
Japan
サイト内の現在位置
中野 淳一のコラム
データサイエンティストに求められるビジュアライゼーション力(基礎編)

NEC AI・アナリティクス事業部 (兼 AIプラットフォーム事業部 )
中野 淳一
2017年12月13日
概要
データサイエンティストはデータの特徴を正しく把握し、それを報告したり、機械学習などの後工程に活かしたりする必要があります。単純なデータ集計ではデータの特徴を把握しきれない場合も多いため、本コラムではデータを把握するために必要な、データ可視化(データビジュアライゼーション)の方法について紹介します。
本文
データサイエンティストに求められる能力は非常に多く、大別すると「ビジネス力、データサイエンス力、データエンジニアリング力」(データサイエンティスト協会プレスリリース 2014.12.10より)とされています。もう少し細かく見ていくと、「データ可視化、機械学習、数学、統計学、計算機科学、コミュニケーション、特定分野の専門知識」が必要と言われています(「Rachel Schutt・Cathy O'Neil(2014)『データサイエンス講義』(瀬戸山雅人ほか訳)O'Reilly Japan, Inc.」より)。
機械学習や統計学については学問として深く研究され、書籍化されていますが、データ可視化(データビジュアライゼーション)については参考となる書籍もあまり多くありません。
さて、いきなりデータの話となりますが、みなさんは下記のようなデータを見たときに、初めにどのようなグラフを作成するでしょうか。
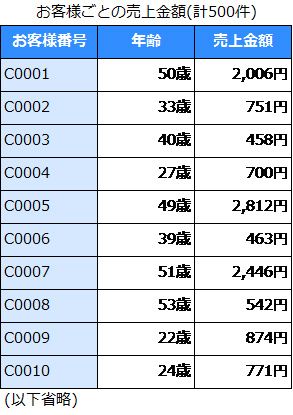
下記のような棒グラフを作成する人も多いと思います。

決して間違ったグラフではありませんし、実際、誰か(お客様や上司など)に分析の基礎統計情報として報告する分には問題ありません。
しかし、データサイエンティストとしてデータを詳細に把握するための分析としては物足りません。また、ビジュアライゼーションにしか出来ないデータの把握方法も多く存在します。この棒グラフ以外のグラフについて2つほど紹介します。
- ※ここからはビジュアライゼーションツールとしてR言語を利用して説明しますが、R言語のプログラムソースは本稿の主旨と外れるため、記述しません。R言語のビジュアライゼーションについて深く知りたい方は、「Winston Chang (2013)『Rグラフィックスクックブック―ggplot2によるグラフ作成のレシピ集』(石井弓美子ほか訳)O'Reilly Japan, Inc.」を参考にして下さい。
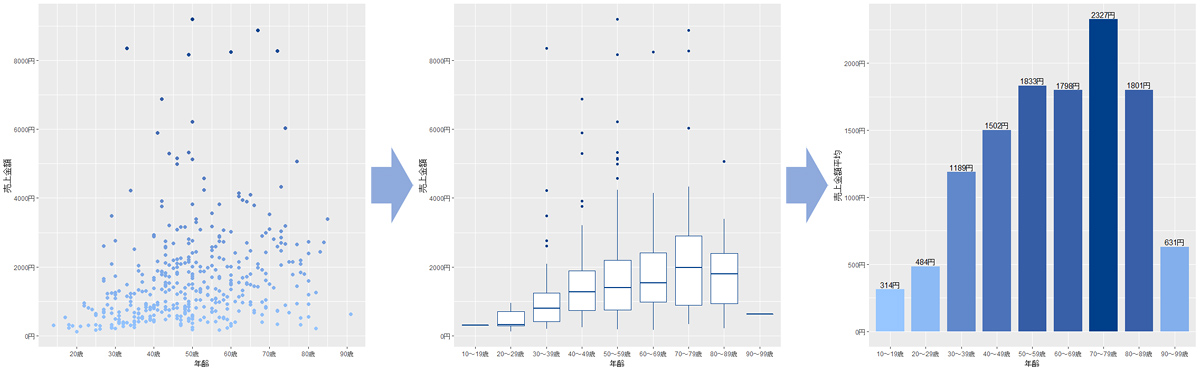
1.散布図
ビジュアライゼーションとして、最も強力で使いやすいグラフは散布図です。「数値データ」×「数値データ」のデータであれば、まずは散布図を作成することをお勧めします。散布図は全てのデータ(1万件以上になると可視化性能は下がりますが)を目視確認することが出来る、強力なグラフです。

どうでしょうか。全てのデータが表示されているため、外れ値や0のデータを確認することが出来ます。また、2つのデータの間に相関があるかなども確認出来ます(相関係数だけを出して満足しないようにしましょう)。データサイエンティストは全てのデータを把握することが求められます。現実にはそんなことは不可能ですが、最低限、最大値や最小値、偏りなどは把握するようにしましょう。
2.箱ひげ図
「カテゴリデータ」×「数値データ」であれば箱ひげ図を選択します。このグラフはエクセルでは作成しづらいため、知名度はあまり高くありませんが、前述した「最大値・最小値・偏り把握」をするためには強力なグラフです。今回は年齢をカテゴリデータ化して箱ひげ図を作成します。

真ん中の線は中央値(50%点)、箱の上下は四分位点(25%点、75%点)、線の上端は最大値、最小値を示しますが、四分位点から箱の長さの1.5倍以上離れたデータは、個別に点で表します。見方には慣れが必要ですが、データの特徴を一目で理解できます。
個人的には、真ん中の線が中央値を表しているのが良いと思います。
日本国民の平均年収は422万円ですが(国税庁による平成28年分民間給与実態統計調査より)、実際の中央値はこれより70万円~80万円低いと言われています。これは数千万円以上の高額所得者まで含めているため、正規分布を大きく乱しているからです。実世界データ(特にマーケティグ領域など)はデータ分布が正規分布となることは少ないため、数値を集計する場合は、平均値よりも中央値のほうが適していると個人的には思っています(現実的には説明のしやすさから平均値を利用することが多いですが)。
3.棒グラフ
報告書を作成する場合は、報告の目的に合っていれば棒グラフでも良いと思います。

ただし、ここまで説明してきた1~3を並べてみると明らかですが、散布図→箱ひげ図→棒グラフの順に情報としての粒度が下がっていくのが分かります(個別値→代表値)。
初めに述べたように、データサイエンティストはデータの特徴を正しく把握し、それを報告したり、機械学習などの後工程に活かしたりする必要があります。私自身、データ分析を始めたばかりの頃はモデル精度や知見発見に多くの時間を費やし、可視化についてはあまり重きを置いていませんでした。このためお客様からすると、とてもわかりづらい分析報告書を作成していたと思います。分析を進めて行くと内容は詳細かつ難解になっていきます。だからこそ分析の前半は幅広い目線で分析する必要があります。正しくデータを把握するために、ビジュアライゼーションを活用し、データを視覚的に捉えられるように心掛けましょう。
参考文献
- Winston Chang (2013)『Rグラフィックスクックブック―ggplot2によるグラフ作成のレシピ集』(石井弓美子ほか訳)O'Reilly Japan, Inc.
- Rachel Schutt・Cathy O'Neil(2014)『データサイエンス講義』(瀬戸山雅人ほか訳)O'Reilly Japan, Inc.
- Hadley Wickham・Garrett Grolemund (2017)『Rではじめるデータサイエンス』(黒川利明ほか訳)O'Reilly Japan, Inc.