
Japan

Japan
2024年5月14日
今回の記事は、SIGNATEの渋滞予測チャレンジコンテスト モデリング部門[1]に参加し、予測精度2位入賞、およびモデリング賞を受賞[2][3]した参加報告です。
NEC アナリティクスコンサルティング統括部では、若手を中心に有志でデータ分析の予測精度コンペティションに参加し、分析力の向上を図っています。
予測精度コンペとは、与えられたタスクに対する予測精度を競うコンペティションです。例えば、過去には、引っ越し業者の需要量予測や賃貸物件の家賃予測といったコンペが開催されました。コンペでは、主催から提供される学習データを用いて機械学習を行います。機械学習で作成したモデルは、学習データとは別に用意されたテストデータの予測に利用され、その予測精度の高さを競い合います。コンペの期間は2~3ヶ月程度のものが多く、期間内であれば複数回予測の提出が可能です。提出した予測精度はリーダーボードと呼ばれるランキング表に掲載され、現在の自分の順位を確認しながら精度向上を目指します。また、コンペには掲示板やフォーラムが用意されるものが多く、そこで他の参加者の解法などを参照できるため、分析力の向上を図ることが可能です。
予測精度コンペは様々なサイトで開催されていますが、最も有名なサイトはKaggle[4]ではないでしょうか。Kaggleは世界最大のコンペサイトであり、全世界から参加者が集まっており、約1,400万人以上の登録者がいます。国内でもSIGNATE[5]やProbSpace[6]といったサイトがあり、Kaggleと異なり、日本語での運営で参加への敷居が低いことから、日本国内で人気があります。今回はSIGNATEで開催されているコンペに若手2人で挑戦しました。
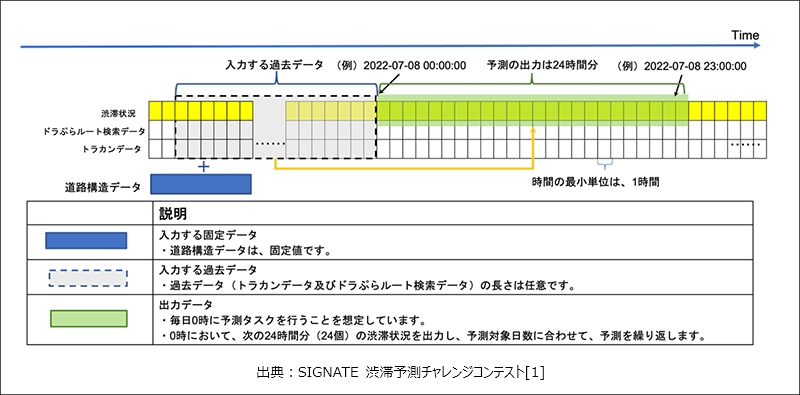
今回参加したコンペは、NEXCO東日本(東日本高速道路株式会社)様と東京大学大学院情報学環様が2023年1~3月の期間で開催した「渋滞予測チャレンジコンテスト ~高速料金・ルート検索データを活用した高速道路の渋滞予測高度化への挑戦~」です。予測タスクやデータの内容等は以下の通りです。
今回コンペの規約の観点でデータや分析方法の詳細を記載することが出来ないのですが、ポイントとしてはモデル設計に注力しました。今回のタスクの特徴として、区間ごとに、そして、1時間ごとに予測を算出する必要があるため、目的変数の種類が大量にあります。
このように目的変数が大量にあるケースでは、モデルをいくつ用意するか、複数用意した場合には個々のモデルの関連性をどのようにするか、といった点を検討する必要があります。どの選択肢が有効なのか入念に検討を重ね、複数の選択肢を実装し精度検証を繰り返しました。
データ観察や様々なアルゴリズムを検討・吟味した結果、精度賞で2位を獲得しました。また、精度賞上位3チームについては、NEXCO東日本様の本社にて分析のポイントやアルゴリズムについてプレゼンを行うのですが、総合的に最も優れたモデルを開発したチームに与えられるモデリング賞を受賞することが出来ました!
今回のタスクでは複数のモデルや分析手法を試す必要があり、複数モデルの実装、統一的な精度比較を実施でき、実装力の向上ができました。
また、分析コンペの一般論として、コンペでは予測精度のみを競うため、精度向上のため、様々な分析手法を試したり、様々な特徴量設計を試したりします。また、リーダーボードで現在の自分の順位を確認できるため、リーダーボードの結果と自分で用意した評価方法での結果を比較して、評価方法を見直したり、コンペでの評価の特徴を把握したりしています。実際の分析業務とは異なる観点が必要なことも刺激になっています。
さらに、今回のタスクでは高速道路のデータを扱い、筆者の業務では扱ったことのないデータを扱うことができました。このように、コンペで業務とは全く異なるデータや、興味があるけどまだ触れたことのないデータを分析でき、とても良い経験になっています。加えて、今回のコンペの経験を生かして、高速道路と関係のある分析を業務でもやってみたいと思いました。
NEC アナリティクスコンサルティング統括部では、今回のようなコンペへの積極的な参加やその部内共有を通して分析力の向上を図っています。今回の結果の共有で、「受賞うらやましい!」「自分も参加してみたい!」などという声も聞き、部内のコンペへのモチベーションも向上したのではないかと感じています。
今後もコンペへの成果報告をデータサイエンティストブログに掲載したいと考えています。
執筆者プロフィール

田中 智規 (たなか ともき)
アナリティクスコンサルティング統括部
2019年4月、日本電気株式会社入社。製造業、建設業のお客様を中心にデータ活用サービスに従事。予測分析の業務から、「意図学習」を含む自社独自技術の活用やLLMの実案件適用などにもチャレンジ中。
執筆者プロフィール

有里 悠希 (ありさと ゆうき)
アナリティクスコンサルティング統括部
2019年4月、日本電気株式会社入社。製造業、官公庁のお客様を中心にデータ活用サービスに従事。AIによる飲料開発である「人生醸造craft」やペットの活動を分析する「waneco talk」といった新しいAI活用にも挑戦。




 https://signate.jp/competitions/932
https://signate.jp/competitions/932 https://www.e-nexco.co.jp/pressroom/cms_assets/pressroom/2023/07/26a/pdf.pdf
https://www.e-nexco.co.jp/pressroom/cms_assets/pressroom/2023/07/26a/pdf.pdf