Japan
サイト内の現在位置
「検索で当てる」から「手順で外さない」へ:Skillsを持つAgentでセキュリティQ&Aを安定化
NECセキュリティブログ2026年2月27日
- LLM単体
- LLM + Web Search
- LLM + Skills
を比較し、「検索で当てに行く」よりも判断手順(= 型)を足すアプローチ(Skills)がどの程度有効かを整理します。
目次
背景:セキュリティ領域で「Agent Skills」が効きやすい理由
今回使用するCTI-Benchの問題は、一般知識に比べて次のような性質があります。
- 参照先が固定:ATT&CKのDetection / Mitigations / Data Sourcesのように、答えが“特定セクションの表現”に紐づく
- 用語が似ている:近いテクニックやCWEが混同されやすい(例:T1218.* の派生や、認証/認可の取り違え)
- 選択問題特有の罠:選択肢の文言一致・否定表現・問われている軸(DetectionなのかMitigationなのか)の切り分けが重要
このときLLMは、知識そのものよりも
- 「どのセクションを見るべきか」
- 「似た選択肢をどう切り分けるか」
といった判断手順の違いで誤りやすくなります。
そこで今回は、エージェントにAgent Skills(判断手順のガイド)を持たせて、必要なときに読み込めるようにします。
評価データと前提
対象データ
ベースライン(725問)
モデルによる知識差はどの程度表れるかを評価するため、GPT-5-miniとGPT-5で比較した結果は、次の表1のようになります。
| モデル | Accuracy | correct / used |
|---|---|---|
| GPT-5-mini | 38.21% | 277 / 725 |
| GPT-5 | 54.07% | 392 / 725 |
結果としては、モデル能力差が、そのままAccuracy差として現れています。
「知識拡張」を比較
次に、GPT-5-mini単体で不正解だった448(725-277)問を対象に、ツールやナレッジを追加した際の挙動を比較します。
OpenAIが提供しているWeb Search [8]をtoolsとして付与して実行した結果は表2の通りです。
[8]をtoolsとして付与して実行した結果は表2の通りです。
| 設定 | Accuracy | correct / used |
|---|---|---|
| GPT-5-mini(448問のベースライン) | 0.00% | 0 / 448 |
| GPT-5-mini + Web Search | 23.88% | 107 / 448 |
この448問は「GPT-5-mini単体で不正解だった集合」のため、ベースラインのAccuracyは0%になります。そのうえで、Web Searchを使用することで107問は正解に到達できました。
一方で、検索は万能ではありません。セキュリティMCQでは「答え」そのものではなく「材料」が増えやすく、
- ノイズの多い検索結果
- 誘導的なブログや二次情報
- 設問軸の取り違え(DetectionなのにMitigationを読んでしまう等)
といった要因の影響を受ける可能性があります。
また、セキュリティ業務でLLMを活用する際の現実的な制約として、ネットワーク分離(閉域網)やSaaS利用制限などにより、Web検索を含む外部アクセスを常時許可できないケースがあり、回答精度向上の課題となります。
実装:LangChainでSkills(専門ガイド)付与
今回は汎用的なLLMさえ用意できれば、比較的容易にエージェント機能を作成できるLangChain[9]を使用します。
Skillsとは
本稿のSkillsは、問題タイプごとの解き方ガイドです。
たとえば「ATT&CKのDetectionを問う設問」「CWEのMitigationを問う設問」など、設問のタイプに応じて、
- 何を確認するべきか
- どの順で判断するべきか
- どこで混同しやすいか
といった手順(判断の型)をテキストで固定しています。
セキュリティのMCQで効くのは、最新情報よりも「軸を外さない」ことが多いため、Skillsはこの弱点に直接効きます。
今回用意したSkills
今回用意したSkillsは次の4種類となります。
- mitre_attack_techniques_guidelines
- mitre_cwe_guidelines
- mitre_capec_guidelines
- cti_guidelines
例えばATT&CK Techniques向けSkillsでは、
- テクニックIDの厳密照合(Txxxx / Txxxx.xxx)
- 参照すべきセクション(Detection / Mitigations / Data Sources / Examples)
- 似た選択肢の混同回避(例:T1218.* の派生)
をチェックリスト形式で固定します。
例:mitre_attack_techniques_guidelines.md
# MITRE ATT&CK Techniques回答ガイド
## 対象範囲
- Enterprise / ICS / Mobile / Cloud / None の差異を前提にする。
(詳細省略)
## 重要ポイント(対象の特定)
(詳細省略)
## 参照セクション
(詳細省略)
## チェックリスト
(詳細省略)
load_skill:Skillsをツールとして呼び出す
LLM側が「必要なときだけ」ガイドラインを読み込めるよう、Skillsをツール関数として用意します。[10]
入力:skill_name(スキル名)
出力:スキル本文(見つからない場合は利用可能なスキル一覧)
これにより、モデルは最初から全種類のガイドラインを抱え続けるのではなく、必要なときに必要な手順を“取り出す”という使い方ができます。
SkillMiddleware:モデルに「使えるスキル一覧」を提示する
load_skillを用意しただけでは、モデルが「どんなスキルがあるのか」、「いつ呼べば良いのか」を知らないままになります。
そこでLangChainのミドルウェアで、システムプロンプトへ
- 利用可能なスキル一覧(名前と説明)
- 詳細が必要ならload_skillを使う
というガイダンスを追記します。
図1にSkillsを活用した回答の流れを示します。
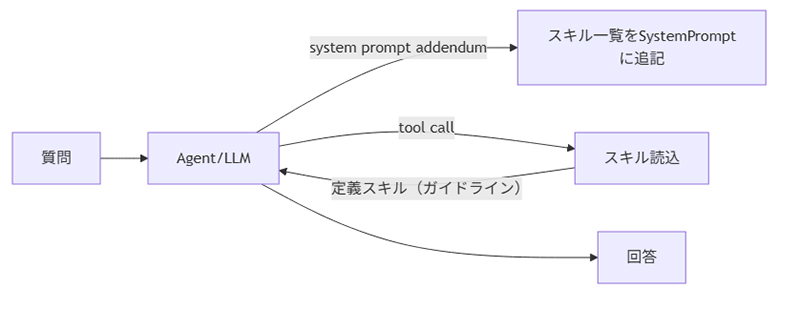
結果:Skills付与は、Web Search並に効いた
448問の比較結果は次の通りです。
| 設定 | Accuracy |
|---|---|
| GPT-5-mini(448問のベースライン) | 0.00% |
| GPT-5-mini + Web Search | 23.88% |
| GPT-5-mini + Skills | 27.96% |
差分は小幅な改善ですが、Skillsが効く理由は精度だけではなく、
- 判断の再現性(毎回同じチェックリストを踏ませやすい)
- “どこを見るか”の迷いを減らす(Detection/Mitigation/Data Sourceの混同を抑える)
という点にあります。
特に、セキュリティ運用では
- 出力の説明責任
- 手順の標準化
- 監査・引き継ぎ
が求められるため、Skillsによる“型”は実務上の価値が大きいと考えています。
最後に
今回は「Agent Skills」に絞り、判断の型を追加することで改善が見込めることを確認しました。
一方で、本稿では記載していないアプローチもいくつかあります。取り組み方次第で、さらなる精度向上が期待できます。
ただし、データの持ち方(粒度・メタデータ)を十分に設計しないままですと、期待したほど精度が伸びないケースもあります。
セキュリティの質問は特に、ファイルが読める/RAGがある、よりも
- どんな粒度で保存するか(章/見出し/表/箇条書き)
- 何をメタデータとして持つか(タイトル、セクション名、ID類など)
- どう検索して“該当箇所”に当てるか(ノイズ除去、スコアリング、引用)
といった設計が成果を左右しやすい分野です。
そのため次に進める場合、“当てに行けるデータ構造”と“探し方”を先に固めることで、効果を引き出しやすくなります。
今後も、セキュリティ領域で使いやすいAgentの形や、評価の進め方を継続して検討していきます。
参考文献
- [1]MITRE ATT&CKhttps://attack.mitre.org/
- [2]CAPEC - Common Attack Pattern Enumeration and Classificationhttps://capec.mitre.org/
- [3]CWE - Common Weakness Enumerationhttps://cwe.mitre.org/
- [4]Alam, Md Tanvirul et al. "CTIBench: A Benchmark for Evaluating LLMs in Cyber Threat Intelligence" (2024)https://arxiv.org/abs/2406.07599
- [5]CTI-Bench(GitHub)https://github.com/xashru/cti-bench
- [6]OpenAI Models: GPT-5-minihttps://platform.openai.com/docs/models/gpt-5-mini
- [7]GPT-5 System Cardhttps://openai.com/ja-JP/index/gpt-5-system-card/
- [8]Tools: Web Searchhttps://platform.openai.com/docs/guides/tools-web-search
- [9]LangChainhttps://www.langchain.com/
- [10]Skills - Docs by LangChainhttps://docs.langchain.com/oss/python/langchain/multi-agent/skills
- [11]Build a RAG agent with LangChainhttps://docs.langchain.com/oss/python/langchain/rag
- [12]Deep Agents Middlewarehttps://docs.langchain.com/oss/python/deepagents/middleware
執筆者プロフィール
水島 諒(みずしま りょう)
担当領域:セキュリティソリューション開発
AIセキュリティセンター/セキュアシステムプラットフォーム研究所にて、SOC業務や脆弱性管理の効率化に向けたAI活用の研究・実装を推進しています。

執筆者の他の記事を読む
アクセスランキング