
Japan
サイト内の現在位置
山本 康高のコラム
「飲める文庫」を実現するデータ分析

NEC データドリブンDX事業部
山本 康高
2018年4月24日
概要
NECは、名作文学の読後感をブレンドコーヒーの味わいとして表現した商品、「飲める文庫」を、珈琲豆の専門店である株式会社やなか珈琲様(以下、やなか珈琲様と略記)と開発しました。新聞、Web記事、TVなど、様々なメディアで取り上げられ、実際に販売した珈琲も当初想定を上回り大きな反響を得ました。今回はこの取り組みにAI技術がどのようにかかわっていたのかを簡単に紹介します。
本文
1.プロジェクトの始まり
「名作文学の読後感を珈琲の味として表現するAIを作ってほしい」、
NECのAI広報を担当する同僚からの依頼でした。「忙しすぎてついに・・・」と思いましたが、話を聞いてみると、
- AIが作るべき珈琲の味を指定し、カップテスターがそれを再現する。
- 作った珈琲は実店舗やWeb上で販売する。
- C&Cユーザーフォーラム&iEXPO2017(NECの展示会)前にある「読書の日」に合わせて広報し、NECのAIのプロモーションを行いたい。
とのこと。すなわち、商品企画をAIで支援し、本当に製品も作り、この取り組み自体をプロモーションのネタにするというもので、私が知る中では類例のないプロジェクトでした。第一印象で面白そうと感じ、人とAIとが共創する社会を目指すNECにとってもフラグシップになると思い、分析を引き受けました。
プロジェクトの目的:
- 先進的取り組みによるプロモーション効果の最大化
- 話題性の高い取り組みによるビジネスの拡大
2.プロジェクトの結果
本プロジェクトで得られた成果をまとめます。
プロモーション効果:
新聞、雑誌、Web記事、ラジオ、TV取材など、多数のメディアで反響を呼びました。今でもこれをきっかけとした多くのお客様から同様の企画の依頼が来ています。
ビジネス効果:
やなか珈琲様がWebで売り出した文庫型包装の限定ドリップバッグは、販売後40分で完売しました。その後、増産し、販売期間中で当初想定を大幅に上回る売れ行きであったと聞いています。
副次的効果:
このプロジェクトにおいて、カップテスターの方からは、「AIから指定された味はかなり極端で、今まで作ったことがないようなブレンドに挑戦することになった」とのコメントをいただきました。定性的ではありますが、AIが人の発想を広げる事例であり、これも本プロジェクトの成果の一つであると考えています。
3.実施した分析
名作文学の読後感を珈琲の味にするAI。一見、突拍子もないお題に見えますが、分析のタスクとしては「読後感」を「珈琲の味」に変換するというシンプルなものになります。本プロジェクトで実現したシステムのイメージを図1に示します。皆様が持たれたイメージも近いものなのではないでしょうか。
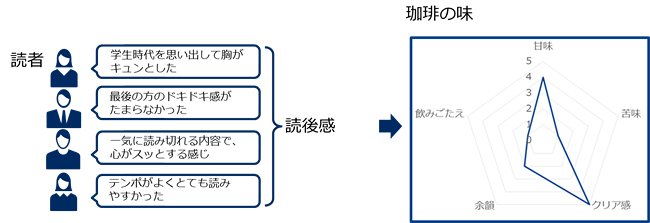
本プロジェクトで私たちが行った分析業務は、大きく分けると「学習データの構築」「学習の実施」「珈琲を実際に作る名作文学の味の推定」「レーダーチャート化」の4工程になります。以下、各工程を説明します。
- 工程1:
学習データの構築
AIには学習データが必要です。今回の場合、読後感に相当するデータが珈琲の味と紐づいているデータが「学習データ」になります。残念ながら、このようなデータは世の中にないため、このプロジェクトはデータ作りから開始しました。工程1-1: 学習データのフォーマット
- 読後感のデータとは?
Web上でも本のレビューをよく見かけます。これは本を読んだ感想なので読後感と捉えられます。そのため、レビュー文(テキストのデータ)を読後感と定義しました。当初は、文学作品の本文そのものをAIに学習させたいという意見もありましたが、作品それぞれでボリュームが異なることと、ストーリーには起伏があるため、どこを切り出すかで結果が変わると思いやめました。 - 珈琲の味とは?
通常、「味」は甘味、苦味、酸味、塩見、旨味の五味で表現されますが、珈琲の味の表現としては不自然です。そこでやなか珈琲様のアドバイスもいただきながら、最終的に、苦味、甘味、クリア感、余韻、飲みごたえ、の5つの指標で味を表現しました。これを味覚情報と呼びます。
以上から、学習データのフォーマットを表1のように定義しました。レビュー文の欄にテキスト情報が入り、そのレビュー文から想起される味覚情報には1を、そうではない味覚情報には0を付与していきます。
表1 学習データのフォーマット ID レビュー文 甘味 苦味 クリア感 余韻 飲み
ごたえ1 読後感を表すテキスト情報 2 : : : : : : : 工程1-2: ガイドラインの作成
ここでの課題は、どのようなレビュー文をどの味覚情報とみなすのか?ということです。多くの評価者でデータを作り出すようなケースであれば、統計的に妥当な総意を決めればよいのですが、今回は少人数でのデータ作成となりました。少人数の場合、ほぼ同じレビュー文であっても正解のつけ方(1とするか0とするか)が人によって食い違い、どちらが妥当かも決められないという問題が生じます。学習データが曖昧であると、AIも学習がうまくできません。そこで本プロジェクトでは、味覚情報毎に「ガイドライン」を作成しました。ガイドラインとは、例えば、「青春時代のなつかしさなどを感じた」など過去の甘酸っぱい記憶を早期させるレビュー文であれば「甘味」を1にするといった決め事を文書化したものです。これを評価者で共有しました。また、評価者に同じレビュー文を評価させ、食い違った場合には、見解が一致するように、その理由を議論し修正を繰り返することで完成させました。工程1-3: データ作成
著作権の違反を避けるために、アンケート企業の協力を得、本プロジェクト用のレビュー文を10,000件以上入手しています。そのレビュー文に対してガイドラインにそって1/0をつけることで学習データを作成しました。表2に学習データのイメージを示します。表2 学習データのイメージ ID レビュー文 甘味 苦味 クリア感 余韻 飲み
ごたえ1 これだけ読むだけでも十分価値があります。 0 0 0 0 1 2 久しぶりにここまで感動した本を読んだ気がします。 0 0 0 1 0 3 相手に自分の心が理解されない苦しさを感じた。 0 1 0 0 0 4 若いころ読んだ記憶がない。 0 0 0 0 0 : : : : : : : 学習データの話をすると、珈琲を作ろうとする名作文学に対して、この数値を入れれば完成なのではないか?と言われることがあります。確かに名作文学を珈琲の味に変換するだけであれば、それで構いません。しかしながら、今回のポイントは「AIによる支援」と「話題性」です。このデータを学習することでAIは任意のレビュー文からAIならではの味覚情報を推定できることが重要になります。レビュー文を珈琲の味にすることだけが目的ではない点をご留意ください。
- 読後感のデータとは?
- 工程2:
学習の実施
学習は、味覚情報毎に実施しました。学習には、NECのAI技術群「NEC the WISE」の一つで独自のディープラーニング技術「RAPID機械学習」を用いました。これにより、レビュー文のテキスト情報を入力すると、各味覚情報に当てはまるか否かを0から1の連続値でスコア化できる推定モデルが作れます。連続値を出力としたのは後述するレーダーチャートが作りやすかったためです。 - 工程3:
珈琲を実際に作る名作文学の味の推定
名作文学30作品を対象として、各作品のレビュー文を入力し、各作品の5つの味覚情報を推定しました。推定結果の一例を図2に示します。図2 味覚情報の推定結果の一例 
 拡大する
拡大する 図2では、各レビュー文の各味覚情報への推定結果が0~1の連続値として表現されていることがわかります。赤く塗られているセルはその中でも値の高かった場所を表しています。読者の総意が味覚情報となるように、一作品に対しても多くのレビュー文を用いて総合的に味覚情報を決めるようにしました。
- 工程4:
レーダーチャート化
図1に示したように、カップテスターの方にデータを渡す際には、各味覚情報はレーダーチャート化した方がよいと考えました。見た目としてなじみ深く、他作品との違いを視覚的に理解しやすいためです。レーダーチャート化は、各作品の味覚情報をとりまとめ、他作品との際がわかりやすくなるように統計処理しました。

最終的に、実際に珈琲を作る題材となった文学作品は、島崎藤村『若菜集』、太宰治『人間失格』、夏目漱石『吾輩は猫である』・『こころ』・『三四郎』、森鴎外『舞姫』の6作品になりました。これらは、いろんな味わいがあった方が良いとの考えからレーダーチャートがあまり似ていない作品を選んでいます。6作品のレーダーチャートがどのような形になったのかは下記サイトを参照してください。
4.最後に
本稿では、「飲める文庫」を実現した分析に関する概略をまとめました。昨今は、人とAIは「どちらがより優れているか」が注目されがちですが、NECは人とAIが協調し、新しいものを生み出すことを検討しています。このプロジェクトはプロモーションが目的ではありましたが、その一端を示すことができた事例の一つなのではないかと思っています。今後も、データ分析を通して、人の可能性を広げ、皆様の新たな価値創造を実現していきたいと思います。