Japan
サイト内の現在位置
【Oracle×生成AI 第2回】社内ナレッジ活用のユースケースで考えるRAG実現のポイント
第1回の記事では、生成AIによる企業データ活用のニーズが高まっていること、その中で生成AIを活用する基盤としてOracleを選ぶ理由、そしてNECにおけるOracle×生成AIによる企業データ活用事例について触れました。
しかし、生成AIを自社の業務にどう活かせばいいのか、具体的な活用イメージが湧いていない方もいらっしゃるかと思います。もしくは生成AIの活用に興味があり、具体的な業務適用やPoC実施を検討されている方もいらっしゃるかもしれません。本記事はこのようなお悩みを抱えている方向けの内容となっています。
今回は、企業が抱える共通の課題の一つ「社内ナレッジの活用」に焦点を当て、生成AIによる具体的な活用方法とその実現方法についてお届けします。
目次
1 企業データの価値を引き出す生成AI
企業には日々、膨大なデータが蓄積されています。FAQ、業務マニュアル、過去のプレゼン資料、製品の在庫情報など、その形式も内容もさまざまです。これらの企業データを生成AIと組み合わせることで、以下のような活用が可能になります。
-
- 社内ナレッジの検索
-
- ドキュメント作成の自動化
-
- デザイン・コンテンツ・設計案の自動生成
-
- ソフトウェア開発やデバッグの効率化
これらはほんの一例ですが、生成AIを活用することで「企業データの意味を理解し、活用する」ことが可能になります。
次章では、生成AIを用いた企業データ活用ユースケースの一つである「社内ナレッジ検索」を通じて、生成AIがどのように業務効率化に貢献するのかをご紹介します。
2 社内ナレッジ活用で見る生成AIの効果
まずはこのような場面を想像してみましょう。
営業部の田中さんは、来週の提案に向けて製品Aの導入事例を探していました。
社内ポータルには大量の資料があるものの、キーワードで検索してもなかなか目的の情報にたどり着けません。製品Aの担当者に問い合わせたものの、回答が返ってくるまでに半日かかり、業務が停滞してしまいました。
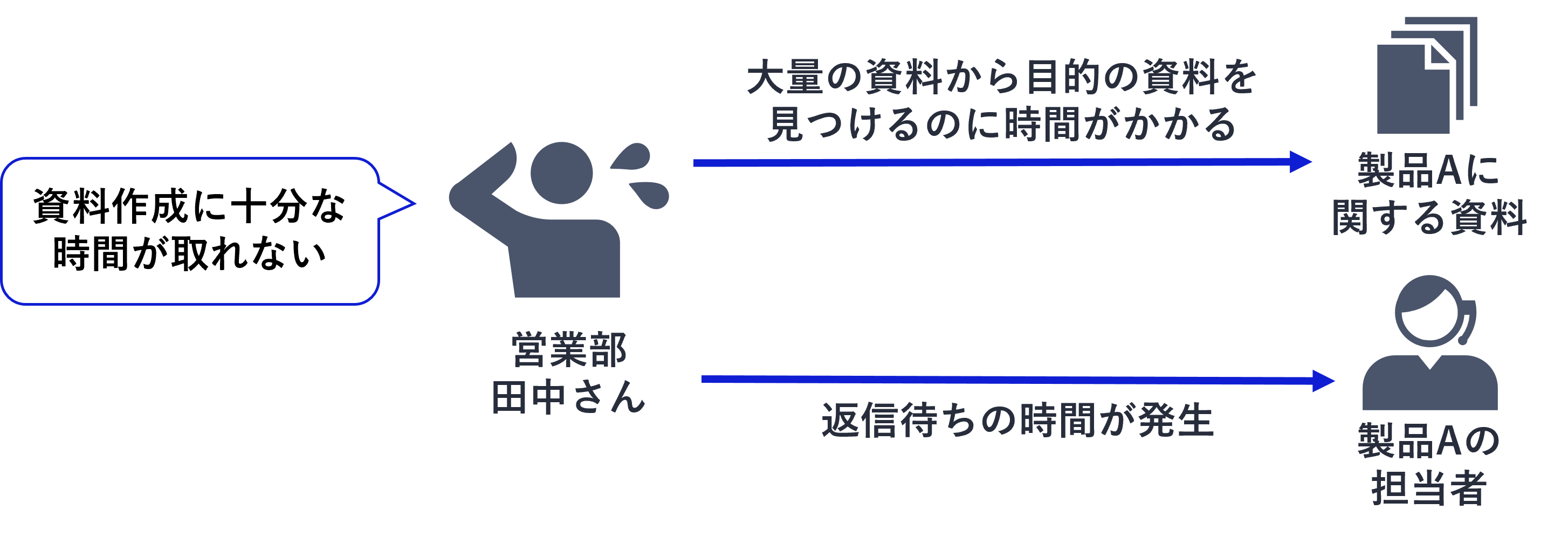
このような田中さんの状況は、多くの企業においても日常的に起きているのではないでしょうか。
こうした課題に対して、生成AIを活用することで田中さんの業務は次のように変わります。
営業部の田中さんは、来週の提案に向けて製品Aの導入事例を探していました。
社内検索チャットボット(アプリケーション)に「製品Aの導入事例を教えて」と入力すると、チャットボットが社内データを検索し、数十秒で社内資料の内容の要約と、参考資料の一覧を提示しました。田中さんはその情報を基に、提案資料の作成に取り掛かることができました。

生成AIを活用することで、社内の膨大なデータから簡単かつ高速に必要な情報を検索することが可能になります。
今回の営業部の田中さんのユースケースでは、生成AIを利用することで、次のような問題解決、業務効率化が見込めます。
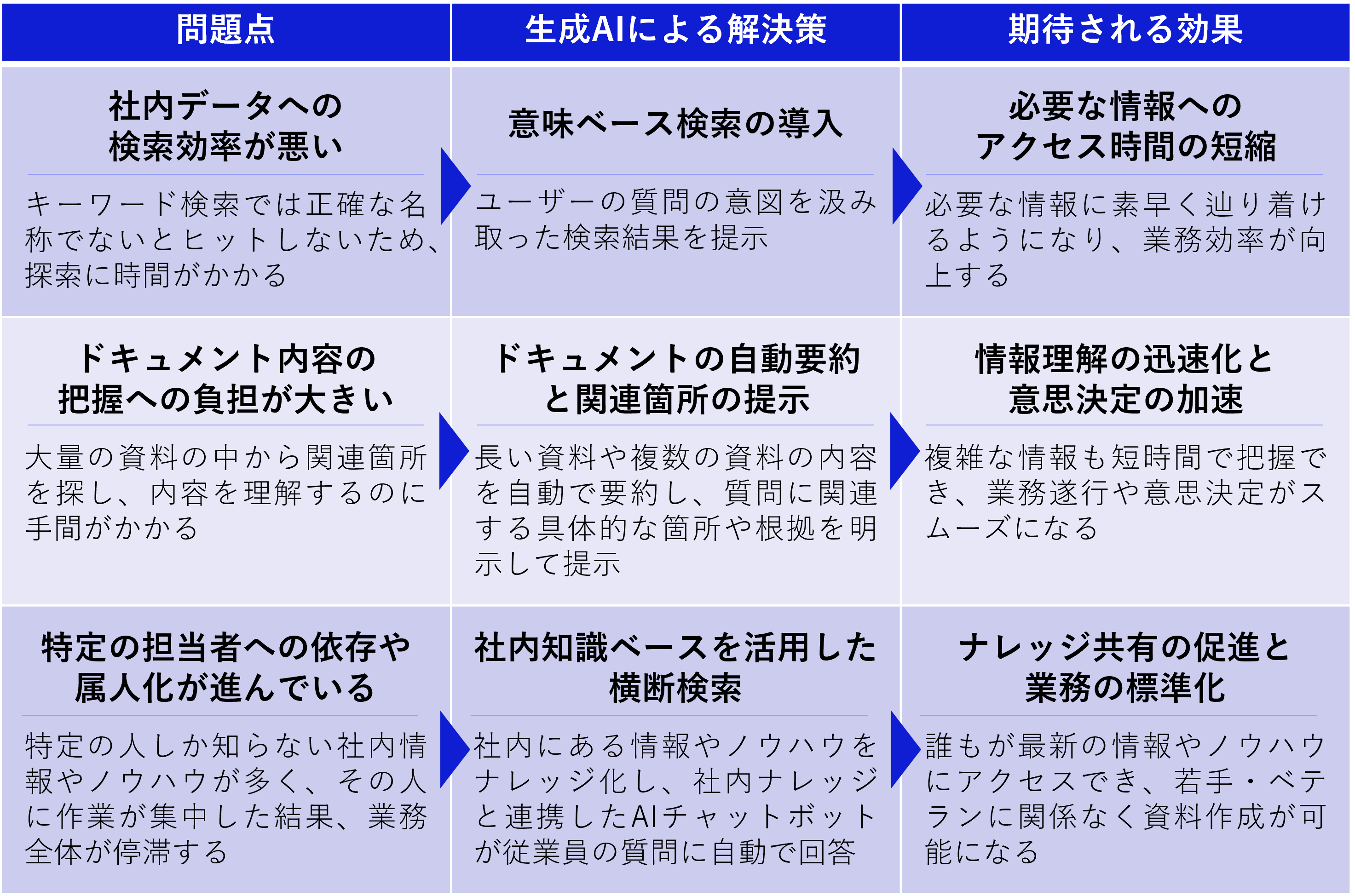
他にも、製品Aの担当者は、チャットボットが自動で回答してくれるので、他の業務に取り掛かることができたり、業務の属人化が解消されたりと、生成AIによって解決できる問題や課題はさまざまあります。
このように、生成AIと企業データを組み合わせることで、社内業務の効率化が促進されるのではないかと期待を持っていただけたのではないでしょうか。
一方で、「便利そうだけど、本当に実現できるの?」と疑問を感じた方もいらっしゃるかもしれません。
そこで次章では、このようなユースケースを実現する技術的な要素である「RAG」について説明した後、Oracleを活用した構成や要素にフォーカスして解説いたします。
3 RAGの基本知識
社内ナレッジ検索システムの実現方法についてお話しする前に、このシステムの核となる「RAG(Retrieval Augmented Generation)」という技術についてご説明します。前回の記事でも少し触れましたが、改めて詳しく見ていきましょう。
3.1 RAGとは?
RAGとは、生成AI(大規模言語モデル:LLM)にデータベースや文書などの情報を与えることで、学習していない内容についても正確に回答できるようにする技術です。
通常の生成AIは学習時の知識のみを基に回答するため、社内情報などの学習していない内容については正しく回答することができません。一方、RAGではユーザーが登録・指定したデータソース(例えば、製品のFAQや業務マニュアル、CSV、データベースなど)から関連情報を検索し、その結果をもとに回答を生成するため、学習データに含まれていない社内情報などについても正確に回答できます。
イメージしやすいように、RAGシステムと他の検索方法を比較してみましょう。
従来の検索では、社内情報について検索できない、調べた内容をまとめ直す手間がかかるなどの課題がありました。
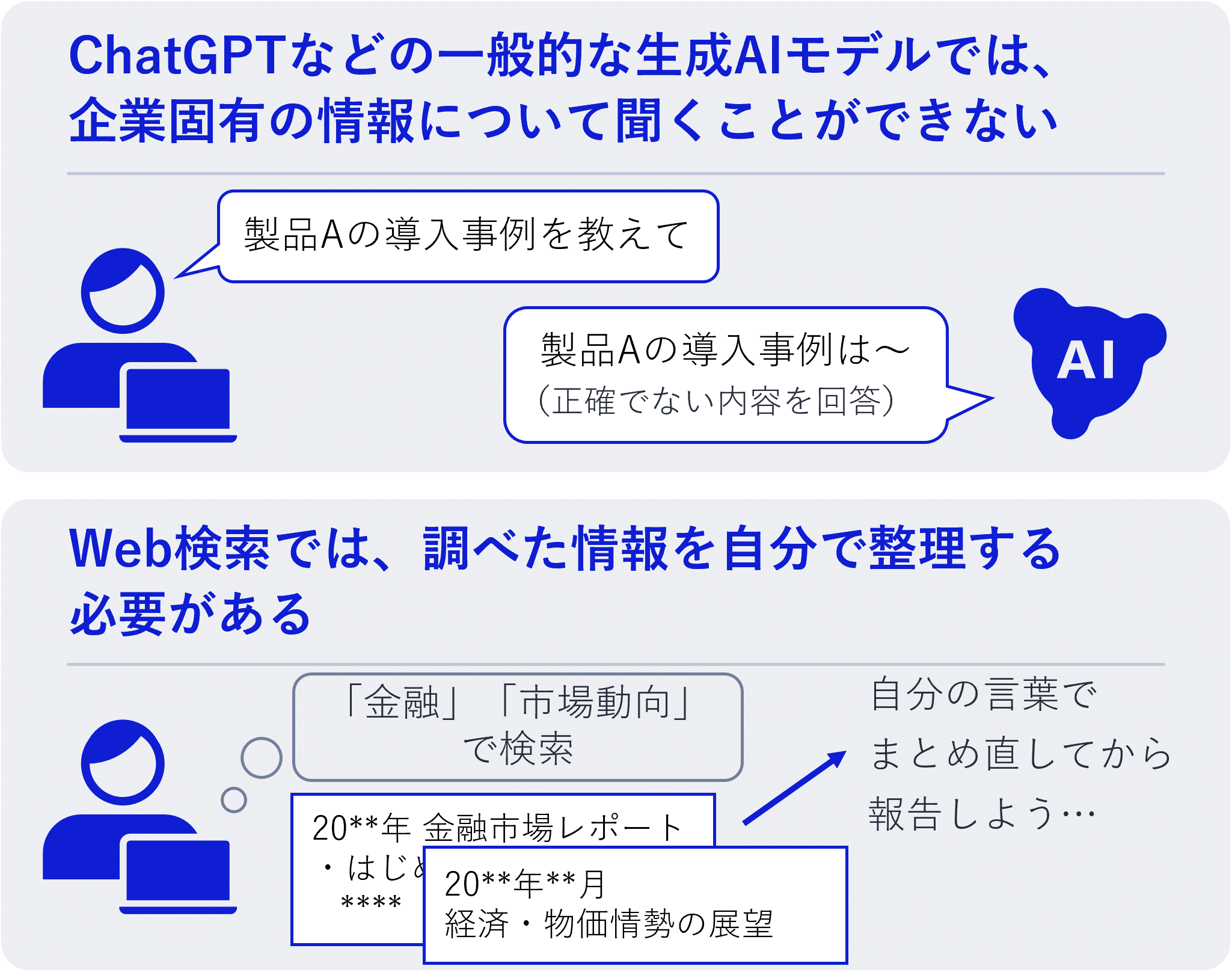
それに対してRAGシステムでは、ユーザーが登録・指定したデータソースから関連情報を検索し、その内容を参考にしながら回答をまとめてくれます。

3.2 ベクトル検索とは?
「ベクトル検索」はRAGシステムでよく使われる検索手法の一つです。
従来のキーワード検索では、文字列の一致に基づいて検索するため、似た意味を持つ異なる単語の関連性を認識することはできませんでした。一方、ベクトル検索ではデータの意味や文脈を考慮して検索することが可能です。
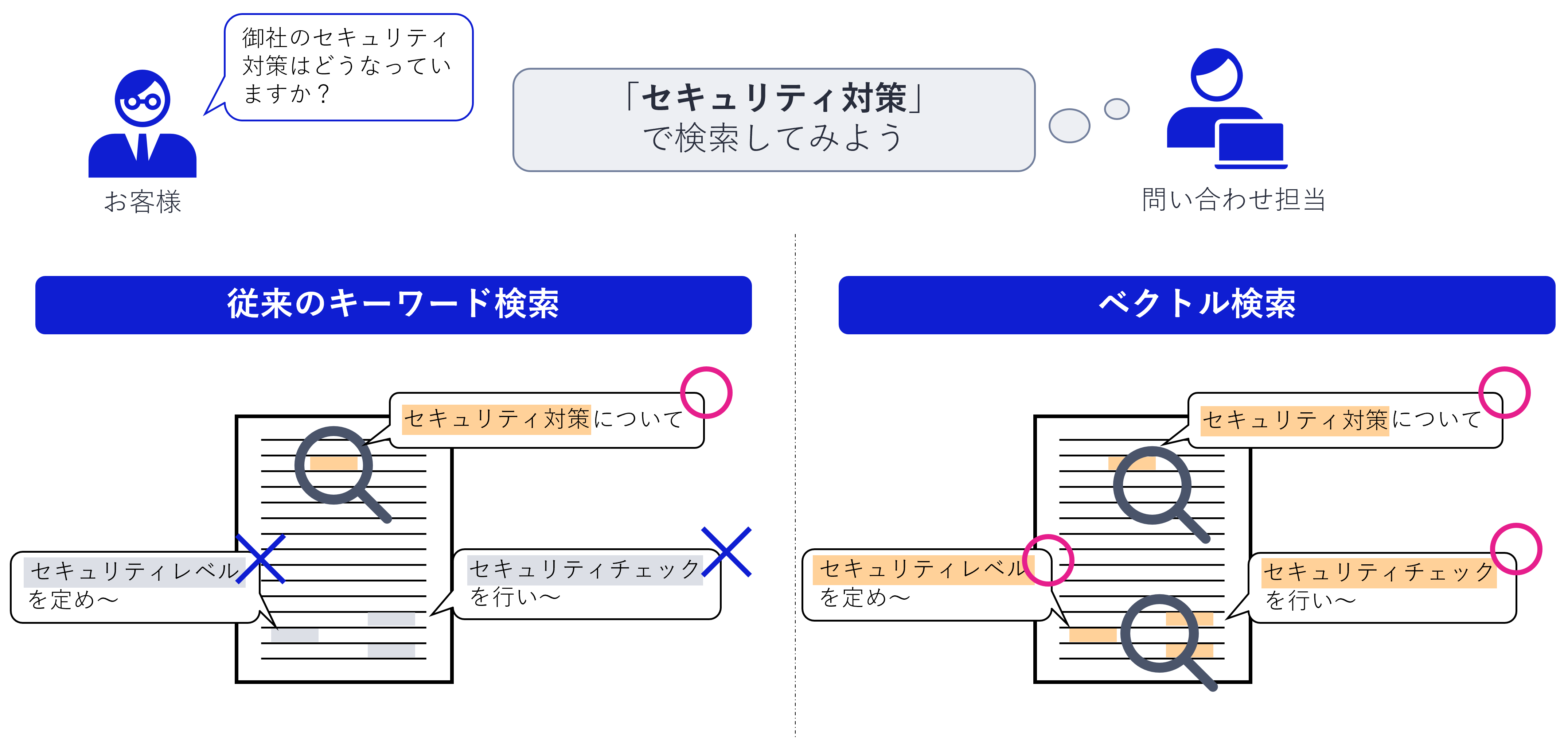
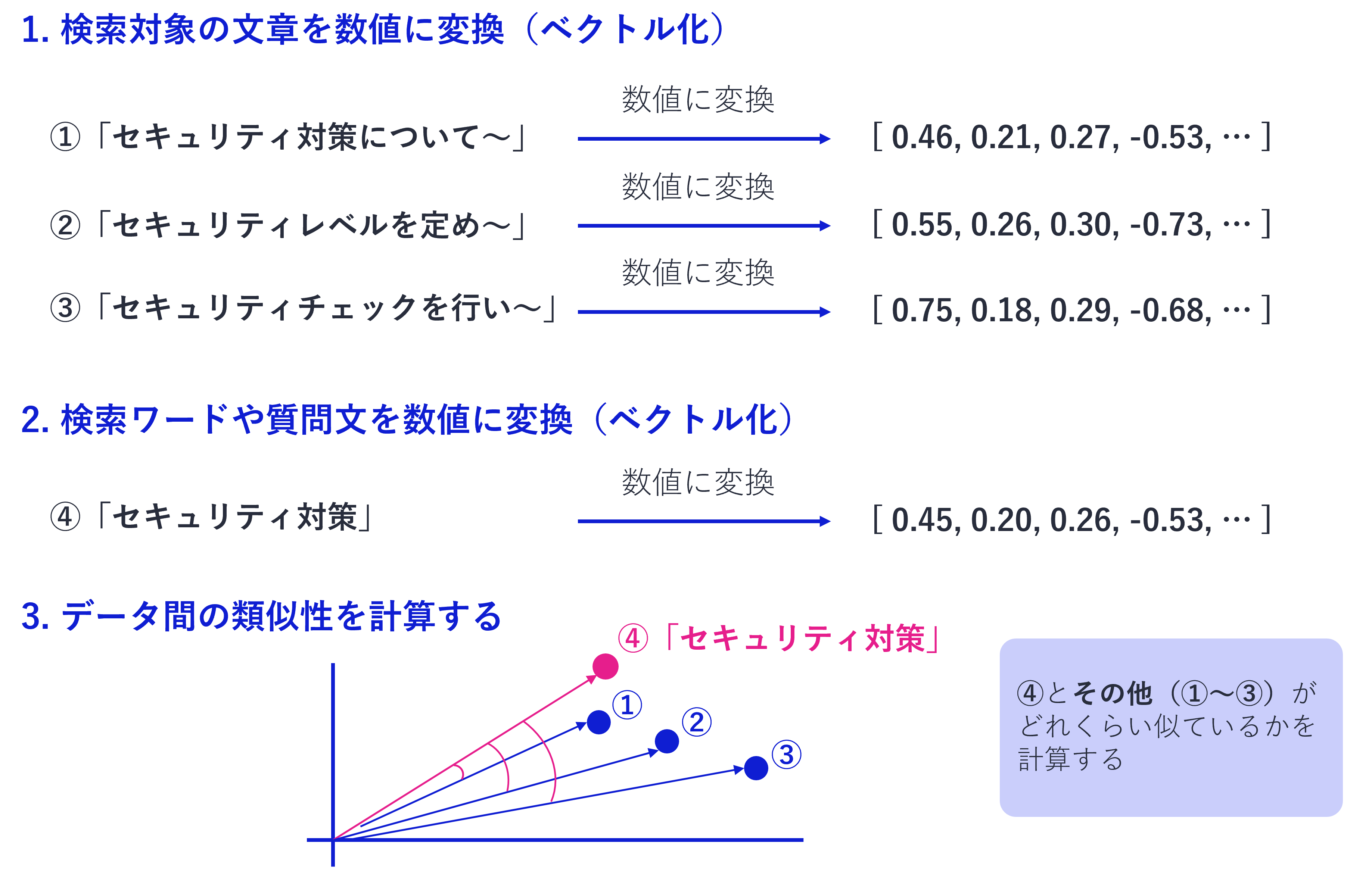
例えば、自社の「セキュリティ対策」について検索するとします。
従来のキーワード検索の場合、「セキュリティ対策」という文字がある部分のみ検索されます。「セキュリティレベル」「セキュリティチェック」などの単語を見つけることはできません。
ベクトル検索の場合は、「セキュリティ対策」の意味を理解し、「セキュリティ対策」という単語だけでなく「セキュリティレベル」「セキュリティチェック」といった関連する情報も検索してくれます。
文字が一致していないのに、どのように関連する情報を検索しているのか気になりますよね。
ベクトル検索では、データを数値に変換し、それらの類似性を計算・比較します。言葉や意味の特徴を、生成AIが理解しやすい数値の配列(ベクトル)で表現することで、似た意味を持つ単語や文章を探すことができるのです。
3.3 「データ準備」と「検索・回答生成」フェーズ
RAGシステムは、大きく分けて「データ準備」と「検索・回答生成」の2つのフェーズで動作します。
ここでは、RAGで利用する検索手法のうちベクトル検索を用いた場合の仕組みに焦点を当てて解説します。
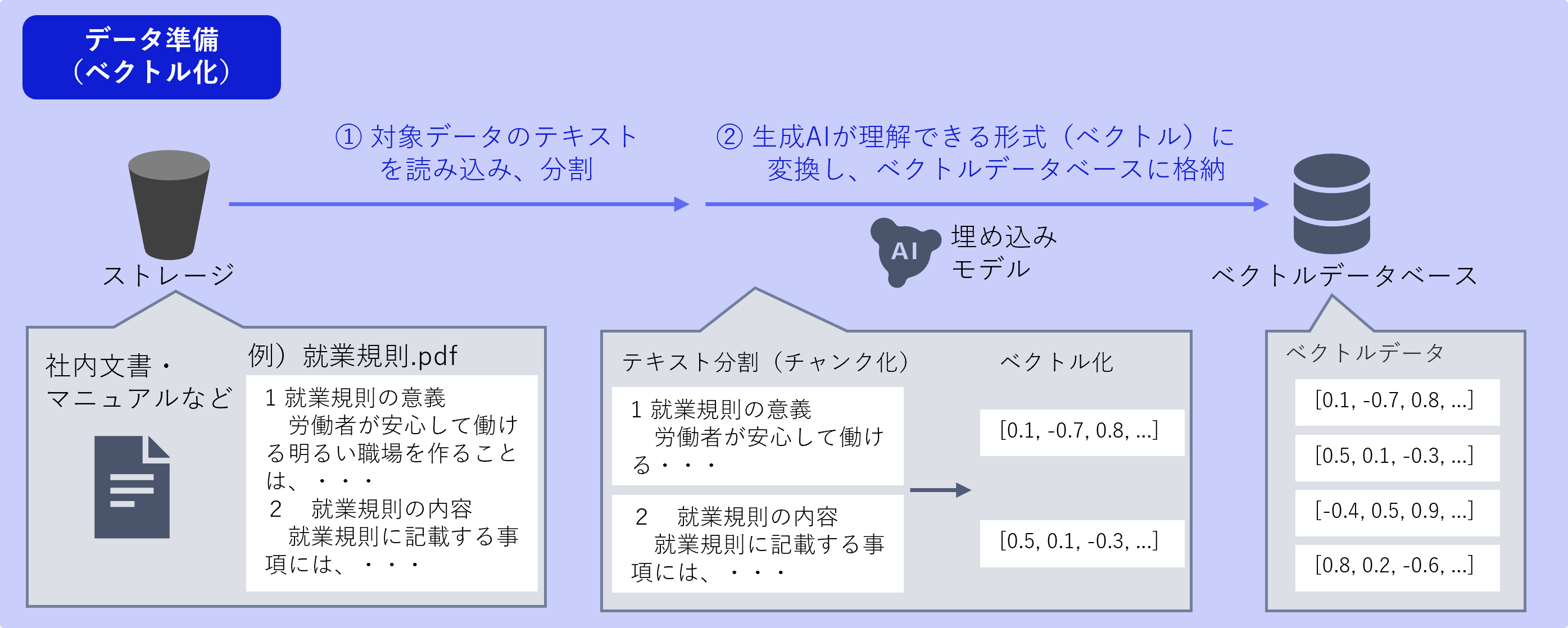
1. データ準備フェーズ
社内文書やマニュアルなどを、生成AIが理解できる形式(ベクトル)に変換し保存します。
主に2つのステップがあります。
- テキスト分割:対象データのテキストを読み込み、長い文書を適切な長さの断片(チャンク)に分割
- ベクトル化:各断片を数値の配列(ベクトル)に変換し、データベースに格納
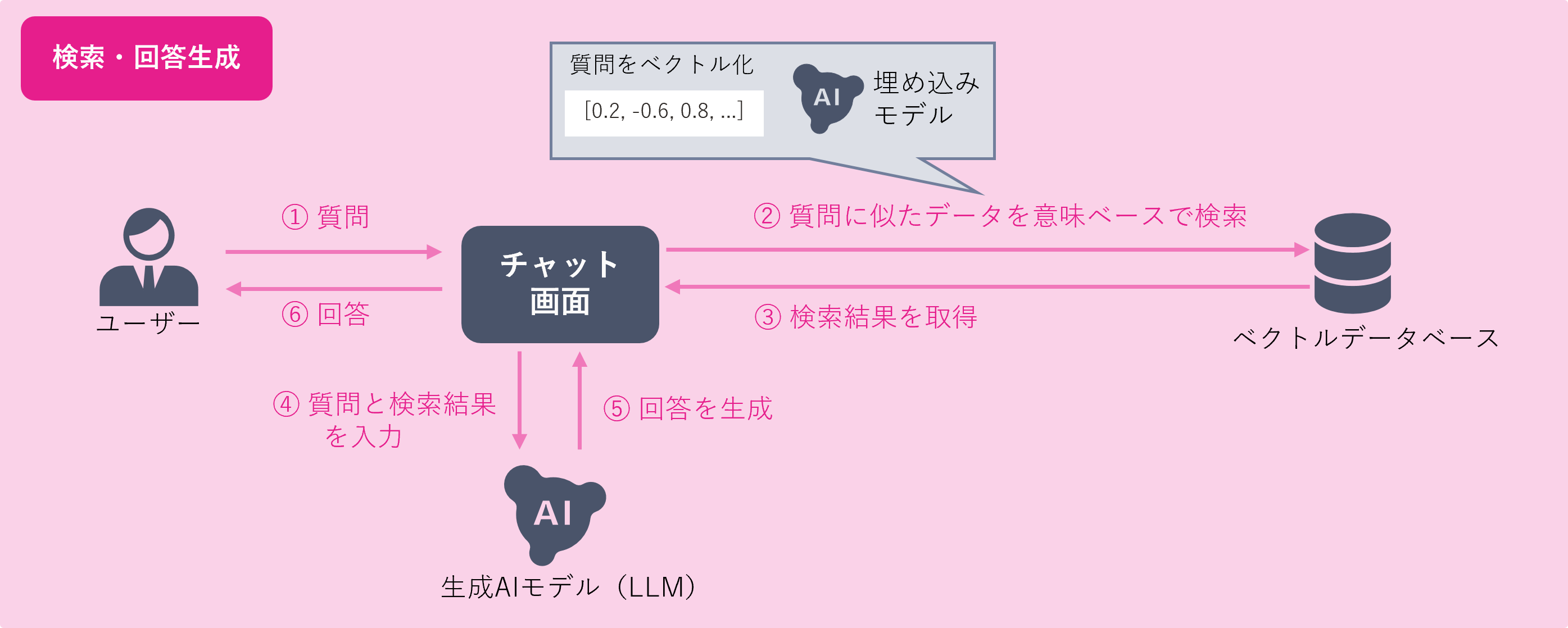
2. 検索・回答生成フェーズ
ユーザーの質問に関連する文書を意味ベースで検索し、取得した関連文書を参考にして質問に回答します。
以下は、実際にユーザーが質問した際の処理内容です。
- 質問のベクトル化:ユーザーの質問文を数値の配列に変換
- 類似度検索(ベクトル検索):データベースから質問に似た内容の断片を検索
- プロンプト作成:検索結果をもとに、生成AIへの入力を作成
- 回答生成:構築されたコンテキストをもとに最終的な回答を作成
4 Oracleを活用した構成例
それでは、RAGの仕組みが理解できたところで、社内ナレッジ検索アプリケーションを構築する場合について考えてみましょう。OCI上ではどのようなアーキテクチャで実現できるのか、その一例を紹介します。
今回構築したアプリケーションは、以下のOCIサービスで構成されています。
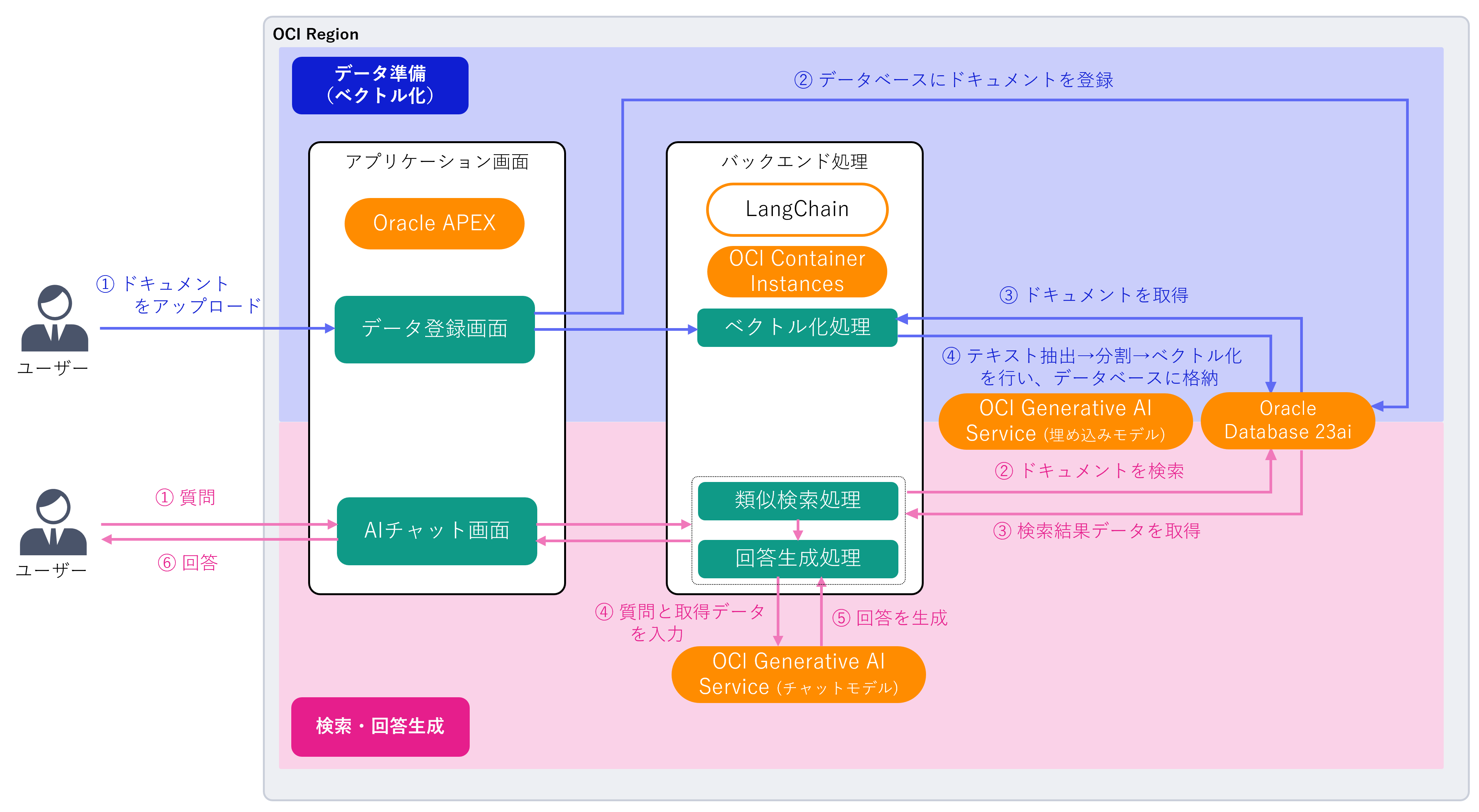
- アプリケーション画面:Oracle APEX
- バックエンド(RAG)処理:OCI Container Instances
- LangChain(※)を利用して、Oracle Database 23aiとOCI Generative AI Serviceを連携しています。
- ベクトルデータベース:Oracle Database 23ai
- 生成AI(LLM):OCI Generative AI Service
- 埋め込みモデル: cohere.embed-multilingual-v3.0
- チャットモデル: cohere.command-r-plus-08-2024
※ LangChainとは
OCIとは独立したオープンソースのフレームワークであり、生成AI(LLM)を使ったアプリケーションを効率的に開発するためのものです。
LangChainは、いくつかの「部品(関数)」と、それらを「組み合わせる仕組み」を提供します。
例えば、RAGのデータ準備フェーズでは、文書のテキスト化やテキストの分割処理が必要ですが、そのような機能を関数として用意しており、開発者が簡単に利用できるようになっています。
4.1 RAGシステム実現のための6ステップ
ここまでお話ししてきたとおり、社内ナレッジ検索はRAGの仕組みを使って実現することができます。
本章では、OCIにおけるRAGシステムの実現手順について、一例をステップに分けて紹介します。
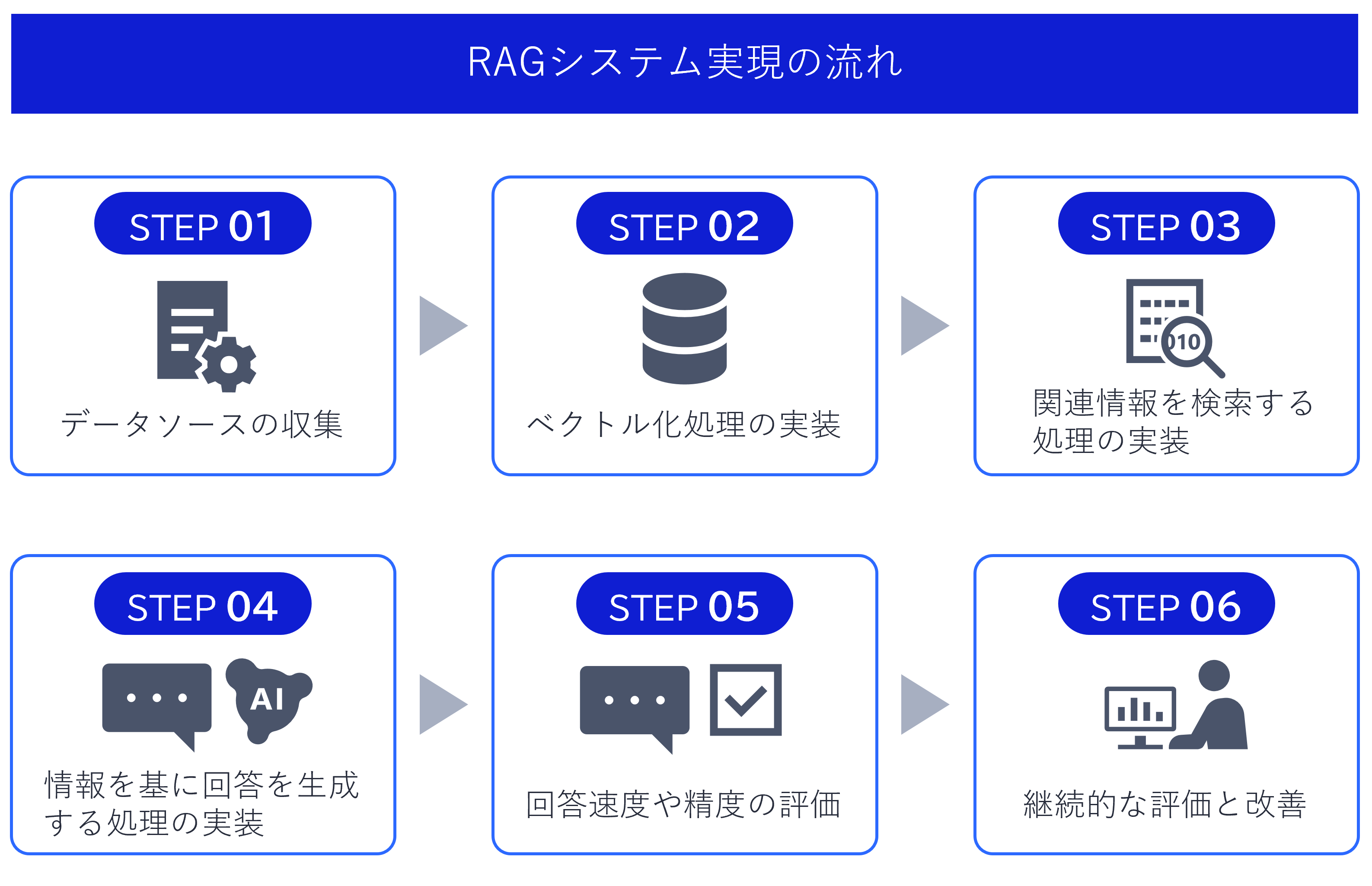
なお、本章のSTEP02は“「データ準備」と「検索・回答生成」フェーズ”の章で解説した「データ準備」フェーズに、STEP03、STEP04は「検索・回答生成」フェーズに対応しています。
STEP 01: データソースを収集する
まず、社内のナレッジベースとなる文書を収集します。
例えば、マニュアル、FAQ、社内ドキュメントなどが含まれます。
今回は、収集した文書をOracle Database 23aiに格納しましたが、OCIオブジェクトストレージなど他のストレージサービスを利用しても問題ありません。
ポイント
データを効果的に活用するためには、前処理(クリーニング)を行います。
具体的には、重複削除・不要語除去・段落分割・フォーマット統一などを行い、情報を構造化します。
STEP 02: 生成AIが理解できる形式に変換する(ベクトル化)処理の実装
今回は、下記の処理をOCI Container Instances上に実装しました。
- 1. LangChainを用いて、文書(PDF、テキストファイル等)やテーブルの内容をテキストに変換します。
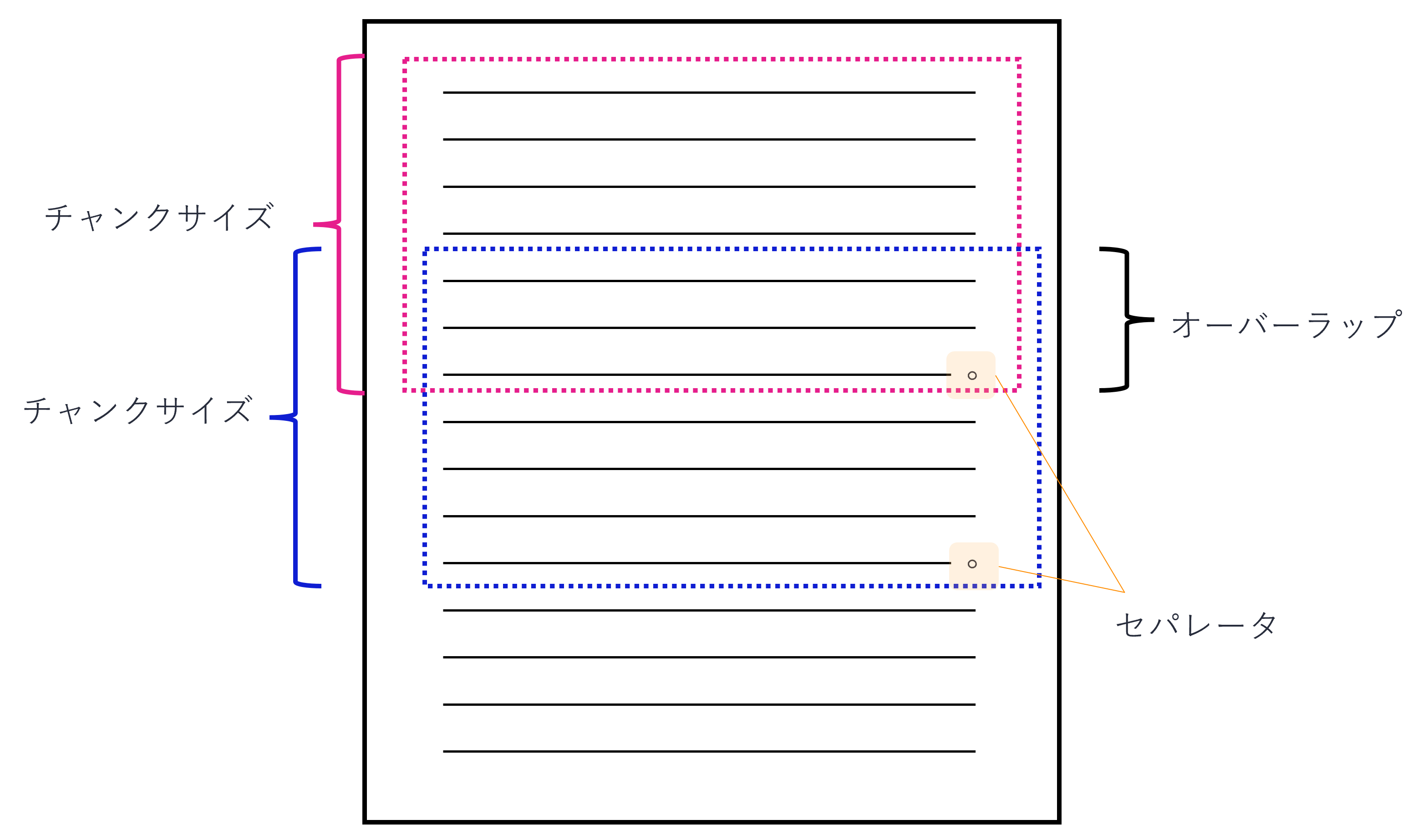
- 2. LangChainを用いて、長いテキストを適切な長さに分割(チャンキング)します。分割された短いテキストのことを「チャンク」と呼びます。
- セパレータ:文章をどこで区切るかの「目印」を指定します。ここで指定した文字列を優先的に探し、その箇所で文章を区切ろうとします。通常、句点や改行などが使われます。
- チャンクサイズ:ここで指定したサイズ(トークン数)に基づいてテキストが分割されます。
- オーバーラップ:チャンク間のオーバーラップを指定します。これにより、前のチャンクと次のチャンクの一部が重複するようになります。
- 3. OCI Generative AI Serviceの埋め込みモデルを用いて、分割したテキストを数値の配列(ベクトル)に変換します。
- 4. 変換したベクトルをOracle Database 23aiに格納します。
ポイント①
このベクトル化のプロセスでは、文書の意味を保持しつつ検索効率を高めるために、適切なチャンクサイズやオーバーラップを設定することが重要です。
例えば、チャンクサイズが小さすぎると重要な情報が失われる可能性があります。一方でサイズが大きすぎるとノイズとなる不要な情報も含まれてしまい、回答の精度が下がる可能性があります。
ポイント②
Oracle Database 23aiには、文書(PDF、テキストファイル等)のテキスト変換、テキスト分割、ベクトル化といった機能が備わっており、本ステップの一連の処理をデータベース内で完結させることができます。外部システムとの連携ポイントを減らすことでセキュリティリスクを低減できるため、機密性の高い情報のベクトル化に有用なアプローチとなります。
STEP 03: 関連情報を検索する処理の実装
関連情報の検索処理を、OCI Container Instances上に実装します。
-
ユーザーの質問をOCI Generative AI Serviceの埋め込みモデルを用いてベクトルに変換します。
-
Oracle Database 23aiのベクトル検索機能を利用して、質問に関連する文書のチャンクを検索します。
-
類似度が高い順にチャンクを並べ替え、上位4件を取得します。
このステップ(チャンクのスコアリング)で重要なパラメータや設定について説明します。- メタデータ:ベクトル検索で得られたチャンクをメタデータ(文書の性質を説明する付加情報)によって絞り込むことができます。
- Top-k:プロンプトに含めるチャンクの数を設定します。類似度が高い順番に並び替えたチャンクからK件を取得します。
- 閾値:類似度の最小値を指定します。閾値以上の類似度を持つチャンクのみプロンプトに含まれます。
- リランク:リランクモデルを使って、一回目のベクトル検索で得られたチャンクの類似度を再評価し、順位を付け直します。
ポイント①
スコアリングロジック(メタデータ、Top-k、閾値、リランクなど)を工夫することで、より関連性の高いチャンクを取得しやすくなります。
一方で、質問と関連性の低いチャンクを取得してしまうと、的外れな回答が生成される可能性があるため、検索方法の調整は重要です。
ポイント②
効率的にベクトル検索を行うための技術として、ベクトルインデックスがあります。Oracle Database 23aiにはベクトルインデックスを作成する関数が用意されています。ベクトルインデックス技術にはいくつか種類があるため、扱うデータや要件に応じて適切なインデックスを選択し、ベクトル検索を高速化するとよいでしょう。
STEP 04: 回答生成処理の実装
検索結果をもとに回答を生成する処理をOCI Container Instances上に実装します。
-
取得した4件のテキストを、生成AIが理解できる形式に整形し、「以下のコンテキストに基づいて、質問に回答してください」という指示を与えます。
- プロンプト例:以下のコンテキストに基づいて、質問に回答してください。
### 質問:
{ユーザーの質問文}
### コンテキスト:
文書1:{テキスト1}
文書2:{テキスト2}
文書3:{テキスト3}
文書4:{テキスト4} -
整形したテキストを、OCI Generative AI Serviceのチャットモデルに入力します。
-
生成された回答をユーザーに返します。
ポイント
プロンプトの指示文を工夫することで、生成AIがより適切な回答を生成できるようになります。
例えば、質問の意図を明確にするための追加情報を加えたり、回答のフォーマットを指定したりすることが有効です。
STEP 05: 回答速度や精度の評価を行う
ベクトル化・検索・回答生成処理の実装が完了したら、回答速度や精度の評価を行い、調整します。
-
ユーザーが実際に聞きそうな質問をいくつか用意して、それぞれに対して正しく回答できるかを確認します。
-
回答がわかりやすいか、正しい情報を伝えているか、自然な文章になっているかを評価します。
-
もしうまく回答できていない場合は、「なぜうまくいかなかったのか」を調べ、情報の検索方法や回答生成時の設定を細かく調整していきます。
STEP 06: 継続的な評価と改善を行う
RAGシステムは作ったら終わりではなく、実際に使われ始めてからも定期的に確認し、使いやすく改善し続けることが大切です。
新しい情報(例:社内文書の更新、FAQ追加など)が出てきた場合はデータベースにその情報を反映することで、常に最新の知識に基づいた回答が可能になります。
システムのログを分析し、「どの質問が多いか」や「回答の品質に問題はないか」といった点を定期的にモニタリングします。
また、ユーザーからのフィードバックやクリックデータなどをもとに、ベクトル検索処理やプロンプトの改善を行うことで、継続的な品質向上を図ることが可能です。
こうした継続的な改良を繰り返すことで、長期間にわたってユーザーに満足してもらえるシステムを作ることができます。
4.2 RAGシステムの動作例
ではRAGシステムの動作イメージを掴んでいただくために、RAGを使わない場合とRAGを使った場合で、生成AIからの回答を比較してみましょう。
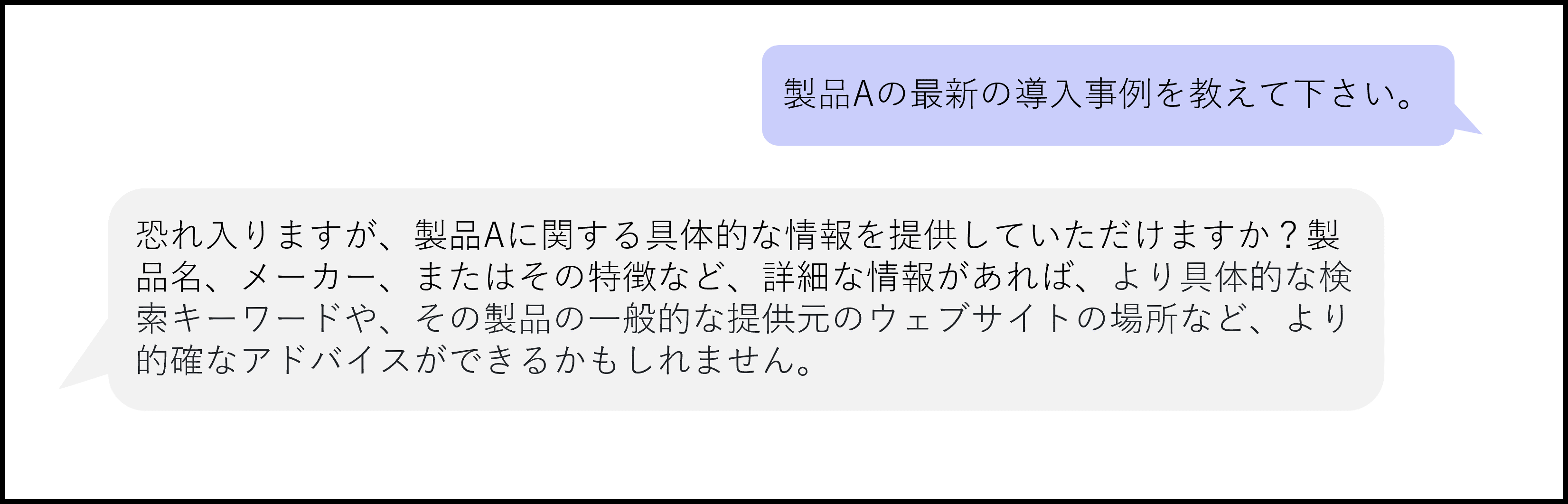
ここでは「製品Aの最新の導入事例を教えてください。」という質問をしてみます。
- RAGを使わない場合
生成AIモデルは製品Aの導入事例についての情報を持っていないため、「具体的な情報を提供してください」という回答が出力されます。
※OCI Generative AI Serviceの「cohere.command-r-plus-08-2024」モデルによる回答です。
- RAGを使った場合
続いて、今回作成したアプリケーションに製品Aの導入事例情報を登録してから質問をしてみます。
登録したデータは以下のとおりです。
製品A 導入事例集
当社が提供する革新的なソリューション「製品A」は、その高い汎用性と優れたパフォーマンスにより、様々な業界のお客様から高い評価をいただいております。
製品Aは、特にデータ分析、業務プロセス最適化、顧客関係管理(CRM)の分野で豊富な導入実績がございます。
最新の導入事例として、昨年の第3四半期に実施された〇×株式会社への導入プロジェクトが挙げられます。〇×社では、製品Aの導入により、複雑なデータ処理を自動化し、業務効率を30%向上させ、年間数百万ドルのコスト削減を実現しました。このプロジェクトは、製品Aの導入規模としても最大級であり、顧客のビジネス課題解決に大きく貢献した成功事例です。
この〇×株式会社での導入事例に関する詳細なレポートおよびお客様のインタビュー動画は、当社の公式ウェブサイトの導入事例セクション [ウェブサイトのURL] にて公開しております。
その他、△□商事株式会社でのサプライチェーン最適化への導入(一昨年第4四半期)、株式会社□〇でのAIを活用した顧客行動予測システムへの統合(本年第1四半期)などの事例もございます。
先ほどと同様に質問してみると、登録した情報をもとに製品Aの導入事例について回答が出力されます。
※OCI Generative AI Serviceの「cohere.command-r-plus-08-2024」モデルによる回答です。

5 RAGの回答精度向上に向けた取り組み
ここまでRAGの基本的な実装方法をご紹介しましたが、実際の運用では、「質問と無関係な情報ばかり参照してしまう」「専門用語を理解できず、的外れな回答が返ってくる」など、さまざまな課題が存在します。
これらの課題に対処するためには、前章の各手順におけるポイントを見直し、精度向上に取り組むことが重要です。
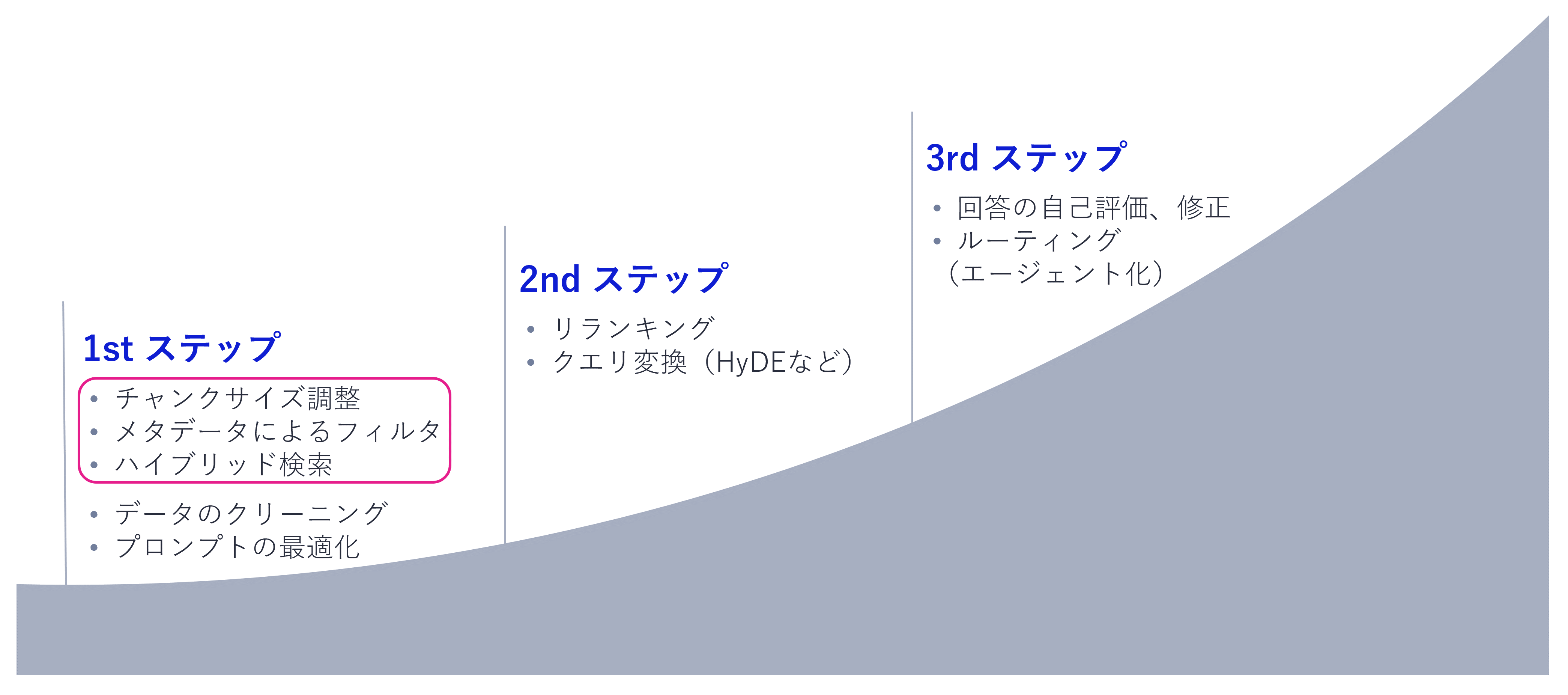
5.1 精度向上のアプローチ
RAGには精度向上のためのさまざまな手法が提案されています。ここでは1st ステップのうち、チャンクサイズの調整、メタデータによるフィルタ、ハイブリッド検索に焦点を当てて解説します。
チャンクサイズの調整
チャンクサイズの重要性
チャンクサイズが適切でないと、以下の問題が発生する可能性があります。
- チャンクが大きすぎる場合: 検索や処理の効率が低下し、不要な情報も含まれてしまう
- チャンクが小さすぎる場合: 文脈が分断されて意味が失われ、検索結果が断片的になる
最適なチャンクサイズの選び方
適切なチャンクサイズを選ぶには、以下の要素を考慮する必要があります。
- データの特性:文書の構造や内容の複雑さ
- 使用目的:短い質問への回答なのか、広範な背景情報の提供なのか
- 検索精度と生成品質のバランス
実際の運用環境では、異なるサイズでテストを行い、検索精度や生成結果の品質を比較することで、最適なバランスを見つけることが重要です。
メタデータによるフィルタ
RAGにおけるメタデータとは
文書の内容そのものではなく、文書の性質を説明する付加情報です。
一般的には、タイトル、作成日、著者、所属部門、文書カテゴリ、バージョンなどが含まれます。
メタデータフィルタリングの効果
ベクトル検索時に、メタデータ条件によるフィルタリングを組み合わせることで、ユーザーの意図に即した情報のみを厳選でき、より正確な回答を生成することができます。また、ベクトル検索の対象チャンク数を削減することで、処理速度の向上も期待できます。
例えば、以下のような絞り込みが可能です。
- 部門による絞り込み:「法務部の文書のみ」
- 日付による絞り込み:「2025年以降の文書のみ」
- 文書種別による絞り込み:「正式版のみ(下書きを除外)」
RAGシステムでメタデータフィルタリングを行う場合、JSON形式のメタデータがよく使われますが、こちらは手軽に扱える一方で、複雑な条件での絞り込みや、データ量の増加に伴うパフォーマンス面で課題が生じることも少なくありません。
一方で、Oracle Databaseでは構造化データに対する属性検索(リレーショナル検索)と非構造化データへの意味検索(ベクトル検索)を同一データベース上で組み合わせることができるため、リレーショナル検索でのメタデータフィルタリングが可能です。これにより、複雑な条件でのフィルタリングを高速に実行できます。
ハイブリッド検索
ハイブリッド検索とは
ハイブリッド検索は、キーワード検索とベクトル検索のそれぞれの長所を組み合わせた手法です。キーワード検索は特定の単語や句を含むドキュメントを正確に抽出できる一方、ベクトル検索は意味的な類似性を捉えることができます。両者の長所を組み合わせることで、検索精度を向上させることができます。
ハイブリッド検索を実現するための開発プラットフォーム
ハイブリッド検索を実装するには、検索技術を高度に統合できる開発プラットフォームを選定する必要があります。
Google Vertex AI、Azure AI Search、Amazon OpenSearch Serverlessなどが代表例ですが、Oracle Database 23ai(Oracle AI Vector Search機能)も候補の一つです。
Oracle AI Vector SearchのネイティブなSQL操作を使用して、類似検索とリレーショナル検索を組み合せることができます。ハイブリッド検索のロジックにおけるさまざまなパラメータを設定できるのが特徴であり、使用するデータに合わせて細かな調整が可能です。
RAGの精度向上は、単なる技術的改善にとどまらず、業務効率・意思決定の質・顧客満足度といったビジネス成果に直結する重要な要素です。
プロンプト設計やデータ前処理、検索アルゴリズムといった各工程を最適化することで、必要な情報に迅速かつ正確にたどり着けるRAGを実現できます。
これらのチューニングはそれぞれが専門的な知見を要し、自社の文書特性や利用目的に応じて最適な組み合わせを見つけ出すには相応の試行錯誤が伴います。
もし、何から手をつけるべきか判断が難しい、あるいはより迅速かつ確実にビジネス成果に繋がるRAGを構築したいとお考えの場合には一度専門家の視点を取り入れることをお勧めします。
6 おわりに
本記事の内容について詳しく知りたい方は以下よりお問い合わせください。
NECでは、生成AIによる企業データ活用の第一歩をお手伝いするサービスとして、OCI上に生成AIのPoC基盤を構築し、技術支援を行うサービスを提供しております。詳しくは下記の資料をご覧ください。
Oracle Cloud 生成AI PoC環境構築サービス紹介資料

Oracle Cloud 生成AI PoC環境構築サービスでは、企業データの活用を検証するための生成AI基盤をお客様のOCI環境に迅速に導入します。また、導入した生成AI基盤での検証をサポートする技術支援オプションを提供します
本サービスについての代表的なユースケースについてもご紹介します。
Oracle×生成AI 第3回では「新機能 Select AI Agent を試して分かった AI エージェントの使い道」を取り上げています。
ブログの一覧はこちらから