Japan
サイト内の現在位置
AIを活用したフィッシングサイト判定
NECセキュリティブログ2026年3月6日
本記事では、AIによるフィッシングサイトの判定方法を検討し、検証した結果を紹介します。
目次
背景
昨年、世界で最もフィッシングメールの標的になった国は日本で、その要因の一つとして、攻撃者がAIを利用して自然な日本語の文章を生成できるようになり、言語の壁が低くなったことが報じられています [1]。フィッシングメールから誘導されるフィッシングサイトでも、不自然な日本語などが減り、より巧妙になっています。本記事では、防御側としてもAIを活用し(OpenAI GPT-5.2[2]を使用)、フィッシングサイトか正規サイトかを判定する方法を検討し、検証してみました。なお、本記事の検証結果は、特定の大規模言語モデルおよび本検証で用いたプロンプト条件下でのものであり、すべてのAIモデルに同様に当てはまるものではありません。
[1]。フィッシングメールから誘導されるフィッシングサイトでも、不自然な日本語などが減り、より巧妙になっています。本記事では、防御側としてもAIを活用し(OpenAI GPT-5.2[2]を使用)、フィッシングサイトか正規サイトかを判定する方法を検討し、検証してみました。なお、本記事の検証結果は、特定の大規模言語モデルおよび本検証で用いたプロンプト条件下でのものであり、すべてのAIモデルに同様に当てはまるものではありません。
人間によるフィッシングサイトの判断方法
正規サイトかフィッシングサイトかを判断するときに、最もよく言われるのは、URLのドメイン名の確認です[3]。ドメイン名が正規サイトのものであれば、フィッシングサイトの可能性は非常に低くなります(正規サイトが侵害され悪意のあるものが仕掛けられることはあり得ますが、非常にまれなケースとなります)。有名なサービスのサイトであれば、正規のドメイン名も知られているため、判定は容易です。しかし、少しマイナーなものや海外のサービスになると、正規のドメイン名が不明な場合もあり得ます。そうなると次は、サイトの内容や見た目、ソースコードなどから、判定していくことになりますが、それを行うには多くの経験や知識が必要になり、難易度が高くなります。
AIによるフィッシングサイト判定の前提条件
そこで、本記事では、OpenAI GPT-5.2[2]を活用して、サイトのソースコードから、正規サイトかフィッシングサイトかを判定する方法を検討し、検証した結果を掲載しています。
今回は検証のため、日本語のWebサイトで、あらかじめ人間による分析により、フィッシングサイトと判断した5つのサイト(A~E)と、正規サイトと判断した5つのサイト(F~J)の取り込みデータを用意しました。
AIに渡すデータは、ソースコードのファイル(HTMLファイル・JSファイル・CSSファイル)のみです。
なお、前提として、一般に大規模言語モデルのAIは、公開情報からのデータ収集を通じて、「どのブランドがどのドメインや画像などを使っているか」という情報を有している可能性があり、今回はソースコードによる判定の検証のため、それらの情報による判定はしない旨の条件をプロンプトで入力しています。
AIに判定基準を特に与えなかった場合
まずは、フィッシングサイトかどうかを判定する基準などは特に与えずに、単純に、AIにフィッシングサイトであるかの確率を0~100%で判定してもらいました。それが以下の結果(図1)になります。
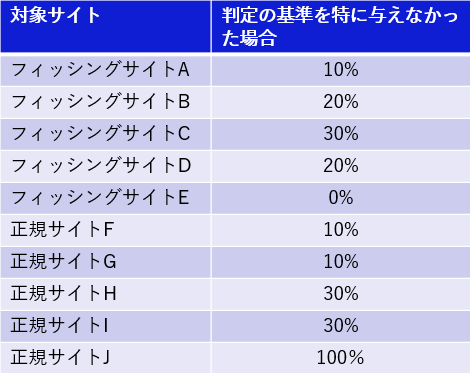
フィッシングサイトである確率が、フィッシングサイトで低く、逆に正規サイトで高いというケースが散見される結果となりました。
AIにフィッシングサイトの判定基準を与えた場合
次に、フィッシングサイトかどうかを判定する基準を与えた場合です。
フィッシングサイトかどうかを判定する基準として、今まで人間で調査してきた際にフィッシングサイトでよく見られた特徴(例えば、パスワードを入力した際に伏字にならない・セッション保護のhiddenフィールドが無いなど)を分析して項目化し、より重要な項目はフィッシングサイトとするスコアを高く調整するなど重みづけを行いました。それが以下の図2(一部のみ公開とさせて頂きます)となります。

そして、上記の判定基準もAIに与えて判定してもらった結果が、以下の図3になります。
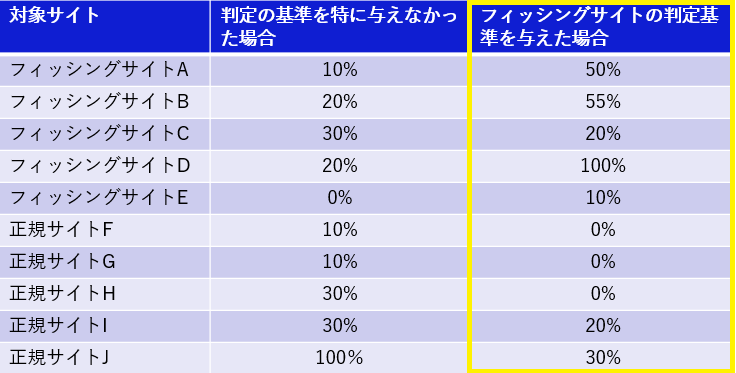
フィッシングサイトである確率が、ほとんどのフィッシングサイトで高くなり、逆に正規サイトでは低くなっており、判定の精度は大幅に向上しました。しかし、一部の正規サイトで少し高いケースがまだ見られます。
AIにフィッシングサイトと正規サイトの判定基準を与えた場合
次に、フィッシングサイトかどうかを判定する基準だけでなく、正規サイトかどうか判定する基準も与え、AIに判定してもらいました。
正規サイトかどうかを判定する基準として、フィッシングサイトの特徴を分析した際と同様に、今まで人間で調査してきた際に見られた特徴(例えば、CSRF対策用のhiddenパラメータがある・認証フローが多段階など)を項目化し、重みづけを行いました。それが以下の図4(一部のみ公開とさせて頂きます)となります。

そして、フィッシングサイトの判定基準(図2)と、正規サイトの判定基準(図4)の両方を、AIに与えて判定してもらった結果が、以下の図5になります。
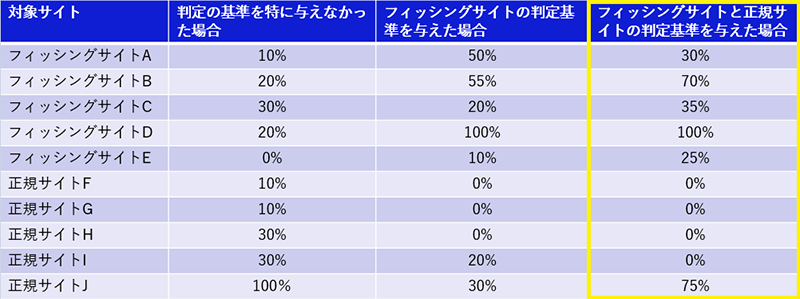
各フィッシングサイトにおいて概ねフィッシングサイトである確率がさらに上昇し、正規サイトにおいてフィッシングサイトである確率が減少しており、精度はさらに向上しました。ただし、それぞれにおいて一部のサイトで逆の増減が起きたサイトもありました。これは、フィッシングサイトでも正規サイトの特徴の一部を持っているケースや、正規サイトでも実装不備やミス等でフィッシングサイトの特徴に該当するケースがあり、誤判定されていることが分かりました。これらは、判定項目の見直しや重みづけの調整などで改善していけるものと思われます。
まとめ
AIを活用したフィッシングサイトのソースコード判定では、AIに判定する基準を何も与えないときよりも、フィッシングサイトの判定基準を与える、さらに正規サイトの判定基準も与えることで、より精度の向上ができることを示しました。
フィッシングサイトかどうかの最終判断は人間が行うものと思いますが、AIによるソースコード判定結果を参考情報として活用することで、増加するフィッシングへの対処、分析要員の人数不足やスキル不足への対処などに対応していくことができるものと思われます。本稿の内容が、今後、AIをセキュリティに活用していく検討に役立てていただければ幸いです。
参考文献
- [1]日本が今、最も狙われている【続編】—プルーフポイントのデータからみる生成AI時代のメール脅威と対策https://www.proofpoint.com/jp/blog/email-and-cloud-threats/email-threats-and-countermeasures-generative-ai-age
- [2]
- [3]フィッシング詐欺とは?事例と対策、対処法を徹底解説
https://www.fielding.co.jp/service/security/measures/column/column-29/
執筆者プロフィール
平島 究(ひらしま きわむ)
担当領域:サイバーセキュリティインテリジェンス
専門分野:サイバーインテリジェンス、ログ解析、AWSセキュリティ設計
各省庁向けのサイバーインテリジェンスやログ解析等の業務に従事。堅牢化コンテスト「Hardening 2018」でグランプリ受賞。CISSP、GPEN、情報処理安全確保支援士、AWS Certified Security - Specialtyを保持。

執筆者の他の記事を読む
執筆者プロフィール
上野 隆治(うえの りゅうじ)
担当領域:マネージドセキュリティサービス
専門分野:PDNS(Protective DNS)、脆弱性診断
PDNS(Protective DNS)業務に従事。CISSP、情報処理安全確保支援士、認定Webアプリケーション脆弱性診断士、認定ネットワーク脆弱性診断士を保持。

執筆者の他の記事を読む
執筆者プロフィール
山田 英直(やまだ ひでなお)
担当領域:リスクハンティング
専門分野:CSIRT、Splunk
大規模国際イベントのCSIRTのメンバーとして脅威インテリジェンス業務を中心に担当。現在は脆弱性診断/ペンテスト、内外のCSIRT運用支援を担当し、社内外組織のセキュリティ成熟度向上に取り組む。CISSPを保持。

執筆者の他の記事を読む
アクセスランキング