrovedisの優位性を損なうものではないと考えます。
離散数学の一分野として組合せ論などと共に取り上げられることが多いグラフ理論は、有限であるノード、エッジから構成されるネットワークを解析する手段として大学等の教育テーマとして多く取り上げられています。グラフ理論を活用することで様々な社会問題が効率的に解決されることが期待されていますが、その他AI・機械学習と比較して広く実社会で利用され始めるのはこれからと言われています。
Frovedisを使用した高速なグラフ解析によって、より大規模で複雑なネットワークに関する問題解決にお役立てください。